3 | Spinnaker 如何执行 pipeline
本篇文章记录以发布单的形式启动的一个流水线的执行过程,并对相关敏感信息做了删除,但不影响对整体流程的介绍。通过 POST 调用 gate 服务的 pipelines/v2/{application}/{pipeline}@POST("pipelines/v2/{application}/{
本篇文章记录以发布单的形式启动的一个流水线的执行过程,并对相关敏感信息做了删除,但不影响对整体流程的介绍。
通过 POST 调用 gate 服务的 pipelines/v2/{application}/{pipeline}
@POST("pipelines/v2/{application}/{pipeline}")
Call<Map<String, Object>> postPipeline(@Path("application") String application,
@Path("pipeline") String pipeline,
@Body TaskPipeline taskPipeline);
进入 gate
gate
请求:/v2/{application}/{pipelineNameOrId:.+}
位置:gate-web/src/main/groovy/com/netflix/spinnaker/gate/controllers/PipelineController.groovy
请求进入 gate 之后,会先校验当前用户是否有此流水线的执行权限,然后调用 echo 触发流水线。
@POST('/')
String postEvent(@Body Map event)
此时的参数 eventMap 为:
{
"content": {
"application": "artifacturlteam1",
"pipelineNameOrId": "ccbae2c9-ba68-43f3-87ba-669b1bb27831",
"trigger": {
"buildNumber": "0",
"type": "manual",
"dryRun": false,
"parameters": {},
"user": "vskycorpltd",
"artifacts": [
{
"artifactAccount": "generic-repo::1",
"customKind": false,
"id": "94141c3b-1f0f-4674-99e1-cb138905ac25",
"name": "vskycorpltdcorp-generic.pkg.vskycorpltd.com/vsky/generic-repo/abc/efg.txt",
"parentType": "generic",
"pkgId": 2,
"projectId": 1,
"projectName": "vsky",
"reference": "",
"repoName": "generic-repo",
"type": "vskycorpltd_artifact/generic",
"uriName": "vsky"
}
],
"customName": "20201016-artifacturl-p1",
"customDescription": "",
"projectUrlName": "vsky",
"vskycorpltdNickname": "vskycorpltd",
"eventId": "2796229f-fbea-4da8-a8af-fd3de334f765",
"executionId": "01EN7GSM1KA2XHV9SX956YGKCD"
},
"user": "vskycorpltd"
},
"details": {
"type": "manual"
}
}
进入 echo
echo
位置:echo-web/src/main/java/com/netflix/spinnaker/echo/history/HistoryController.java
在 echo 中,上面的参数被转换成一个 echoEvent,然后将此事件,交给事件监听者来处理,
@RequestMapping(value = "/", method = RequestMethod.POST)
public void saveHistory(@RequestBody Event event) {
propagator.processEvent(event);
}
public void processEvent(Event event) {
Observable.from(listeners)
.map(
listener ->
AuthenticatedRequest.propagate(
() -> {
listener.processEvent(event);
return null;
}))
.observeOn(scheduler)
.subscribe(
callable -> {
try {
callable.call();
} catch (Exception e) {
log.error("failed processing event: {}", event.content, e);
}
});
}
listeners 来在容器中所有的 EchoEventListener bean。
@Bean
public EventPropagator propagator() {
EventPropagator instance = new EventPropagator();
for (EchoEventListener e : context.getBeansOfType(EchoEventListener.class).values()) {
instance.addListener(e);
}
return instance;
}
此处有 5 个监听者,他们的继承关系如下(观察者模式):
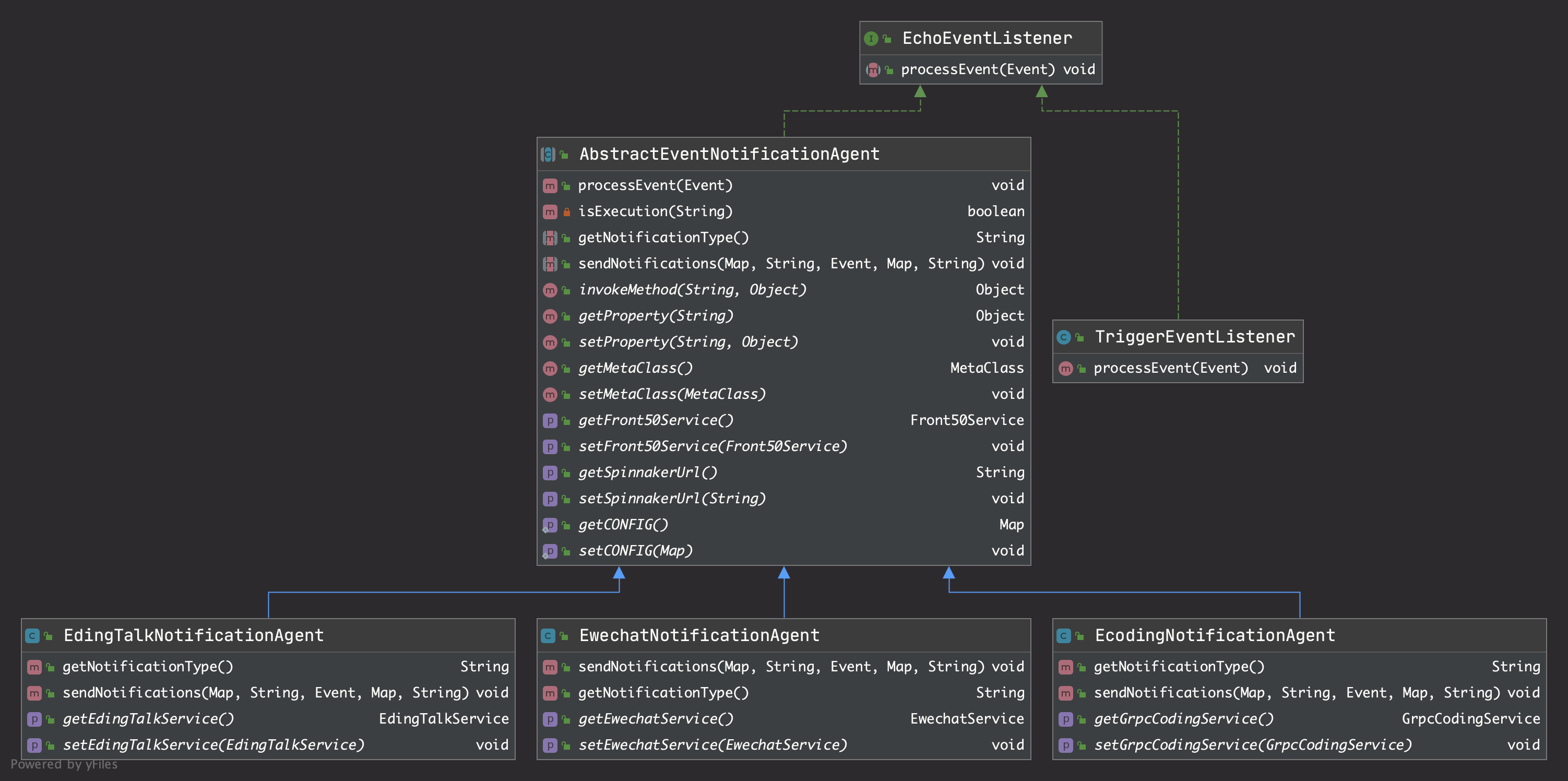
此处仅关注 TriggerEventListener,它将是触发流水线的入口。随后 TriggerEventListener 会将事件交给 所有注册进来的 triggerMonitors 处理。
public void processEvent(Event event) {
for (TriggerMonitor triggerMonitor : triggerMonitors) {
triggerMonitor.processEvent(event);
}
}
每个 TriggerMonitor 包含一个 TriggerEventHandler,并且在初始化 TriggerEventListener 时,从容器中将所有的 TriggerEventHandler 都捞出来,用 TriggerMonitor 包裹一层,放入 triggerMonitors 中。
public TriggerEventListener(
@NonNull PipelineCache pipelineCache,
@NonNull PipelineInitiator pipelineInitiator,
@NonNull Registry registry,
@NonNull PipelinePostProcessorHandler pipelinePostProcessorHandler,
@NonNull List<TriggerEventHandler<?>> eventHandlers) {
this.triggerMonitors =
eventHandlers.stream()
.map(
e ->
new TriggerMonitor<>(
pipelineCache,
pipelineInitiator,
registry,
pipelinePostProcessorHandler,
e))
.collect(Collectors.toList());
}
但是并不是所有的 triggerMonitor 都处理这个事件,他们只负责处理各自能处理的事件。
public void processEvent(Event event) {
validateEvent(event);
if (eventHandler.handleEventType(event.getDetails().getType())) {
recordMetrics();
T triggerEvent = eventHandler.convertEvent(event);
triggerMatchingPipelines(triggerEvent);
}
}
因此有若干个 TriggerEventHandler ,他们分别对应若干触发方式,如下:
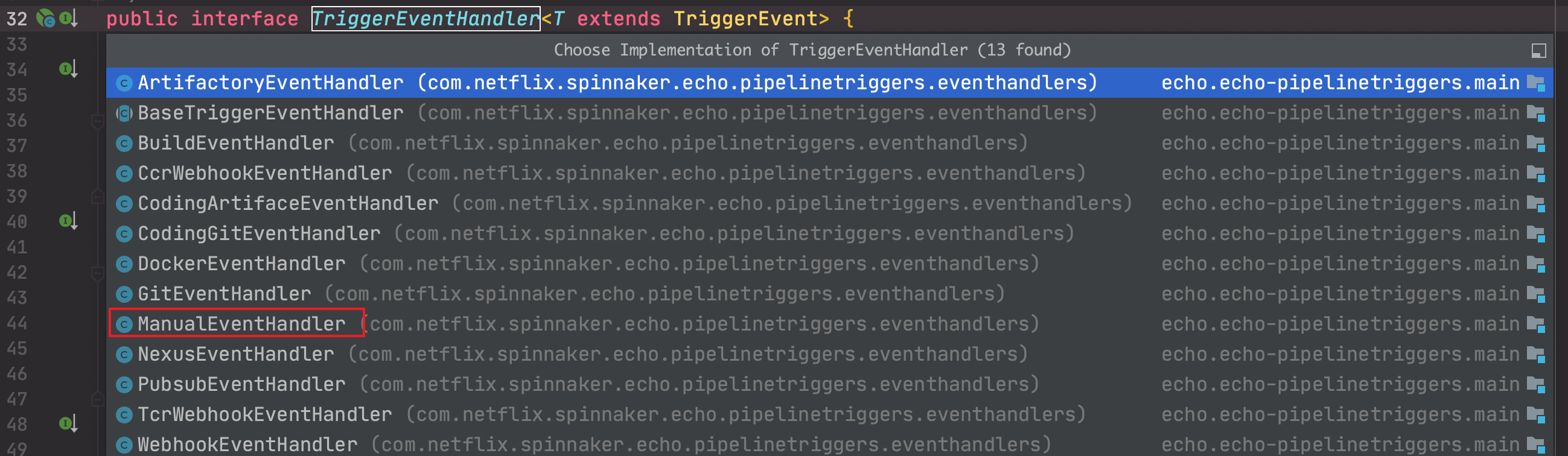
此处我们是以手动的方式启动的,在 Event 的 detail 中,type 记录为 manual。
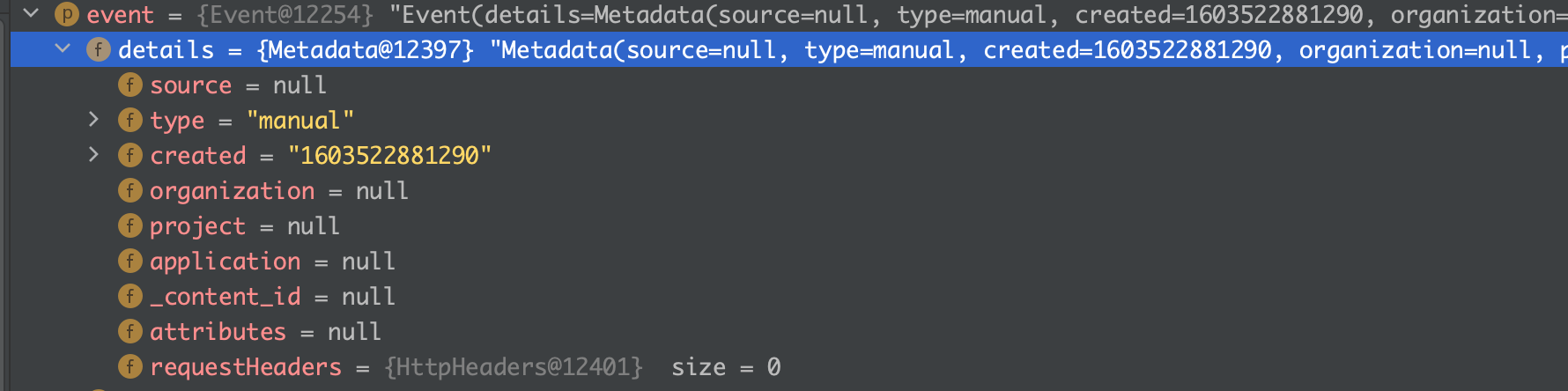
并且判断一个 TriggerEventHandler 能否处理某个事件的方式为:子类覆盖 handleEventType() 方法,并将相应能处理的事件的类型与当前 event.detail.type 对比,以 DockerEventHandler 为例:
@Override
public boolean handleEventType(String eventType) {
return eventType.equalsIgnoreCase(DockerEvent.TYPE);
}
public class DockerEvent extends TriggerEvent {
public static final String TYPE = "DOCKER";
// ...
}
因此,我们最终的入口便是 ManualEventHandler 。开始触发流水线。最终在 echo PipelineInitiator 的
triggerPipelineImpl() 方法中,通过 triggerWithRetries() 实现对 orca 的 HTTP 调用。
orca
接口:/orchestrate
位置:OperationsController
经过一番折腾后,边开始执行 pipeline,并返回一个 id 给到 echo。其间有几个比较重要的步骤:
- 执行
parseAndValidatePipeline(pipeline),解决制品问题。最终调用的是:ArtifactResolver.resolveArtifacts()。 - 进行了一次
contextParameterProcessor.process(),对 pipeline 中的表达式进行计算。 - 将 pipeline 信息转化成
Execution,然后再将其转化成一个StartExecution后,存入到一个 Queue 里面。
override fun start(execution: Execution) = queue.push(StartExecution(execution))
@JsonTypeName("startExecution")
data class StartExecution(
override val executionType: ExecutionType,
override val executionId: String,
override val application: String
) : Message(), ExecutionLevel {
constructor(source: Execution) :
this(source.type, source.id, source.application)
}
其中,StartExecution 的值如下:
{
"kind": "startExecution",
"attributes": [],
"ackTimeoutMs": null,
"executionType": "PIPELINE",
"executionId": "01ENCS32B8B8AP83FAHYTCCKHN",
"application": "asgteam1"
}
发布&获取事件
Queue 的实现为 RedisQueue,它 push 的代码逻辑如下:
override fun push(message: Message, delay: TemporalAmount) {
pool.resource.use { redis ->
redis.firstFingerprint(queueKey, message.fingerprint()).also { fingerprint ->
if (fingerprint != null) {
// ...
redis.zadd(queueKey, score(delay), fingerprint, zAddParams().xx())
fire(MessageDuplicate(message))
} else {
redis.queueMessage(message, delay)
fire(MessagePushed(message))
}
}
}
}
先将 message 即 StartExecution 的摘要信息存入到一个有序集合中,集合的键为 orca.task.queue.queue,可以查看 redis 中相应的值,结果如下:

然后通过 fire 函数,发布一个事件,这里应该是利用了 spring 的事件发布机制。
@Bean
fun queueEventPublisher(
applicationEventPublisher: ApplicationEventPublisher
) = object : EventPublisher {
override fun publishEvent(event: QueueEvent) {
applicationEventPublisher.publishEvent(event)
}
}
ApplicationEventPublisher 是 spring-context 包下的一个接口。它是一个AnnotationConfigServletWebServerApplicationContext 的实例,且继承自AbstractApplicationContext ,它有一个 publishEvent() 方法。
获取消息
位置:com/netflix/spinnaker/q/QueueProcessor.kt
可以参考:https://spinnaker.io/guides/developer/service-overviews/orca/
简而言之:不同的消息类型,对应不同的 handler。例如:StartExecution 消息,对应 StartExecutionHandler。
StartExecutionHandler
initialStages.forEach { queue.push(StartStage(it)) }
fun Execution.initialStages() =
stages
.filter { it.isInitial() }
fun Stage.isInitial(): Boolean =
requisiteStageRefIds.isEmpty()
往 Queue 中塞若干个 StartStage,这些 Stage 必须不依赖其他 stage (配置除外),这里是并行执行多个 Stage 的入口。
StartStageHandler
stage.plan() 函数执行逻辑:
private fun Stage.plan() {
builder().let { builder ->
// if we have a top level stage, ensure that context expressions are processed
val mergedStage = if (this.parentStageId == null) this.withMergedContext() else this
builder.addContextFlags(mergedStage)
builder.buildTasks(mergedStage)
builder.buildBeforeStages(mergedStage) { it: Stage ->
repository.addStage(it.withMergedContext())
}
}
}
- 根据 stage 的定义将 Task 加入到 stage 的 tasks 列表中。
fun StageDefinitionBuilder.buildTasks(stage: Stage) {
buildTaskGraph(stage)
.listIterator()
.forEachWithMetadata { processTaskNode(stage, it) }
}
default @Nonnull TaskGraph buildTaskGraph(@Nonnull Stage stage) {
Builder graphBuilder = Builder(FULL);
taskGraph(stage, graphBuilder);
return graphBuilder.build();
}
// 在 Stage 中自定义的 taskGraph()
@Override
void taskGraph(Stage stage, TaskNode.Builder builder) {
if (isTopLevelStage(stage)) {
builder
.withTask("completeParallel", CompleteParallelBakeTask)
} else {
builder
.withTask("createBake", CreateBakeTask)
.withTask("monitorBake", MonitorBakeTask)
.withTask("completedBake", CompletedBakeTask)
.withTask("bindProducedArtifacts", BindProducedArtifactsTask)
}
}
withTask() 方法将会将 taskName,taskImp类,封装到 TaskDefinition 中,并保存在 builder 的 graph 中。
public Builder withTask(
String name, Class<? extends com.netflix.spinnaker.orca.Task> implementingClass) {
graph.add(new TaskDefinition(name, implementingClass));
return this;
}
然后通过 processTaskNode() 将所有的 task 保存到 stage 的 tasks 中。
private fun processTaskNode(
stage: Stage,
element: IteratorElement<TaskNode>,
isSubGraph: Boolean = false
) {
element.apply {
when (value) {
is TaskDefinition -> {
val task = Task()
task.id = (stage.tasks.size + 1).toString()
task.name = value.name
task.implementingClass = value.implementingClass.name
if (isSubGraph) {
task.isLoopStart = isFirst
task.isLoopEnd = isLast
} else {
task.isStageStart = isFirst
task.isStageEnd = isLast
}
stage.tasks.add(task)
}
is TaskGraph -> {
// 递归执行...
}
}
}
}
- 让一个 Stage 包含两个 Stage
简单说就是在一个 Bake 阶段,似乎产生了两个 Bake,并且每个 Bake 的 task 还不一样,但他们都在一个 Bake 阶段里面,如下:
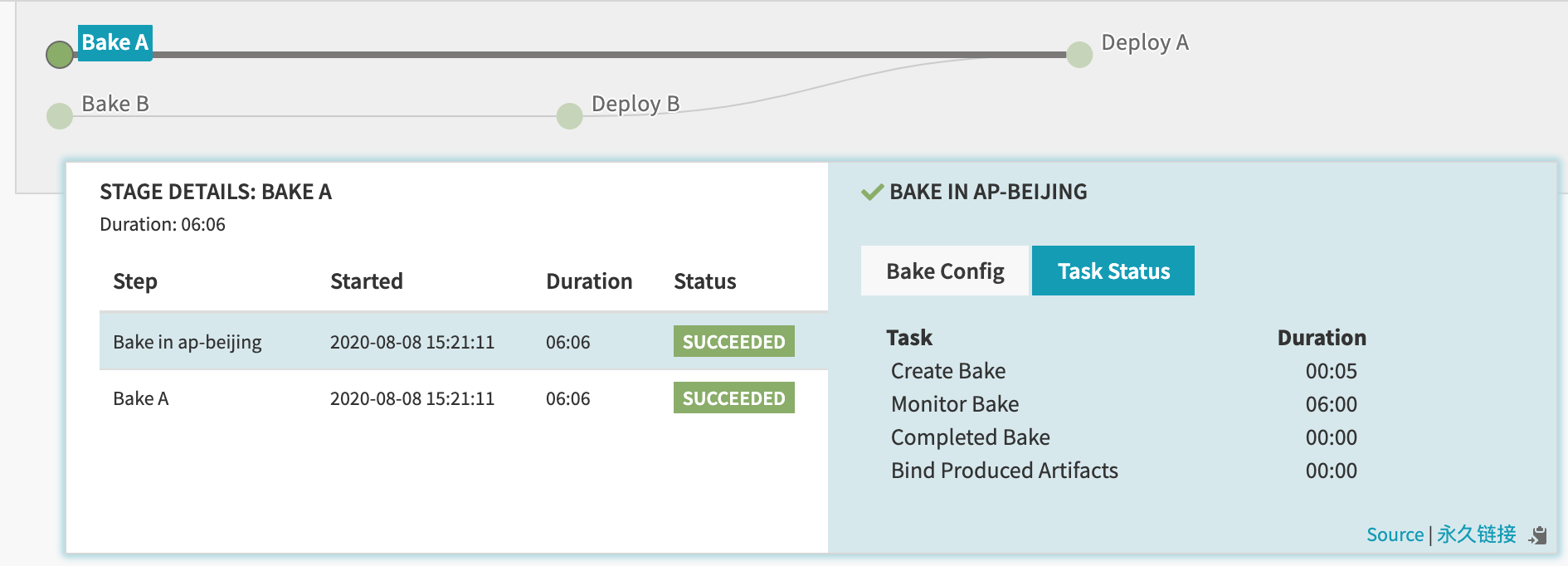
它的实现只需要在自定义 Stage 中实现 buildBeforeStage() 方法,并在这个方法中,在 graph 中,添加一个新的 Stage,它的本质是为 Bake A 阶段,添加了一个前置阶段 Bake in ap-beijing。
@Override
void beforeStages(@Nonnull Stage parent, @Nonnull StageGraphBuilder graph) {
if (isTopLevelStage(parent)) {
parallelContexts(parent)
.collect({ context ->
newStage(parent.execution, type, "Bake in ${context.region}", context, parent, STAGE_BEFORE)
})
.forEach({Stage s -> graph.add(s) })
}
}
在搞定整个 Stage 的构造之后,开始 stage.start(),此处,会将上面创建的两个 Stage 分开运行。
private fun Stage.start() {
val beforeStages = firstBeforeStages()
if (beforeStages.isEmpty()) {
val task = firstTask()
if (task == null) {
// TODO: after stages are no longer planned at this point. We could skip this
val afterStages = firstAfterStages()
if (afterStages.isEmpty()) {
queue.push(CompleteStage(this))
} else {
afterStages.forEach {
queue.push(StartStage(it))
}
}
} else {
queue.push(StartTask(this, task.id))
}
} else {
beforeStages.forEach {
queue.push(StartStage(it))
}
}
}
第一步的 val beforeStages = firstBeforeStages() 会先获取到创建的 Bake in ap-beijing 阶段,并通过 queue.push(StartStage(it)) 先执行 Bake in ap-beijing 。所以,只执行完 queue.push(StartStage(it)) ,代码的处理逻辑,又会进入 StartStageHandler中,如下:
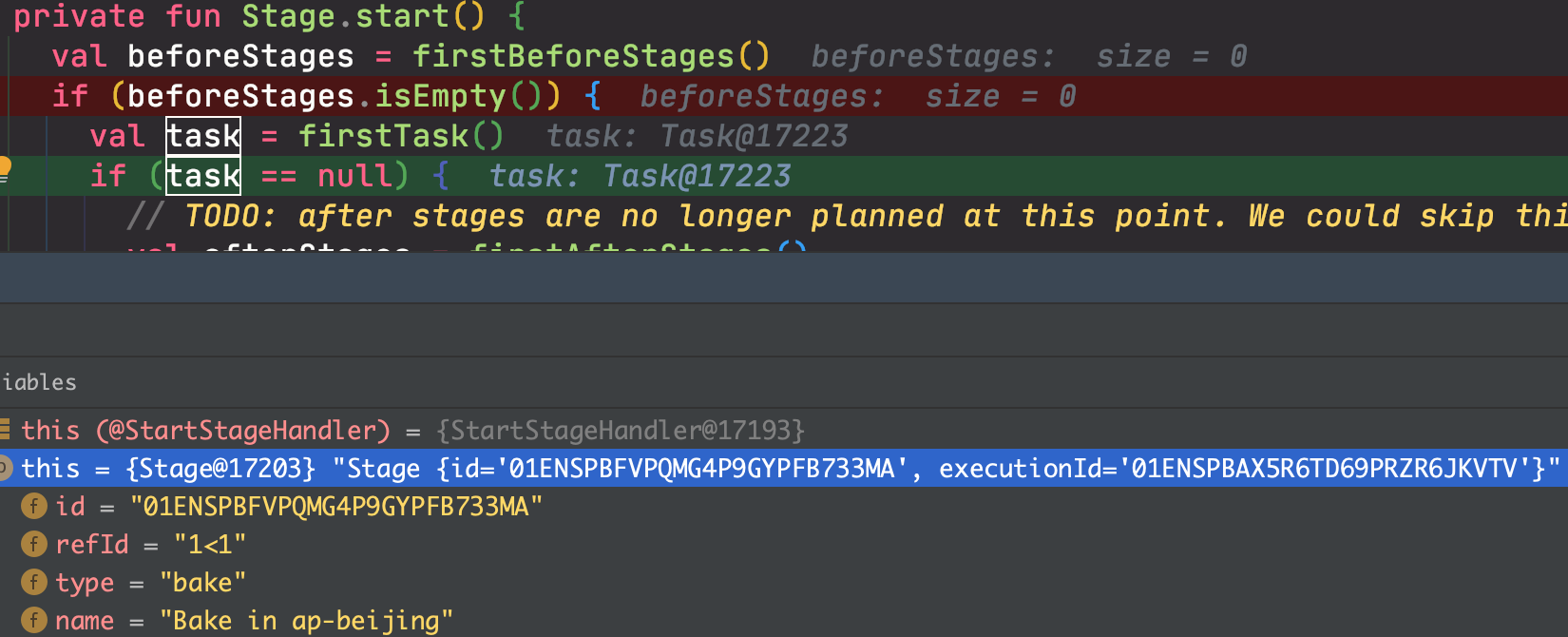
接着通过 queue.push(StartTask(this, task.id)),开始执行第一个 Task,即 createBake。
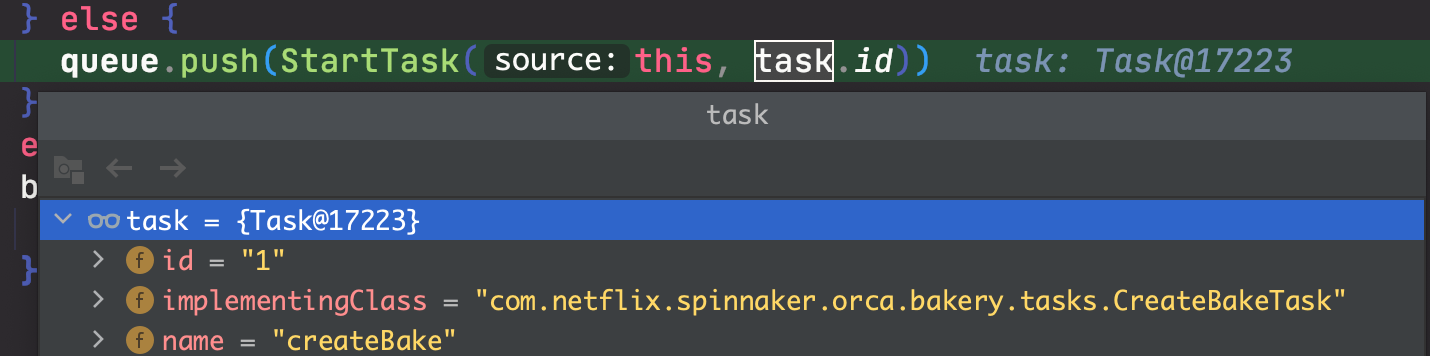
StartTaskHandler
message.withTask { stage, task ->
task.status = RUNNING
task.startTime = clock.millis()
val mergedContextStage = stage.withMergedContext()
repository.storeStage(mergedContextStage)
queue.push(RunTask(message, task.id, task.type))
publisher.publishEvent(TaskStarted(this, mergedContextStage, task))
}
这里记录了 task 的开始时间、并保存到数据库中,同时通过 queue.push(RunTask(message, task.id, task.type)) 开启 task。
这里的 message.withTask 里面的套了好几层逻辑,与后续的 RunTask 有类似之处。
RunTaskHandler
在 handle() 方法中,通过解析,最终得到了实际的 task,即 CreateBakeTask。

CreateBakeTask
在此 Task 中,主要是对 bake 所需参数进行拼凑,主要步骤如下:
根据 account 获取 secret_id 和 secret_key。
根据 pipeline 中的设置,整理出 packer 使用的配置。
调用 rosco,并等待请求返回。
返回 task 执行成功。

task 执行完成
当 CreateBakeTask 返回的状态为成功时,后续会触发 CompleteTask 事件,也就是对应 CompleteTaskHandler。
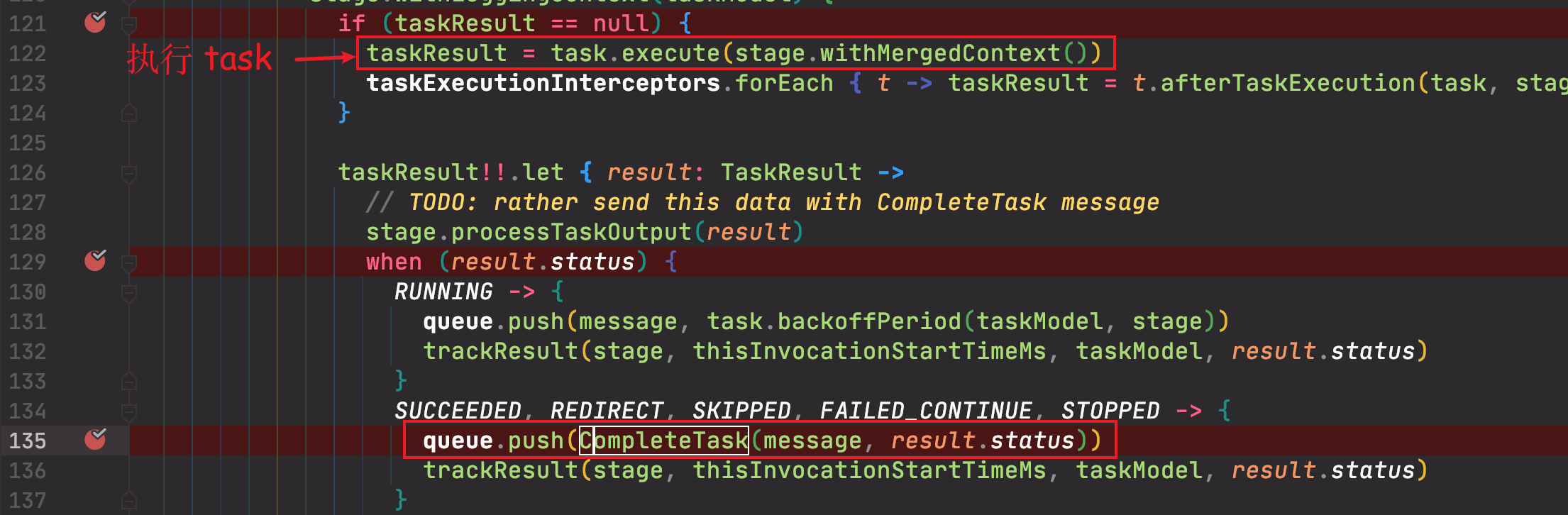
CompleteTaskHandler
当一个 task 结束时,会判断 task 所属 stage 是否结束、是否已被手动跳过、已经进行触发下个 task。
mergedContextStage.nextTask(task).let {
if (it == null) {
queue.push(NoDownstreamTasks(message))
} else {
queue.push(StartTask(message, it.id))
}
}
其中查找下一个 task 的逻辑只是将下标 +1
fun Stage.nextTask(task: Task): Task? =
if (task.isStageEnd) {
null
} else {
val index = tasks.indexOf(task)
tasks[index + 1]
}
接着,便开始了一个新的循环,分别开始 MonitorBakeTask、CompletedBakeTask、BindProducedArtifactsTask。每个 task 都会像 CreateBakeTask 一样,经历下面的 3 个阶段:
- StartTaskHandler
- RunTaskHandler
- CompleteTaskHandler
当最后一个 task 执行完了之后,仍然会到达 CompleteTaskHandler 的 handle() 方法,此时会触发 CompleteStage。
CompleteStageHandler
主要逻辑分两个,一个是对 afterStage 的处理,一个是对 nextStage 的处理。
- 与前面的 beforeStage 对应,还有一个 afterStage,逻辑应该与 beforeStage 类似,当执行完一个 stage 之后,再执行它的 afterStage。
stage.startNext()
获取接下来的 stages 的逻辑:并发执行所有接下来的 stage
fun Stage.startNext() {
execution.let { execution ->
val downstreamStages = downstreamStages()
val phase = syntheticStageOwner
if (downstreamStages.isNotEmpty()) {
downstreamStages.forEach {
queue.push(StartStage(it))
}
} else if (phase != null) {
queue.ensure(ContinueParentStage(parent(), phase), Duration.ZERO)
} else {
queue.push(CompleteExecution(execution))
}
}
}
如何确定接下来的 stages
根据当前 stage 的 refId,到 pipeline 中去遍历所有的 stage,只要该 stage 的 requisiteStageRefIds 里面有当前 stage 的 refId,那么它就将要被执行。
@JsonIgnore
public List<Stage> downstreamStages() {
return getExecution().getStages().stream()
.filter(it -> it.getRequisiteStageRefIds().contains(getRefId()))
.collect(toList());
}
