Java中的NIO学习笔记
流与块的比较原来的 I/O 库(在 java.io.*中) 与 NIO 最重要的区别是数据打包和传输的方式。正如前面提到的,原来的 I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。面向流 的 I/O 系统一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。
流与块的比较
原来的 I/O 库(在 java.io.*中) 与 NIO 最重要的区别是数据打包和传输的方式。正如前面提到的,原来的 I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
面向流 的 I/O 系统一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。为流式数据创建过滤器非常容易。链接几个过滤器,以便每个过滤器只负责单个复杂处理机制的一部分,这样也是相对简单的。不利的一面是,面向流的 I/O 通常相当慢。
一个 面向块 的 I/O 系统以块的形式处理数据。每一个操作都在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
核心组成
通道和缓冲区是 NIO 中的核心对象,几乎在每一个 I/O 操作中都要使用它们。通道是对原 I/O 包中的流的模拟。到任何目的地(或来自任何地方)的所有数据都必须通过一个 Channel 对象。一个 Buffer 实质上是一个容器对象。发送给一个通道的所有对象都必须首先放到缓冲区中;同样地,从通道中读取的任何数据都要读到缓冲区中。
缓冲区(Buffer)
Buffer 是一个对象, 它包含一些要写入或者刚读出的数据。 在 NIO 中加入 Buffer 对象,体现了新库与原 I/O 的一个重要区别。在面向流的 I/O 中,您将数据直接写入或者将数据直接读到 Stream 对象中。
在 NIO 库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的。在写入数据时,它是写入到缓冲区中的。任何时候访问 NIO 中的数据,您都是将它放到缓冲区中。
缓冲区实质上是一个数组。通常它是一个字节数组,但是也可以使用其他种类的数组。但是一个缓冲区不 仅仅 是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
缓冲区类型
最常用的缓冲区类型是 ByteBuffer。一个 ByteBuffer 可以在其底层字节数组上进行 get/set 操作(即字节的获取和设置)。
ByteBuffer 不是 NIO 中唯一的缓冲区类型。对于每一种基本 Java 类型都有一种缓冲区类型:
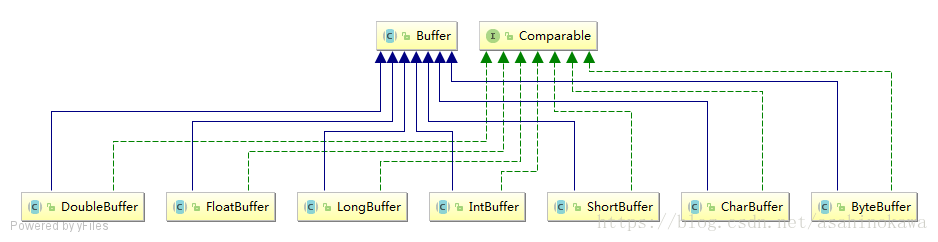
每一个 Buffer 类都是 Buffer 接口的一个实例。 除了 ByteBuffer,每一个 Buffer 类都有完全一样的操作,只是它们所处理的数据类型不一样。因为大多数标准 I/O 操作都使用 ByteBuffer,所以它具有所有共享的缓冲区操作以及一些特有的操作。
通道(Channel)
一种可以将数据读取/写入到缓冲区中的方式
所有数据都通过 Buffer 对象来处理。不会将字节直接写入通道中,相反,将数据写入包含一个或者多个字节的缓冲区。同样,不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。
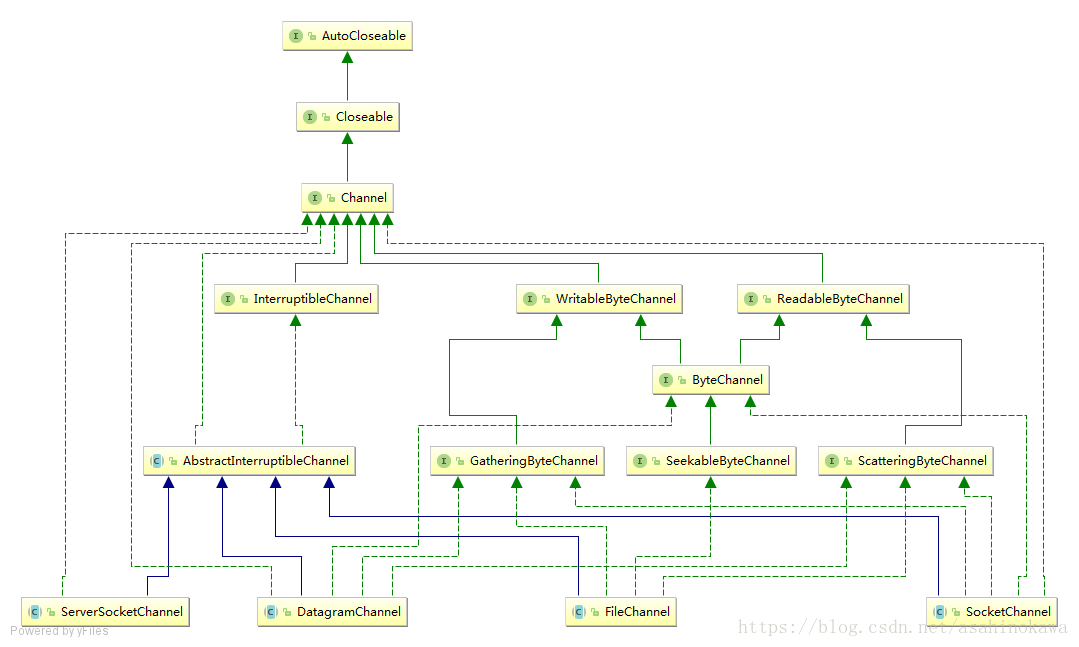
通道与流的不同之处在于通道是双向的。而流只是在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类), 而 通道 可以用于读、写或者同时用于读写。
最重要的通道的实现有:
选择器(Selector)
Selector允许单线程处理多个 Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。例如,在一个聊天服务器中。
这是在一个单线程中使用一个Selector处理3个Channel的图示:
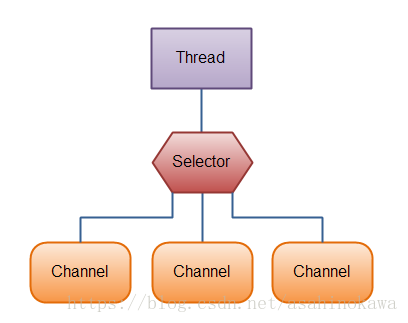
要使用Selector,得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件的例子有如新连接进来,数据接收等。
示例代码
// 从RandomAccessFile得到的channel可读可写
RandomAccessFile raf = new RandomAccessFile("C:\\Users\\D22433\\Desktop\\DailyRecord.md", "rw");
// 获取channel
FileChannel fileChannel = raf.getChannel();
// 得到一个ByteBuffer的子类HeapByteBuffer
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 从文件读数据
while(fileChannel.read(buffer) != -1) {
System.out.println(new String(buffer.array()));
// 重置buffer
buffer.clear();
}
// 写数据到文件
buffer.put(("\n"+new Date().toString()+": Hello\n").getBytes());
// 让buffer里面的数据可以被channel写入文件中
buffer.flip();
// 将缓冲区的内容写入文件
fileChannel.write(buffer);
解析可能存在疑惑的地方有两处,一个是flip(),另外一个是clear()。要分析这两个函数,就需要先了解Buffer的内部原理。
缓冲区实际上就是美化了的数组,在从通道读取时,可以理解将所读取的数据放到底层的数组中。
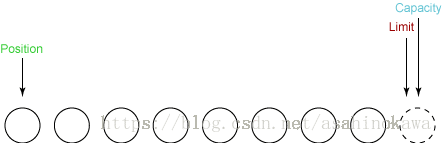
在Buffer中有三个变量:
position:跟踪已经写了多少数据。更准确地说,它指定了下一个字节将放到数组的哪一个元素中limit:表明还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。capacity:可以储存在缓冲区中的最大数据容量。实际上,它指定了底层数组的大小 ― 或者至少是指定了准许我们使用的底层数组的容量。
其中三个变量恒成立的关系为(可从Buffer源码中找到): $$mark \leq position \leq limit \leq capacity$$
状态图
①初始状态
②向缓冲区中写入数据
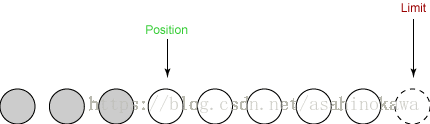
③flip()
- 它将 limit 设置为当前 position。
- 它将 position 设置为 0。
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
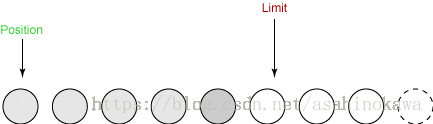
④从缓冲区读数据(写出)
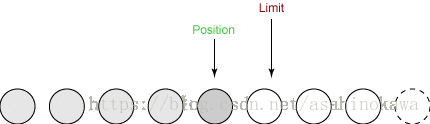
⑤clear()重置缓冲区
- 它将 limit 设置为与 capacity 相同。
- 它设置 position 为 0。
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
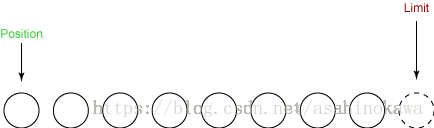
⑥其实还有一个compact()函数,当从缓冲区里面读取数据时,并没有读完,这是又要写入数据到缓冲区中,且不想覆盖掉未读取完的数据,此时就可以考虑使用此函数。
public final int remaining() {
// 处于读取模式时,将表示未读取的数据个数
return limit - position;
}
public ByteBuffer compact() {
// 将未读取的数据,移到hb的开始处
System.arraycopy(hb, ix(position()), hb, ix(0), remaining());
// 调整当前数据位置
position(remaining());
// 设置成capacity,以用来接收数据
limit(capacity());
discardMark();
return this;
}
聚集(gather)与分散(scatter)
分散(scatter) 从Channel中读取是指在读操作时将读取的数据写入多个buffer中。因此,Channel将从Channel中读取的数据“分散(scatter)”到多个Buffer中。 聚集(gather) 写入Channel是指在写操作时将多个buffer的数据写入同一个Channel,因此,Channel 将多个Buffer中的数据“聚集(gather)”后发送到Channel。 scatter / gather经常用于需要将传输的数据分开处理的场合,例如传输一个由消息头和消息体组成的消息,你可能会将消息体和消息头分散到不同的buffer中,这样你可以方便的处理消息头和消息体。
Scattering Reads
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
ByteBuffer[] bufferArray = { header, body };
channel.read(bufferArray);
注意buffer首先被插入到数组,然后再将数组作为channel.read() 的输入参数。read()方法按照buffer在数组中的顺序将从channel中读取的数据写入到buffer,当一个buffer被写满后,channel紧接着向另一个buffer中写。 Scattering Reads在移动下一个buffer前,必须填满当前的buffer,这也意味着它不适用于动态消息(译者注:消息大小不固定)。换句话说,如果存在消息头和消息体,消息头必须完成填充(例如 128byte),Scattering Reads才能正常工作。
Gathering Writes
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
//write data into buffers
ByteBuffer[] bufferArray = { header, body };
channel.write(bufferArray);
buffers数组是write()方法的入参,write()方法会按照buffer在数组中的顺序,将数据写入到channel,注意只有position和limit之间的数据才会被写入。因此,如果一个buffer的容量为128byte,但是仅仅包含58byte的数据,那么这58byte的数据将被写入到channel中。因此与Scattering Reads相反,Gathering Writes能较好的处理动态消息。
关于Selector
此段代码来自IBM的那篇文章的,可以参考来理解selector。
public class MultiPortEcho {
private int ports[];
private ByteBuffer echoBuffer = ByteBuffer.allocate(1024);
public MultiPortEcho(int ports[]) throws IOException {
this.ports = ports;
go();
}
private void go() throws IOException {
// Create a new selector
Selector selector = Selector.open();
// Open a listener on each port, and register each one
// with the selector
for (int i = 0; i < ports.length; ++i) {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
ServerSocket ss = ssc.socket();
InetSocketAddress address = new InetSocketAddress(ports[i]);
ss.bind(address);
SelectionKey key = ssc.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("Going to listen on " + ports[i]);
}
while (true) {
int num = selector.select();
Set selectedKeys = selector.selectedKeys();
Iterator it = selectedKeys.iterator();
while (it.hasNext()) {
SelectionKey key = (SelectionKey) it.next();
if (
(key.readyOps() & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT
) {
// Accept the new connection
ServerSocketChannel ssc = (ServerSocketChannel) key.channel();
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
// Add the new connection to the selector
SelectionKey newKey = sc.register(selector, SelectionKey.OP_READ);
it.remove();
System.out.println("Got connection from " + sc);
} else if (
(key.readyOps() & SelectionKey.OP_READ) == SelectionKey.OP_READ
) {
// Read the data
SocketChannel sc = (SocketChannel) key.channel();
// Echo data
int bytesEchoed = 0;
while (true) {
echoBuffer.clear();
int r = sc.read(echoBuffer);
if (r <= 0) {
break;
}
echoBuffer.flip();
sc.write(echoBuffer);
bytesEchoed += r;
}
System.out.println("Echoed " + bytesEchoed + " from " + sc);
it.remove();
}
}
//System.out.println( "going to clear" );
// selectedKeys.clear();
//System.out.println( "cleared" );
}
}
public static void main(String args[]) throws Exception {
if (args.length <= 0) {
System.err.println("Usage: java MultiPortEcho port [port port ...]");
System.exit(1);
}
int ports[] = new int[args.length];
for (int i = 0; i < args.length; ++i) {
ports[i] = Integer.parseInt(args[i]);
}
new MultiPortEcho(ports);
}
}
参考: https://www.ibm.com/developerworks/cn/education/java/j-nio/j-nio.htmlhttp://ifeve.com/overview/
