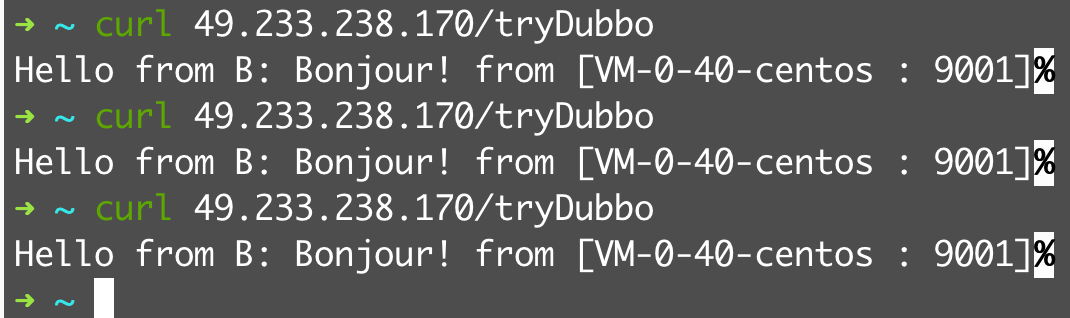
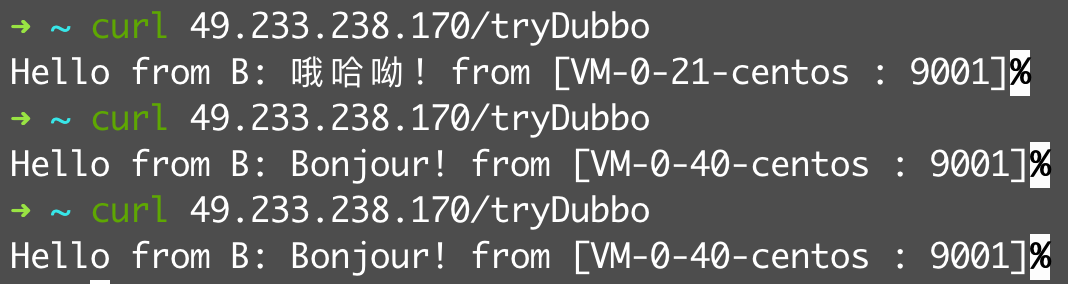
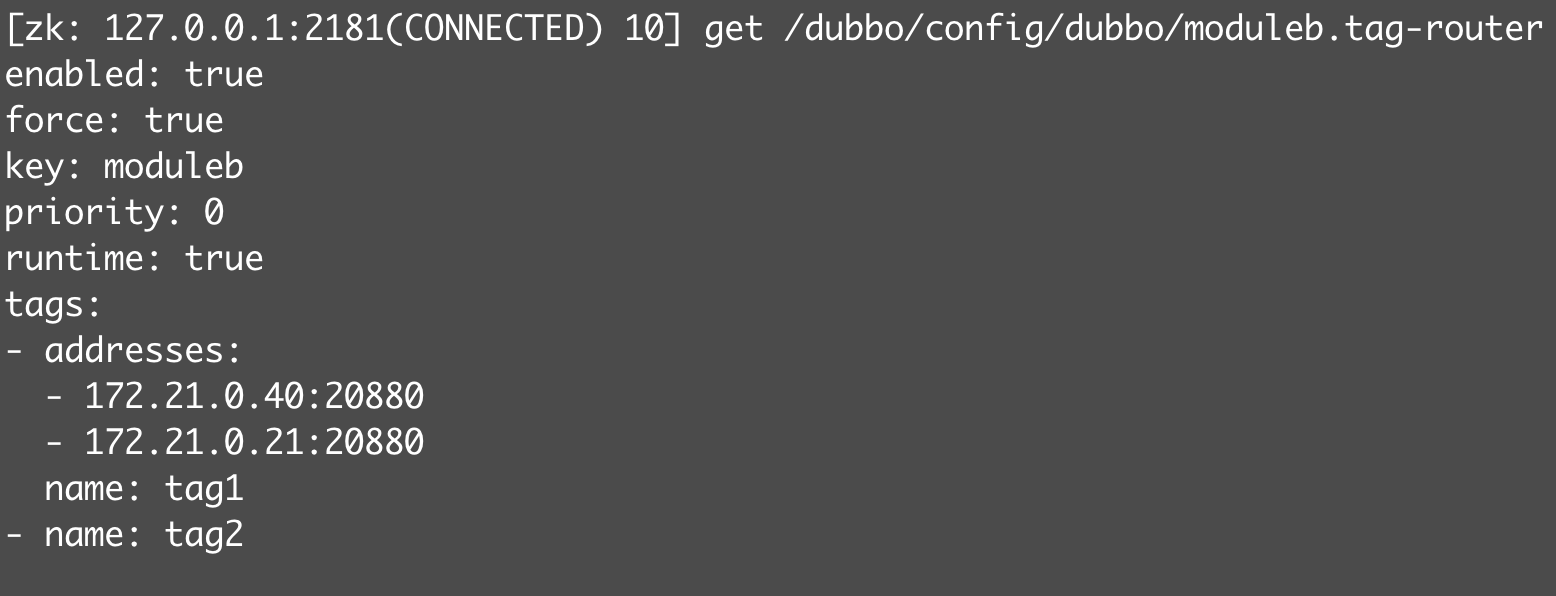
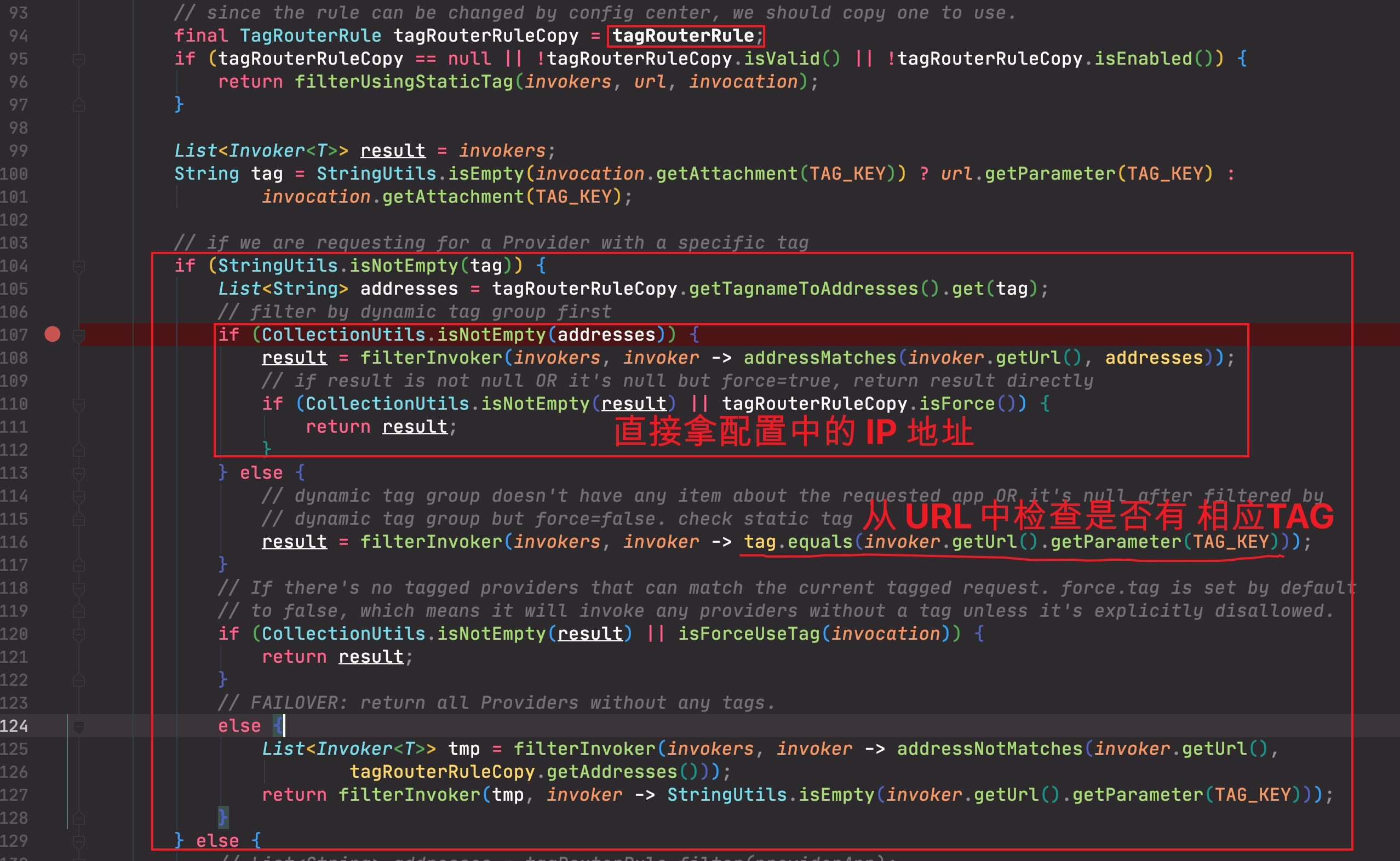
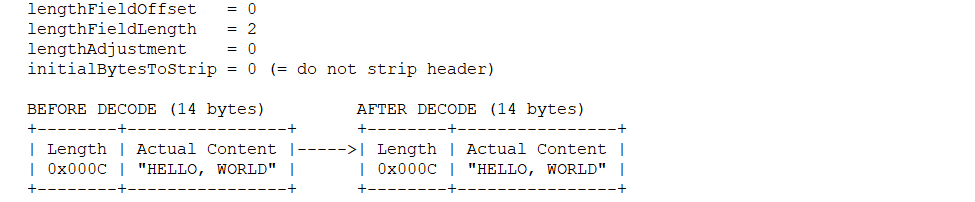
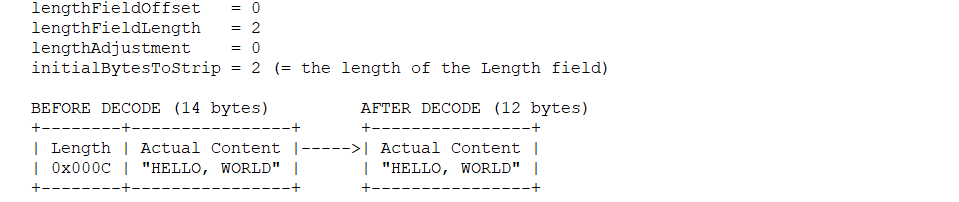
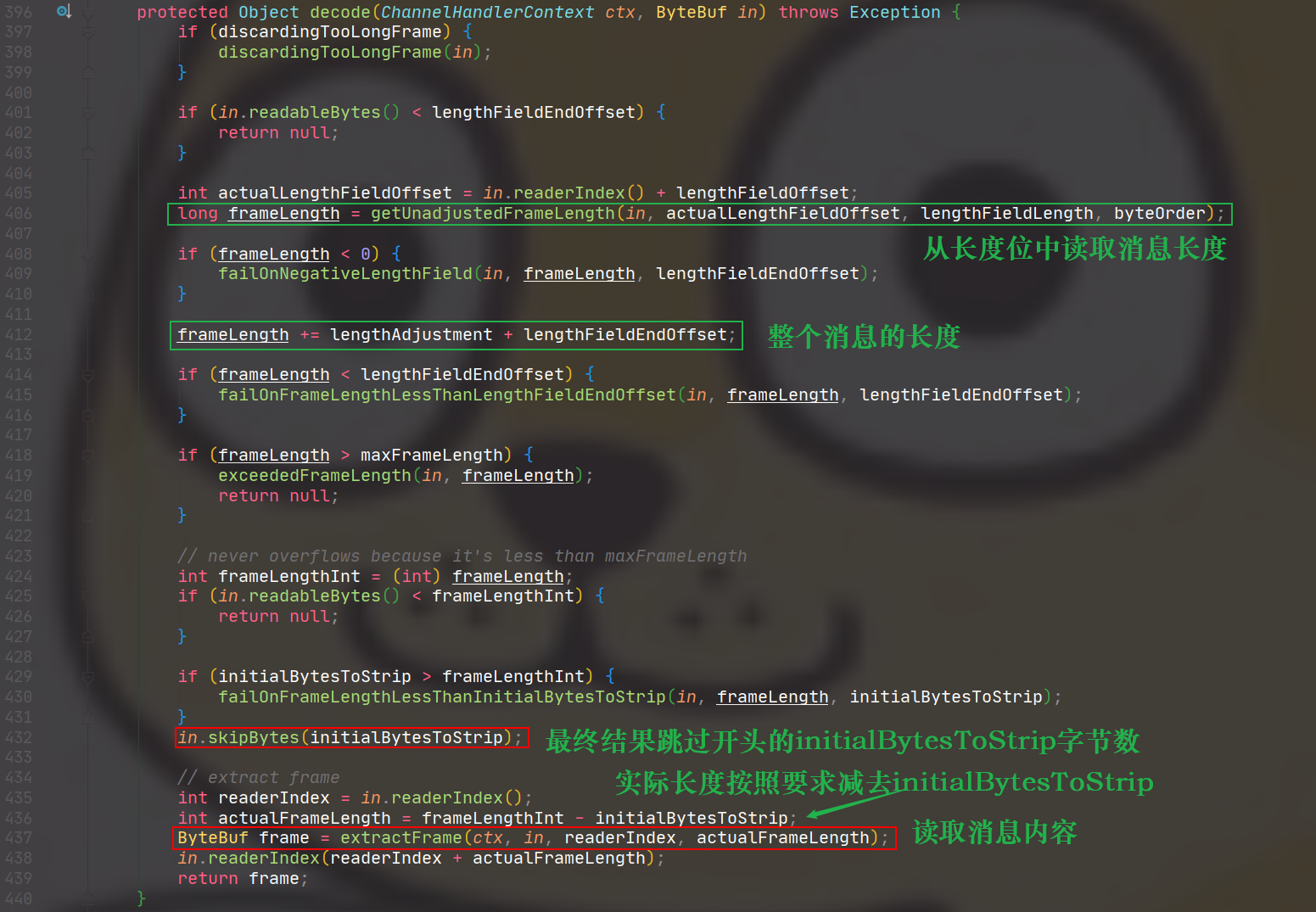
@Override publicsynchronizedvoidprocess(ConfigChangedEvent event) { if (logger.isDebugEnabled()) { logger.debug("Notification of tag rule, change type is: " + event.getChangeType() + ", raw rule is:\n " + event.getContent()); }
try { if (event.getChangeType().equals(ConfigChangeType.DELETED)) { this.tagRouterRule = null; } else { this.tagRouterRule = TagRuleParser.parse(event.getContent()); } } catch (Exception e) { logger.error("Failed to parse the raw tag router rule and it will not take effect, please check if the " + "rule matches with the template, the raw rule is:\n ", e); } }
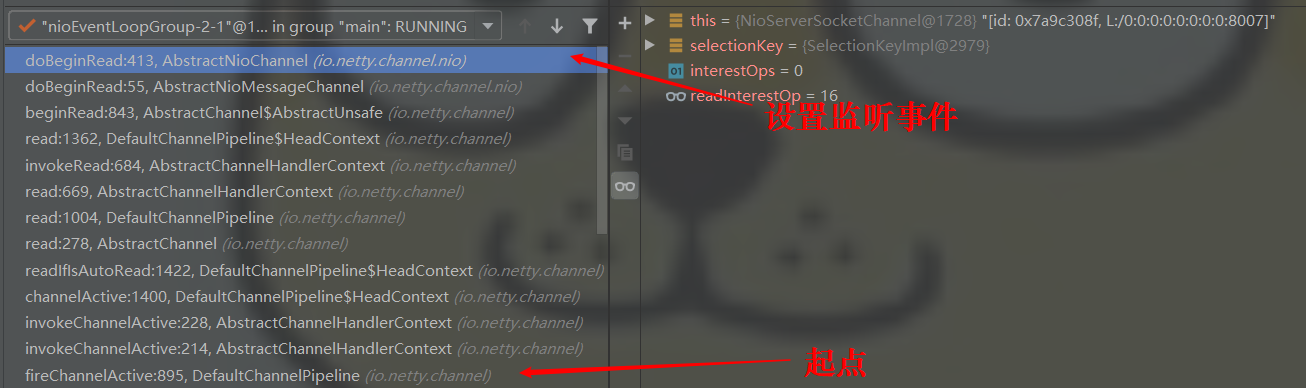
// AbstractNioChannel.java @Override protectedvoiddoBeginRead()throws Exception { // Channel.read() or ChannelHandlerContext.read() was called finalSelectionKeyselectionKey=this.selectionKey; if (!selectionKey.isValid()) { return; }
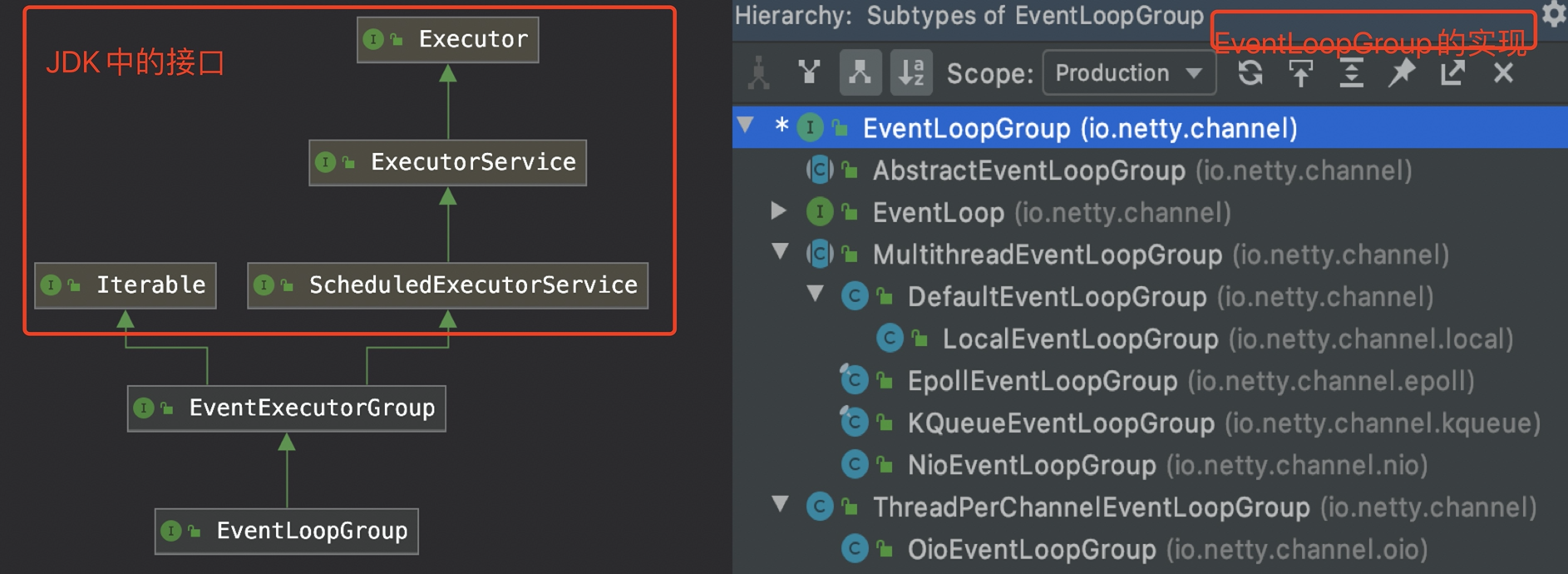
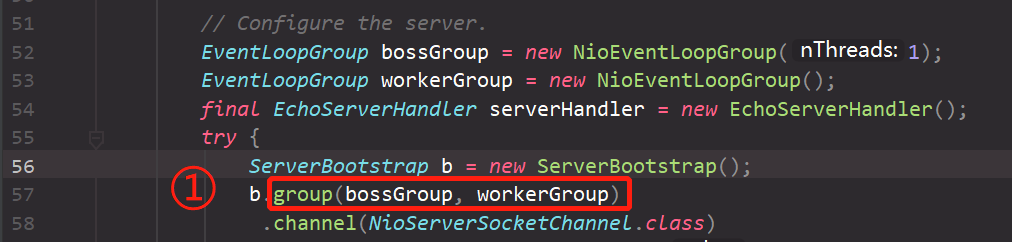
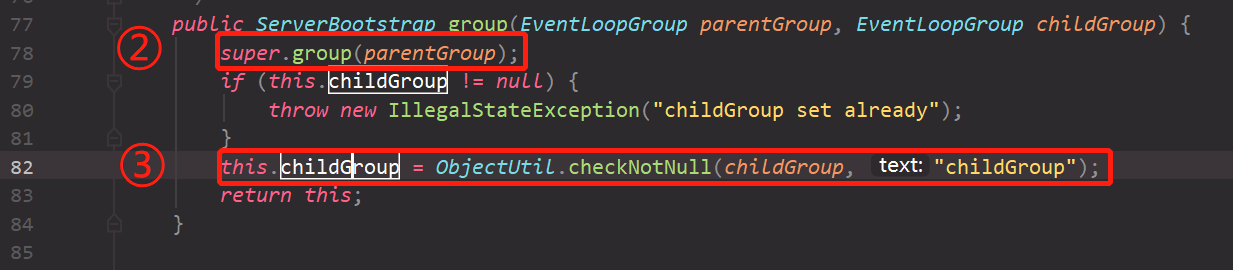
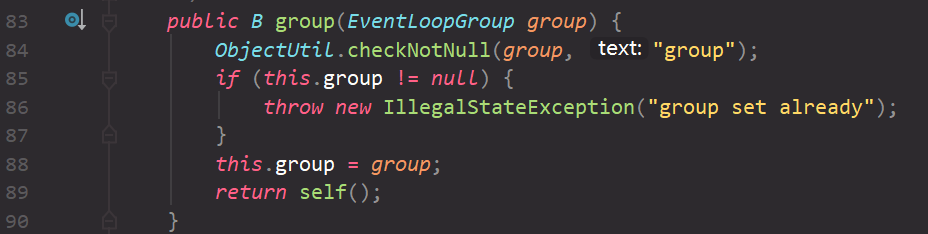
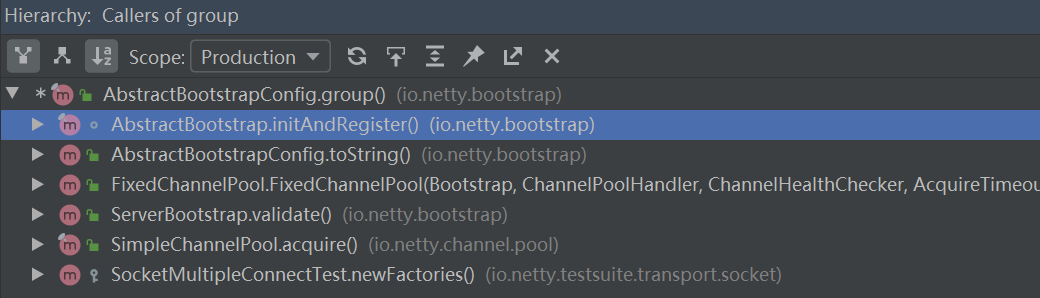
for (inti=0; i < nThreads; i ++) { booleansuccess=false; try { children[i] = newChild(executor, args); success = true; } catch (Exception e) { // TODO: Think about if this is a good exception type thrownewIllegalStateException("failed to create a child event loop", e); } finally { if (!success) { // 创建EventLoopGroup失败,释放资源 } } } // chooserFactory是用来创建一个选择器的工厂类。 chooser = chooserFactory.newChooser(children);
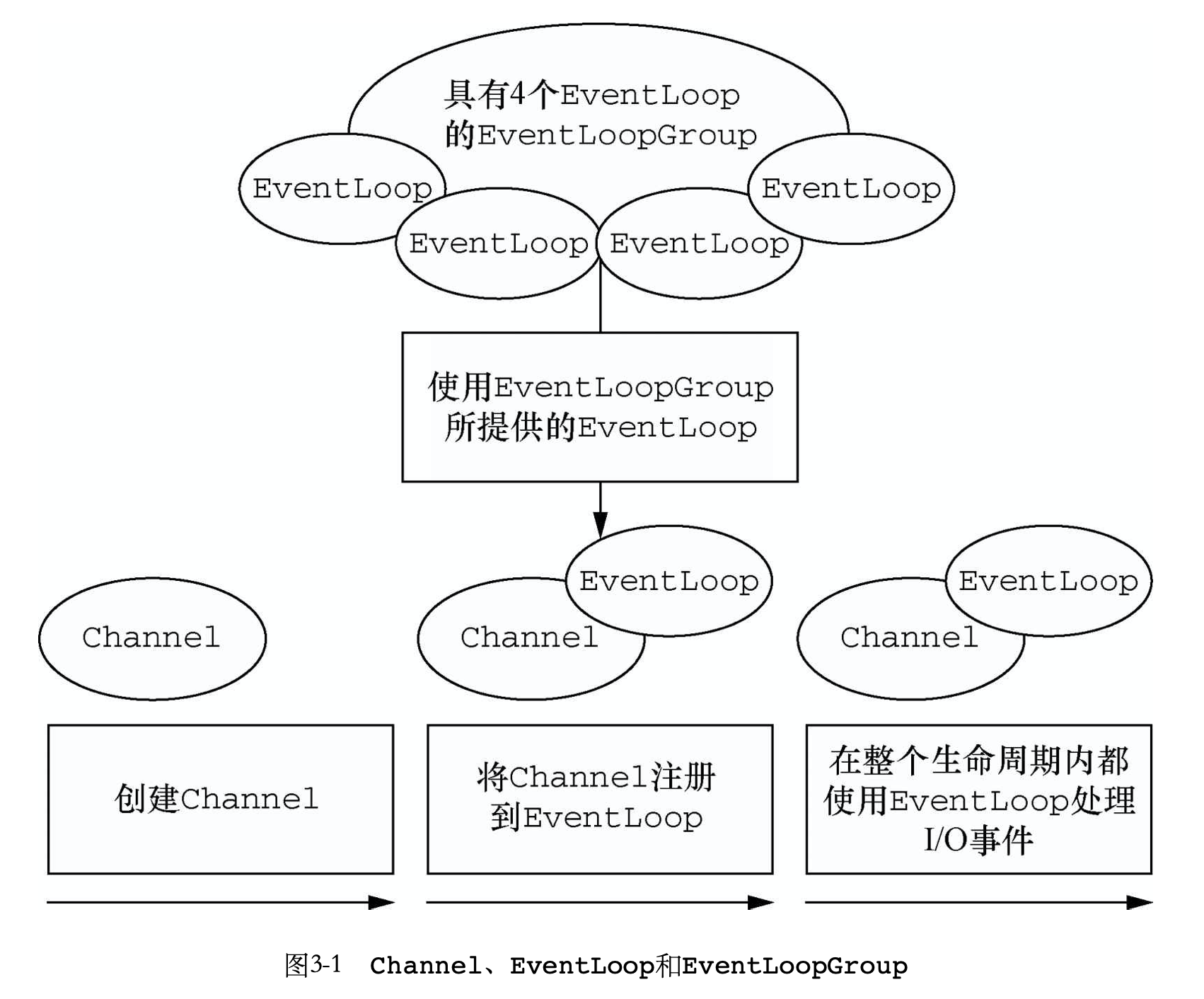
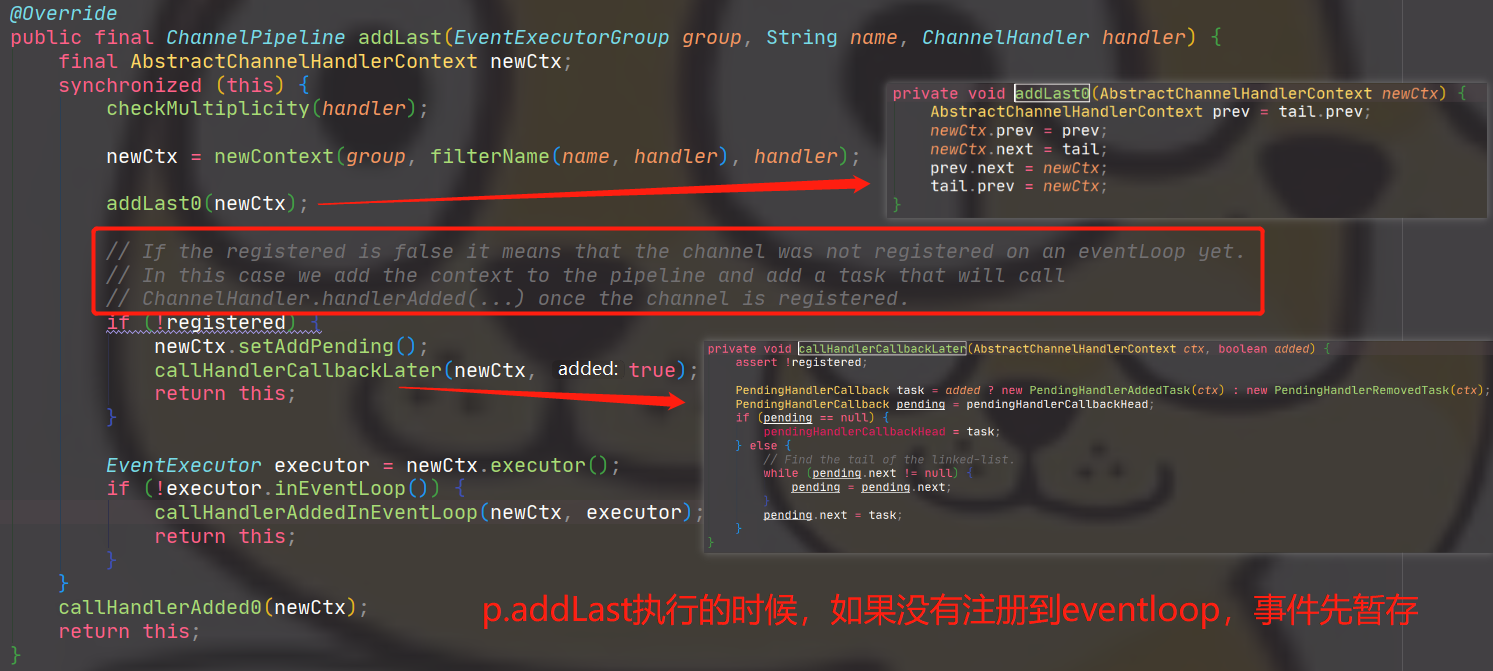
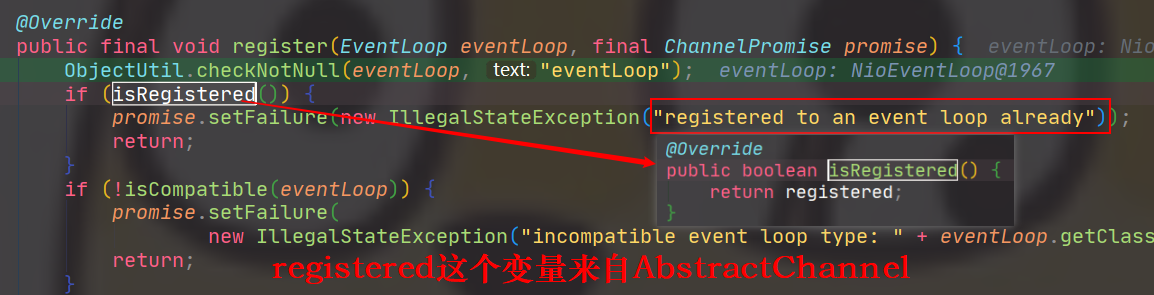
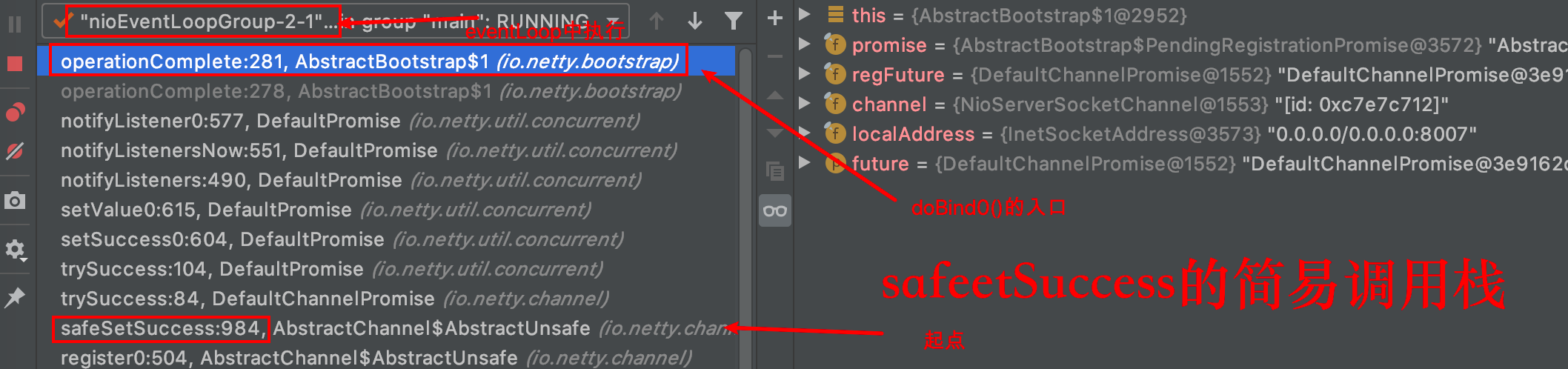
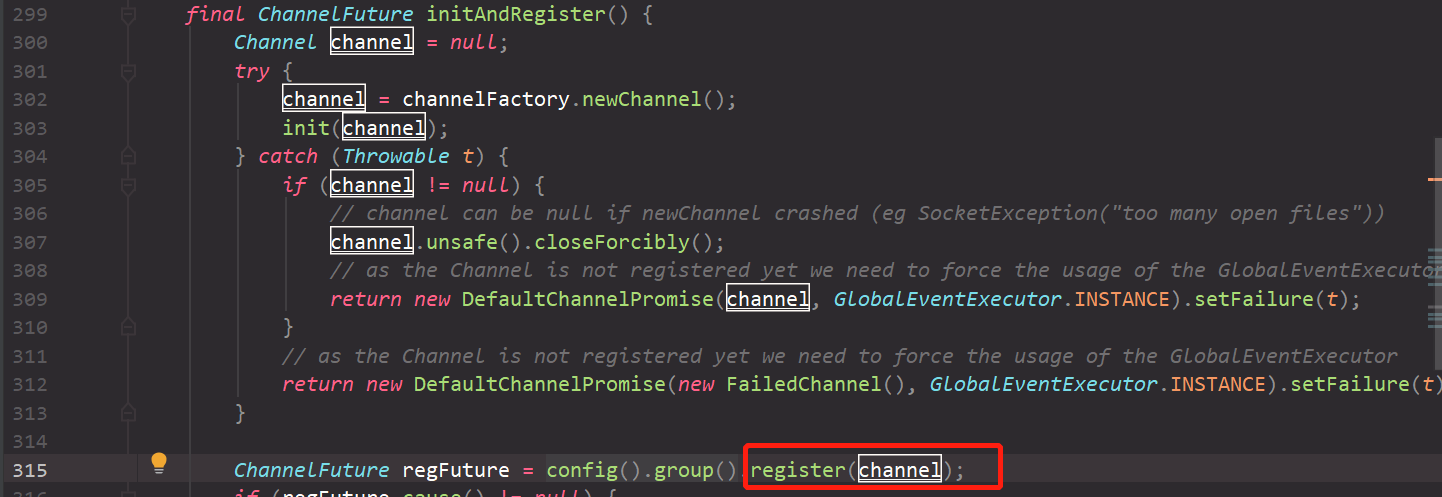
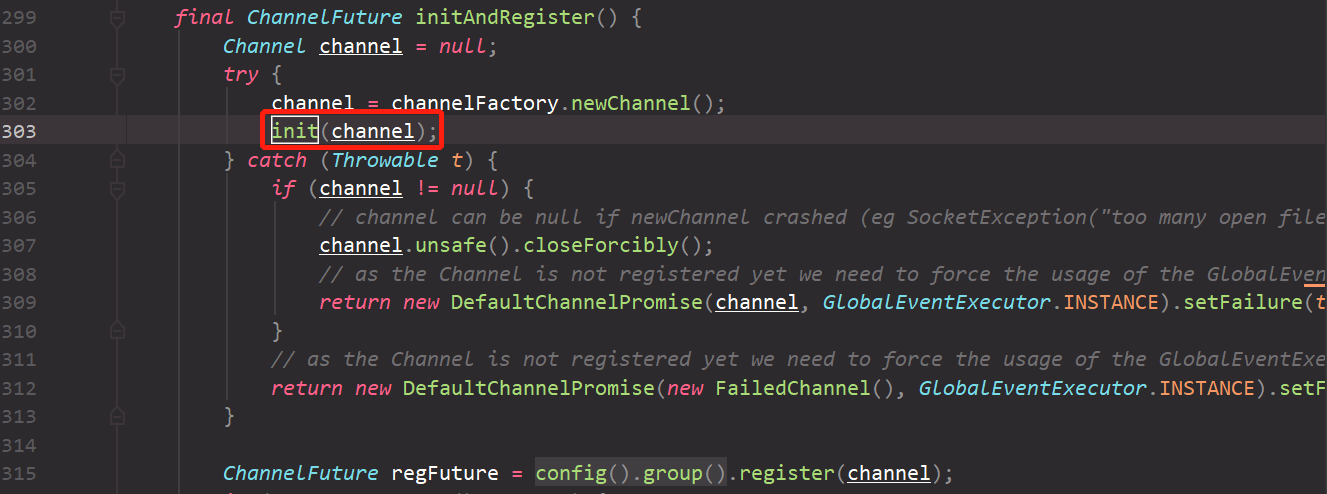
// 执行之前未绑定EventLoop时,添加的PendingHandlerCallback // 详细可以参考下面的执行PendingHandlerCallback的流程 pipeline.invokeHandlerAddedIfNeeded(); // 此方法在设置了promise的执行状态后,再通过观察者模式, // 通知所有的ChannelFutureListener,也就是会接着执行doBind0()。 safeSetSuccess(promise); pipeline.fireChannelRegistered(); // Only fire a channelActive if the channel has never been registered. This prevents firing // multiple channel actives if the channel is deregistered and re-registered. if (isActive()) { if (firstRegistration) { pipeline.fireChannelActive(); } elseif (config().isAutoRead()) { // This channel was registered before and autoRead() is set. This means we need to begin read // again so that we process inbound data. // // See https://github.com/netty/netty/issues/4805 beginRead(); } } } catch (Throwable t) { // Close the channel directly to avoid FD leak. closeForcibly(); closeFuture.setClosed(); safeSetFailure(promise, t); } }
// This must happen outside of the synchronized(...) block as otherwise handlerAdded(...) may be called while // holding the lock and so produce a deadlock if handlerAdded(...) will try to add another handler from outside // the EventLoop. PendingHandlerCallbacktask= pendingHandlerCallbackHead; // 依次遍历执行所有的pendingHandlerCallback while (task != null) { task.execute(); task = task.next; } }
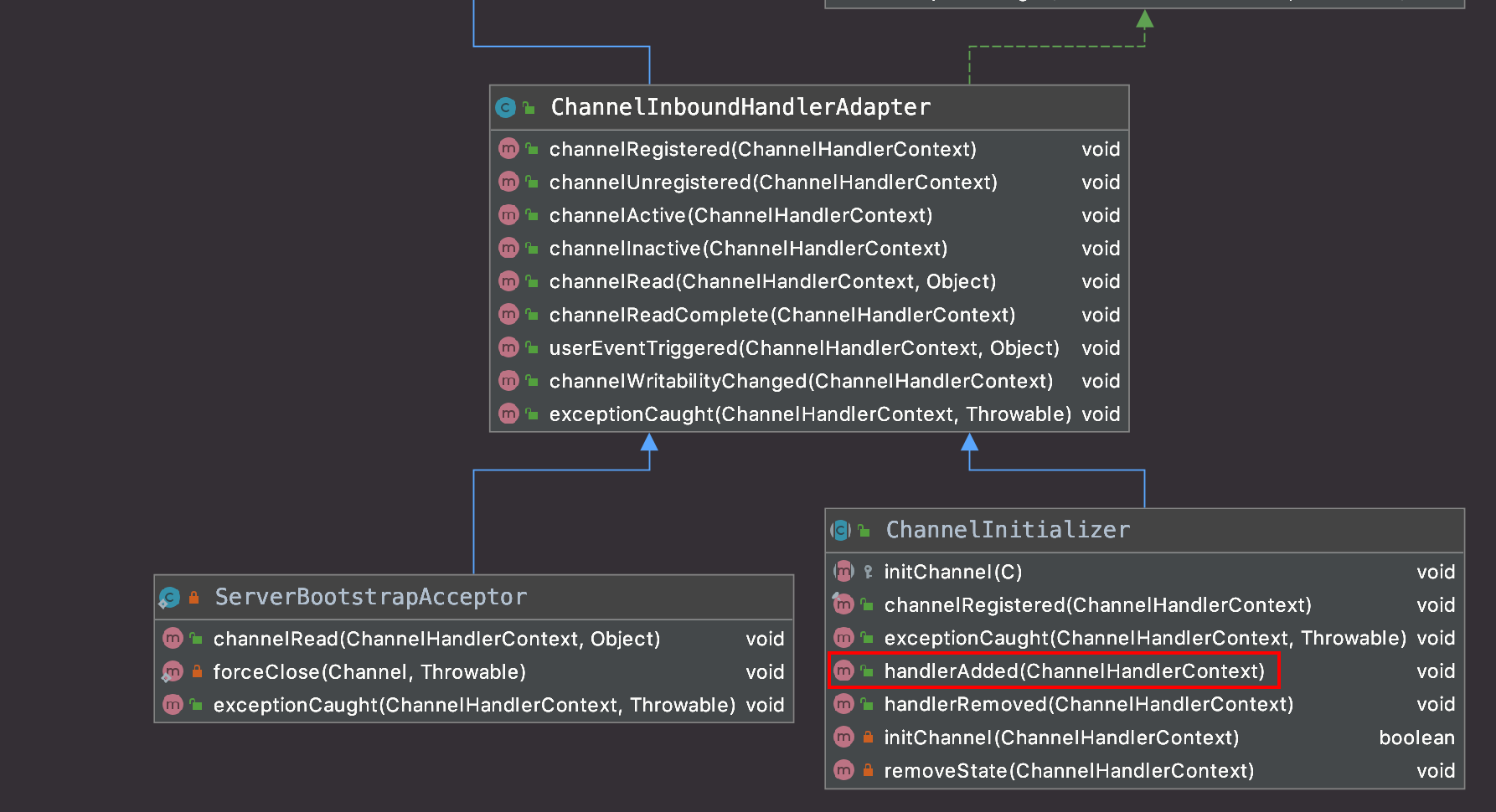
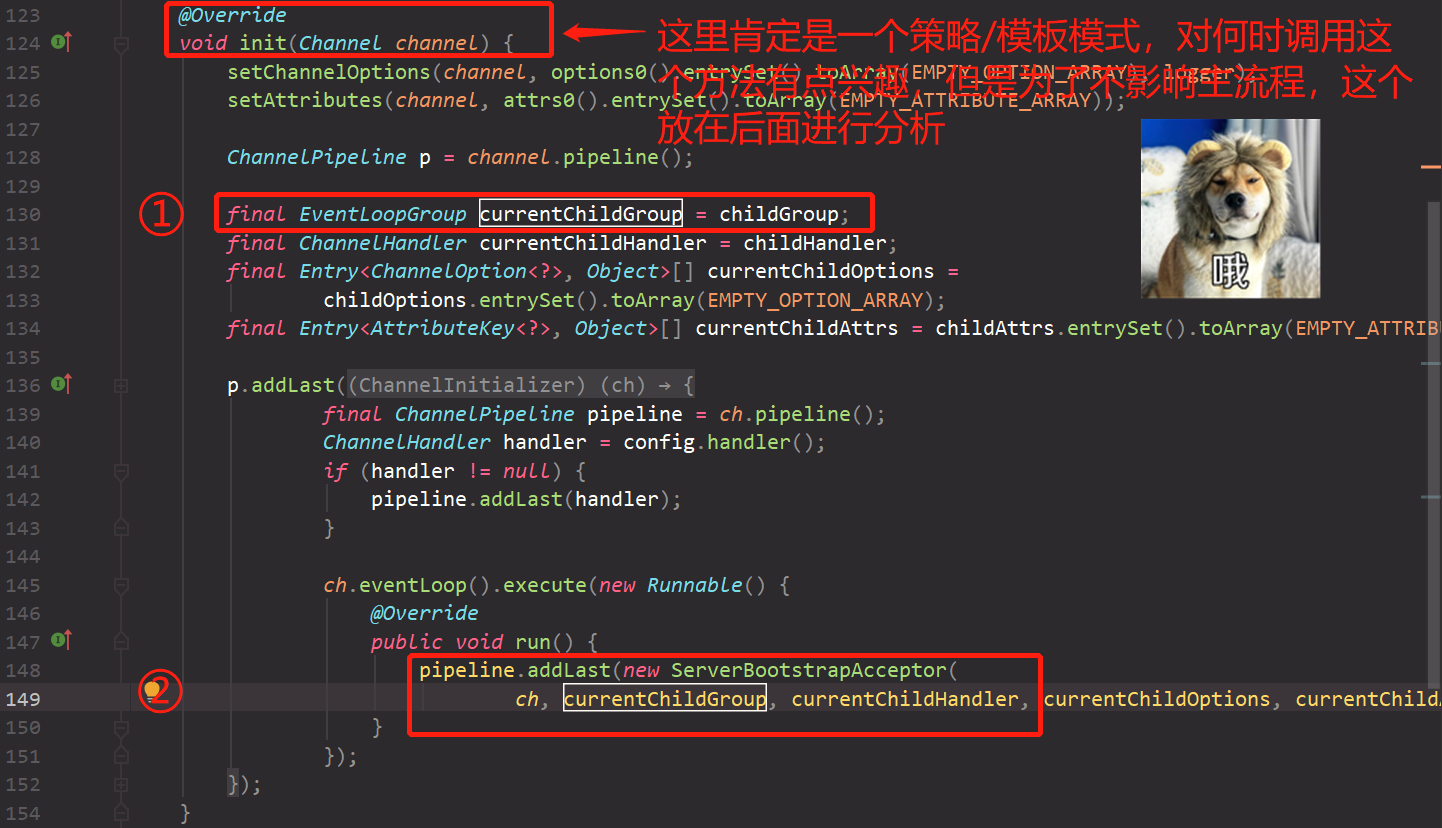
// AbstractChannelHandlerContext.java finalvoidcallHandlerAdded()throws Exception { // We must call setAddComplete before calling handlerAdded. Otherwise if the handlerAdded method generates // any pipeline events ctx.handler() will miss them because the state will not allow it. // 上述注释存疑,可待后续分析 if (setAddComplete()) { // handler在此处即ChannelInitialzer handler().handlerAdded(this); } }
// ChannelInitialzer.java @Override publicvoidhandlerAdded(ChannelHandlerContext ctx)throws Exception { if (ctx.channel().isRegistered()) { // This should always be true with our current DefaultChannelPipeline implementation. // The good thing about calling initChannel(...) in handlerAdded(...) is that there will be no ordering // surprises if a ChannelInitializer will add another ChannelInitializer. This is as all handlers // will be added in the expected order. if (initChannel(ctx)) {
// We are done with init the Channel, removing the initializer now. removeState(ctx); } } }
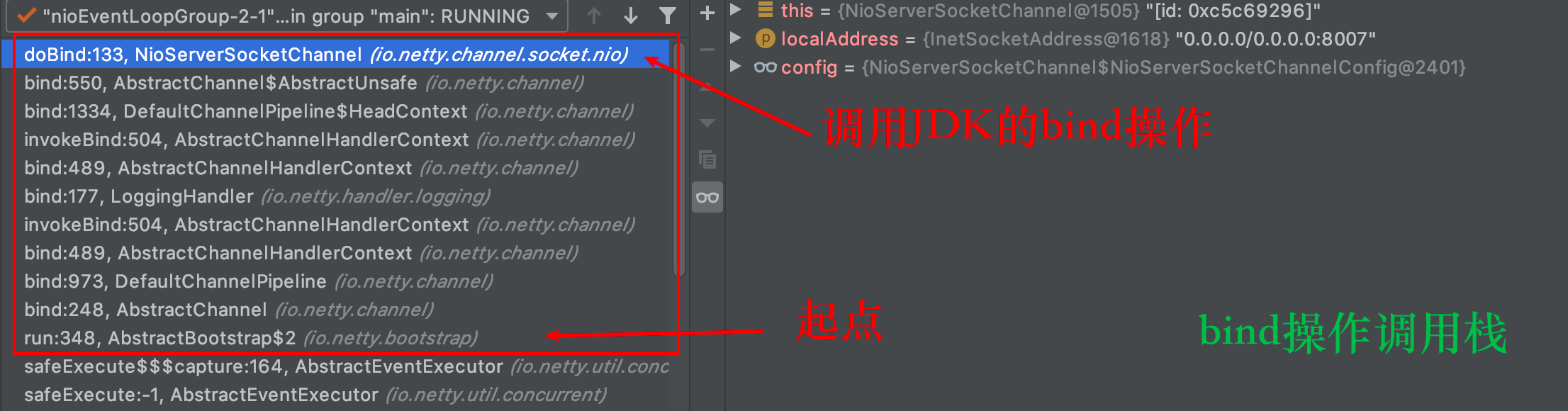
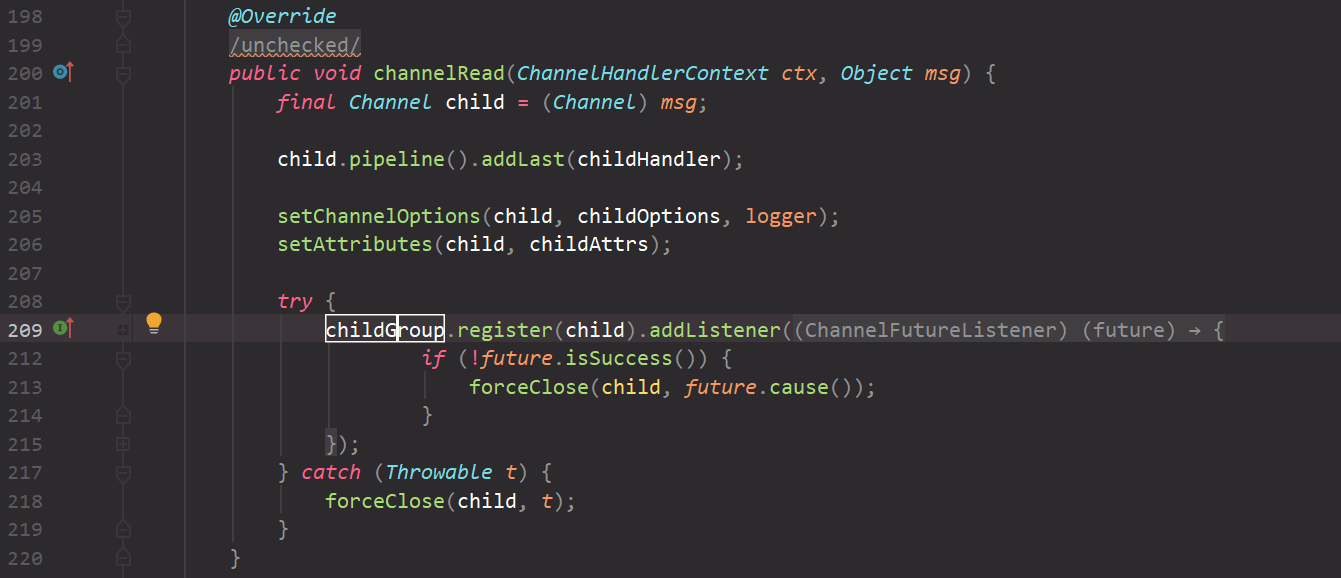
privatestaticvoiddoBind0(...) { // This method is invoked before channelRegistered() is triggered. // Give user handlers a chance to set up the pipeline // in its channelRegistered() implementation. channel.eventLoop().execute(newRunnable() { @Override publicvoidrun() { if (regFuture.isSuccess()) { channel.bind(localAddress, promise).addListener(ChannelFutureListener.CLOSE_ON_FAILURE); } else { promise.setFailure(regFuture.cause()); } } }); }
// AbstractNioChannel.java @Override protectedvoiddoBeginRead()throws Exception { // Channel.read() or ChannelHandlerContext.read() was called finalSelectionKeyselectionKey=this.selectionKey; if (!selectionKey.isValid()) { return; }
// NioEventLoop.java @Override protectedvoidrun() { intselectCnt=0; for (;;) { try { int strategy; try { strategy = selectStrategy.calculateStrategy(selectNowSupplier, hasTasks()); switch (strategy) { case SelectStrategy.CONTINUE: continue;
case SelectStrategy.BUSY_WAIT: // fall-through to SELECT since the busy-wait is not supported with NIO
case SelectStrategy.SELECT: longcurDeadlineNanos= nextScheduledTaskDeadlineNanos(); if (curDeadlineNanos == -1L) { curDeadlineNanos = NONE; // nothing on the calendar } nextWakeupNanos.set(curDeadlineNanos); try { if (!hasTasks()) { strategy = select(curDeadlineNanos); } } finally { // This update is just to help block unnecessary selector wakeups // so use of lazySet is ok (no race condition) nextWakeupNanos.lazySet(AWAKE); } // fall through default: } } catch (IOException e) { // If we receive an IOException here its because the Selector is messed up. Let's rebuild // the selector and retry. https://github.com/netty/netty/issues/8566 rebuildSelector0(); selectCnt = 0; handleLoopException(e); continue; }
selectCnt++; cancelledKeys = 0; needsToSelectAgain = false; finalintioRatio=this.ioRatio; boolean ranTasks; if (ioRatio == 100) { try { if (strategy > 0) { processSelectedKeys(); } } finally { // Ensure we always run tasks. ranTasks = runAllTasks(); } } elseif (strategy > 0) { finallongioStartTime= System.nanoTime(); try { processSelectedKeys(); } finally { // Ensure we always run tasks. finallongioTime= System.nanoTime() - ioStartTime; ranTasks = runAllTasks(ioTime * (100 - ioRatio) / ioRatio); } } else { ranTasks = runAllTasks(0); // This will run the minimum number of tasks }
if (ranTasks || strategy > 0) { if (selectCnt > MIN_PREMATURE_SELECTOR_RETURNS && logger.isDebugEnabled()) { logger.debug("Selector.select() returned prematurely {} times in a row for Selector {}.", selectCnt - 1, selector); } selectCnt = 0; } elseif (unexpectedSelectorWakeup(selectCnt)) { // Unexpected wakeup (unusual case) selectCnt = 0; } } catch (CancelledKeyException e) { // Harmless exception - log anyway if (logger.isDebugEnabled()) { logger.debug(CancelledKeyException.class.getSimpleName() + " raised by a Selector {} - JDK bug?", selector, e); } } catch (Throwable t) { handleLoopException(t); } // Always handle shutdown even if the loop processing threw an exception. try { if (isShuttingDown()) { closeAll(); if (confirmShutdown()) { return; } } } catch (Throwable t) { handleLoopException(t); } } }
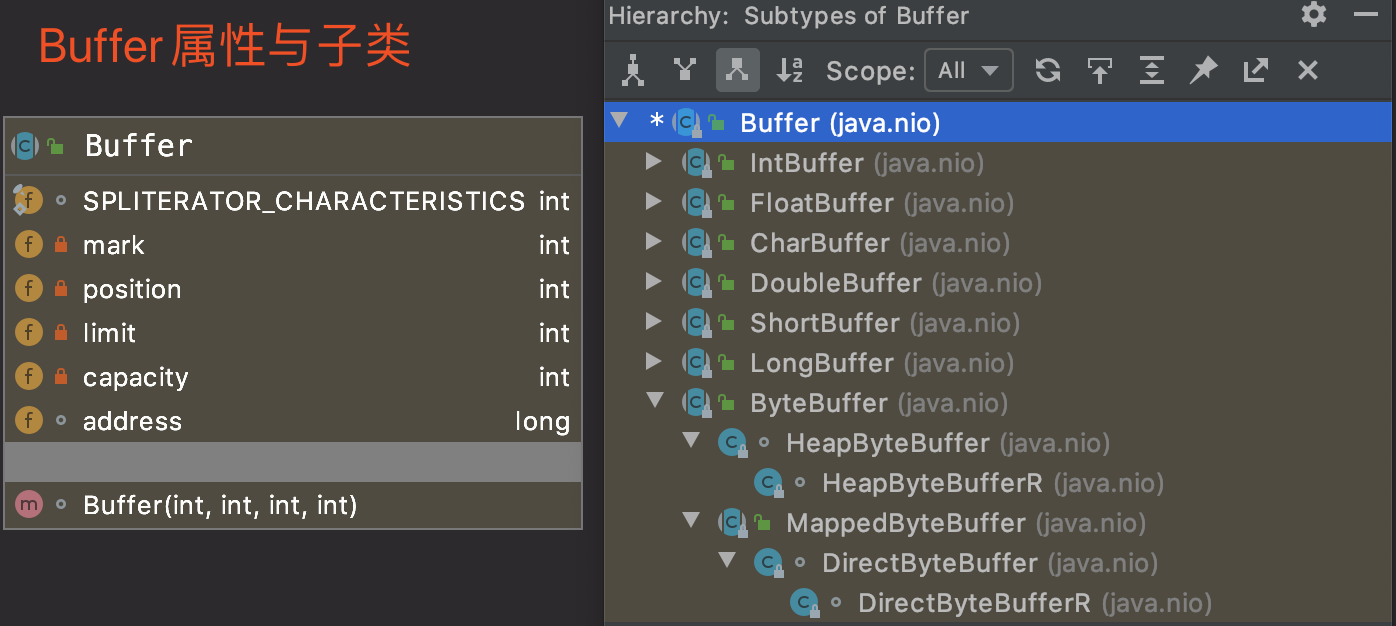
A container for data of a specific primitive type.
A buffer is a linear, finite sequence of elements of a specific primitive type. Aside from its content, the essential properties of a buffer are its capacity, limit, and position:
A buffer’s capacity is the number of elements it contains. The capacity of a buffer is never negative and never changes.
A buffer’s limit is the index of the first element that should not be read or written. A buffer’s limit is never negative and is never greater than its capacity.
A buffer’s position is the index of the next element to be read or written. A buffer’s position is never negative and is never greater than its limit.
There is one subclass of this class for each non-boolean primitive type.
Transferring data
Each subclass of this class defines two categories of get and put operations:
Relative operations read or write one or more elements starting at the current position and then increment the position by the number of elements transferred. If the requested transfer exceeds the limit then a relative get operation throws a BufferUnderflowException and a relative put operation throws a BufferOverflowException; in either case, no data is transferred.
Absolute operations take an explicit element index and do not affect the position. Absolute get and put operations throw an IndexOutOfBoundsException if the index argument exceeds the limit.
Data may also, of course, be transferred in to or out of a buffer by the I/O operations of an appropriate channel, which are always relative to the current position.
Marking and resetting
A buffer’s mark is the index to which its position will be reset when the reset method is invoked. The mark is not always defined, but when it is defined it is never negative and is never greater than the position. If the mark is defined then it is discarded when the position or the limit is adjusted to a value smaller than the mark. If the mark is not defined then invoking the reset method causes an InvalidMarkException to be thrown.
Invariants
The following invariant holds for the mark, position, limit, and capacity values:
0 <= mark <= position <= limit <= capacity
A newly-created buffer always has a position of zero and a mark that is undefined. The initial limit may be zero, or it may be some other value that depends upon the type of the buffer and the manner in which it is constructed. Each element of a newly-allocated buffer is initialized to zero.
Clearing, flipping, and rewinding
In addition to methods for accessing the position, limit, and capacity values and for marking and resetting, this class also defines the following operations upon buffers:
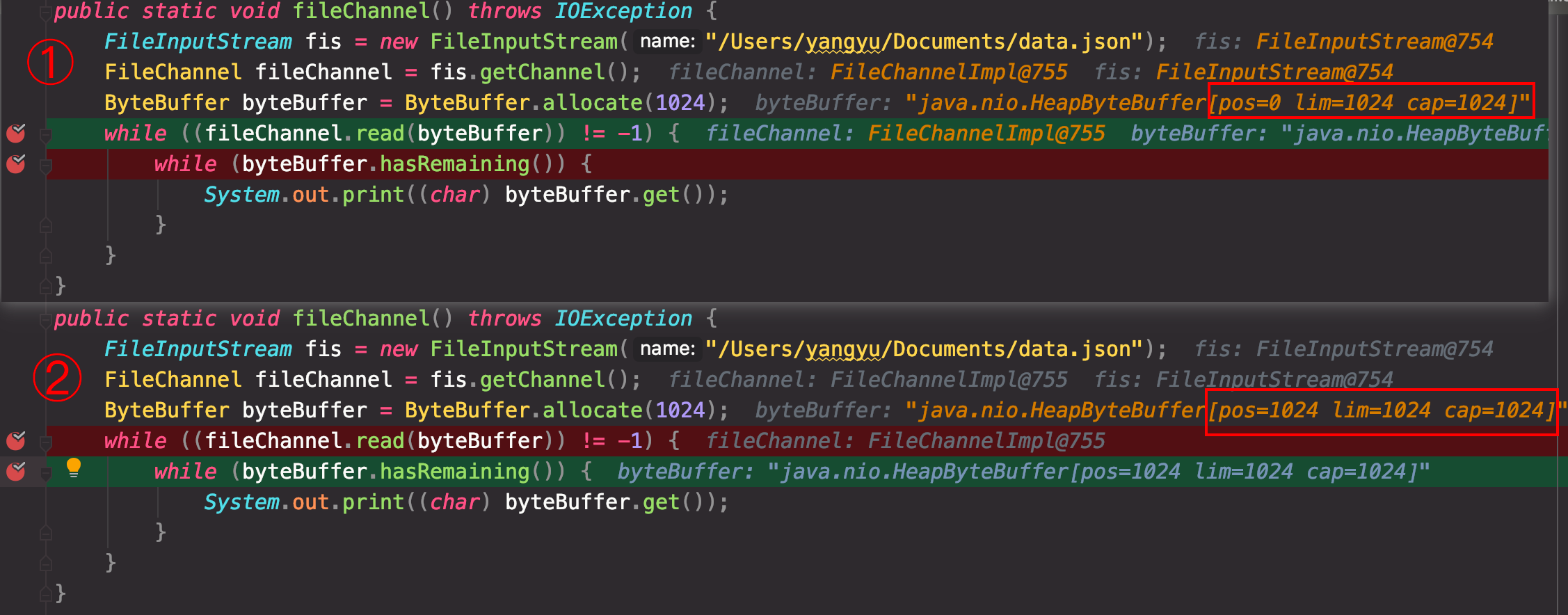
clear()makes a buffer ready for a new sequence of channel-read or relative put operations: It sets the limit to the capacity and the position to zero.
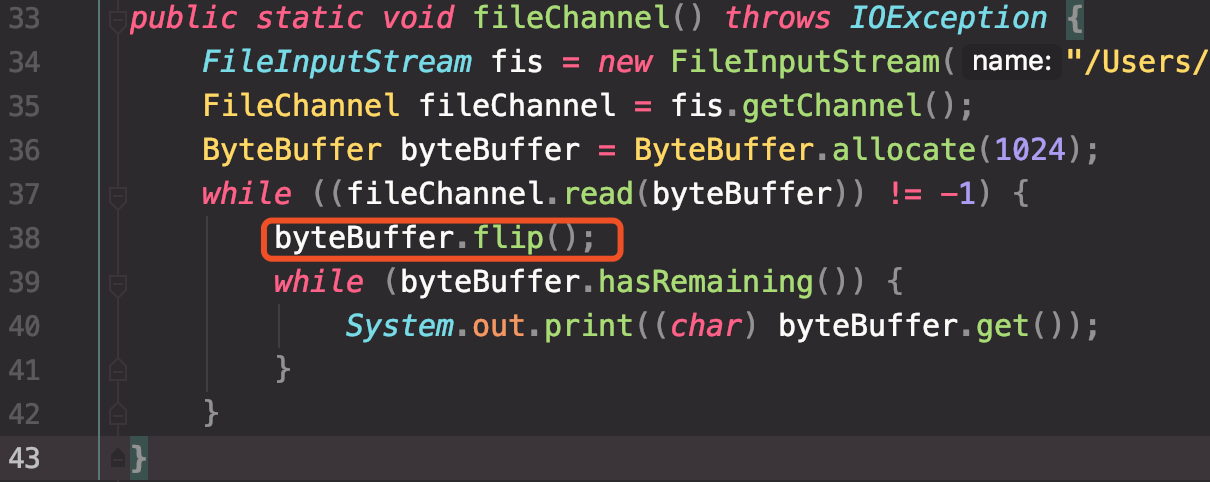
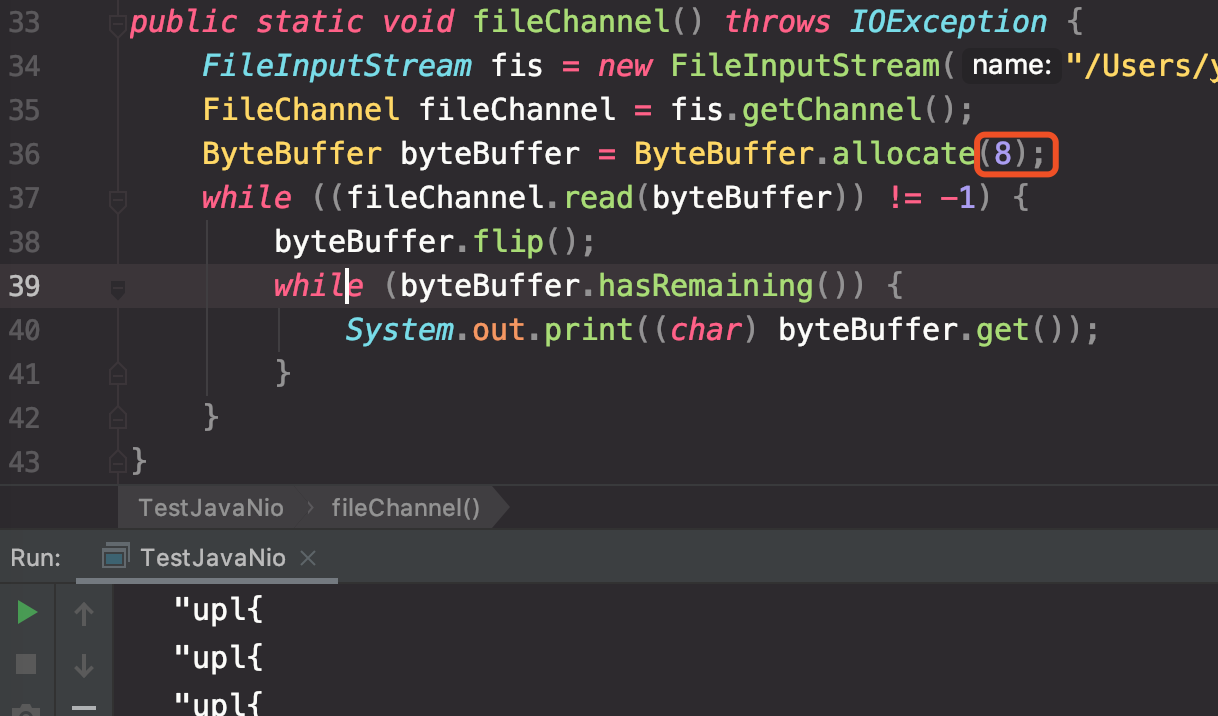
flip()makes a buffer ready for a new sequence of channel-write or relative get operations: It sets the limit to the current position and then sets the position to zero.
rewind()makes a buffer ready for re-reading the data that it already contains: It leaves the limit unchanged and sets the position to zero.
Read-only buffers
Every buffer is readable, but not every buffer is writable. The mutation methods of each buffer class are specified as optional operations that will throw a ReadOnlyBufferException when invoked upon a read-only buffer. A read-only buffer does not allow its content to be changed, but its mark, position, and limit values are mutable. Whether or not a buffer is read-only may be determined by invoking its isReadOnly method.
Thread safety
Buffers are not safe for use by multiple concurrent threads. If a buffer is to be used by more than one thread then access to the buffer should be controlled by appropriate synchronization.
Invocation chaining
Methods in this class that do not otherwise have a value to return are specified to return the buffer upon which they are invoked. This allows method invocations to be chained; for example, the sequence of statements
1 2 3
b.flip(); b.position(23); b.limit(42);
can be replaced by the single, more compact statement b.flip().position(23).limit(42);
clear()方法
1 2 3 4 5 6 7
// 清除Buffer中的信息,只将参数恢复成默认 publicfinal Buffer clear() { position = 0; limit = capacity; mark = -1; returnthis; }
flip()方法
1 2 3 4 5 6 7
// 将limit记录成当前的位置,指针指向头部,为读取做准备 publicfinal Buffer flip() { limit = position; position = 0; mark = -1; returnthis; }
rewind()方法
1 2 3 4 5 6
// 指针指向头部,可以用于再次读取 publicfinal Buffer rewind() { position = 0; mark = -1; returnthis; }
Compacts this buffer (optional operation). The bytes between the buffer’s current position and its limit, if any, are copied to the beginning of the buffer. That is, the byte at index p = position() is copied to index zero, the byte at index p + 1 is copied to index one, and so forth until the byte at index limit() - 1 is copied to index n = limit() - 1 - p. The buffer’s position is then set to n+1 and its limit is set to its capacity. The mark, if defined, is discarded.
The buffer’s position is set to the number of bytes copied, rather than to zero, so that an invocation of this method can be followed immediately by an invocation of another relative put method.
Invoke this method after writing data from a buffer in case the write was incomplete. The following loop, for example, copies bytes from one channel to another via the buffer buf:
1 2 3 4 5 6
buf.clear(); // Prepare buffer for use while (in.read(buf) >= 0 || buf.position != 0) { buf.flip(); out.write(buf); buf.compact(); // In case of partial write }
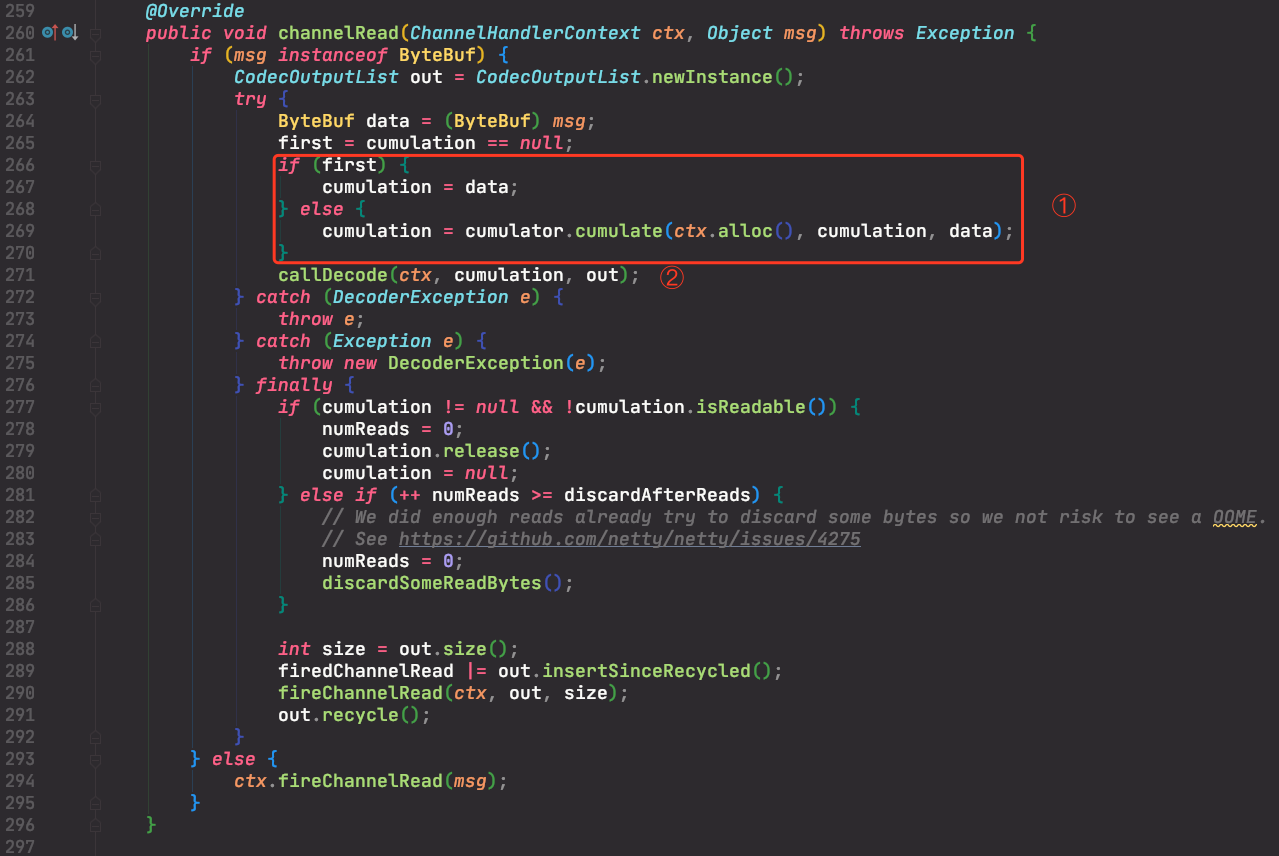
/** * Cumulate {@link ByteBuf}s by merge them into one {@link ByteBuf}'s, using memory copies. */ publicstaticfinalCumulatorMERGE_CUMULATOR=newCumulator() { @Override public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) { try { finalintrequired= in.readableBytes(); if (required > cumulation.maxWritableBytes() || (required > cumulation.maxFastWritableBytes() && cumulation.refCnt() > 1) || cumulation.isReadOnly()) { // Expand cumulation (by replacing it) under the following conditions: // - cumulation cannot be resized to accommodate the additional data // - cumulation can be expanded with a reallocation operation to accommodate but the buffer is // assumed to be shared (e.g. refCnt() > 1) and the reallocation may not be safe. return expandCumulation(alloc, cumulation, in); } return cumulation.writeBytes(in); } finally { // We must release in in all cases as otherwise it may produce a leak if writeBytes(...) throw // for whatever release (for example because of OutOfMemoryError) in.release(); } } };
/** * Cumulate {@link ByteBuf}s by add them to a {@link CompositeByteBuf} and so do no memory copy whenever possible. * Be aware that {@link CompositeByteBuf} use a more complex indexing implementation so depending on your use-case * and the decoder implementation this may be slower then just use the {@link #MERGE_CUMULATOR}. */ publicstaticfinalCumulatorCOMPOSITE_CUMULATOR=newCumulator() { @Override public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) { try { if (cumulation.refCnt() > 1) { // Expand cumulation (by replace it) when the refCnt is greater then 1 which may happen when the // user use slice().retain() or duplicate().retain(). // // See: // - https://github.com/netty/netty/issues/2327 // - https://github.com/netty/netty/issues/1764 return expandCumulation(alloc, cumulation, in); } final CompositeByteBuf composite; if (cumulation instanceof CompositeByteBuf) { composite = (CompositeByteBuf) cumulation; } else { composite = alloc.compositeBuffer(MAX_VALUE); composite.addComponent(true, cumulation); } composite.addComponent(true, in); in = null; return composite; } finally { if (in != null) { // We must release if the ownership was not transferred as otherwise it may produce a leak if // writeBytes(...) throw for whatever release (for example because of OutOfMemoryError). in.release(); } } } };
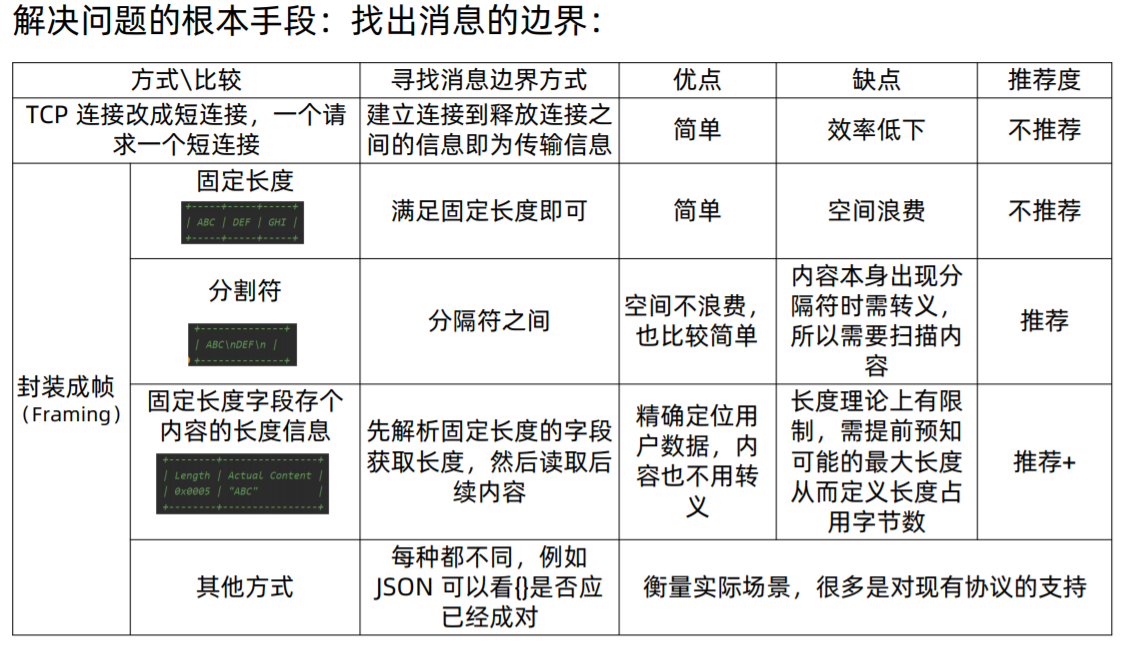
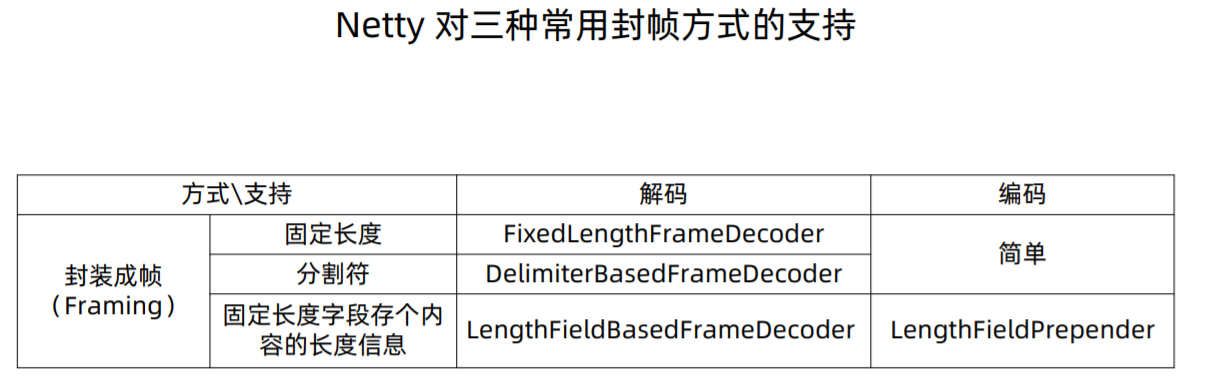
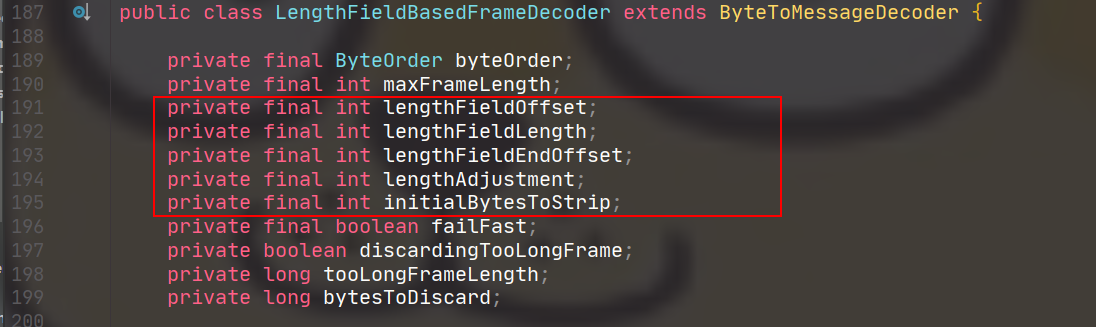
A decoder that splits the received ByteBufs by the fixed number of bytes. For example, if you received the following four fragmented packets: +---+----+------+----+ | A | BC | DEFG | HI | +---+----+------+----+
A FixedLengthFrameDecoder(3) will decode them into the following three packets with the fixed length: +-----+-----+-----+ | ABC | DEF | GHI | +-----+-----+-----+
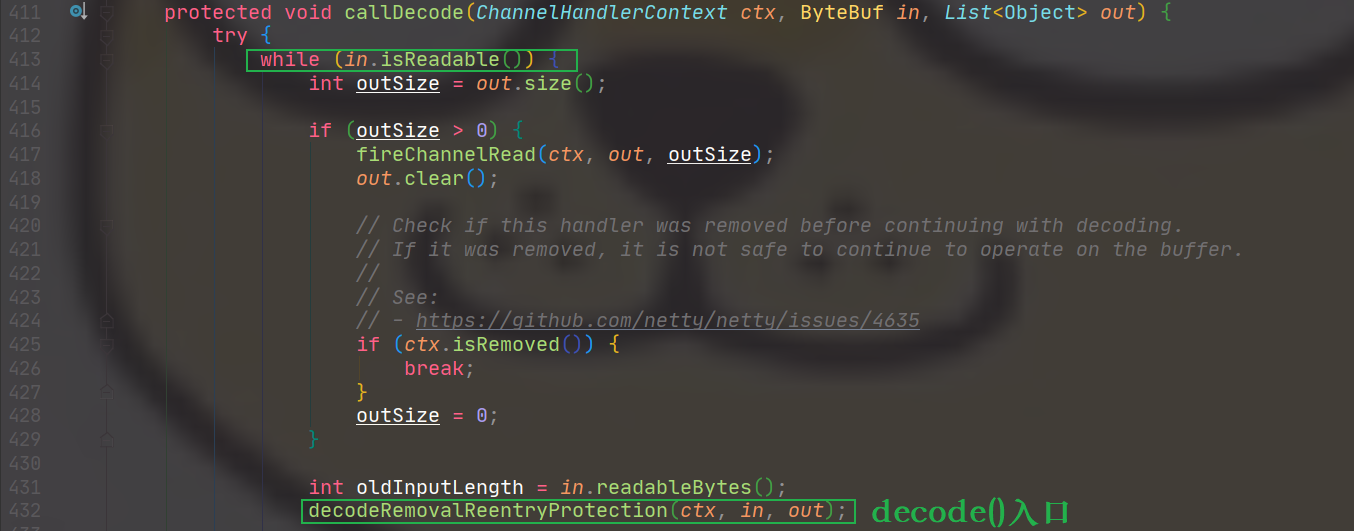
@Override protectedfinalvoiddecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)throws Exception { Objectdecoded= decode(ctx, in); if (decoded != null) { out.add(decoded); } }
/** * Create a frame out of the {@link ByteBuf} and return it. * * @param ctx the {@link ChannelHandlerContext} which this {@link ByteToMessageDecoder} belongs to * @param in the {@link ByteBuf} from which to read data * @return frame the {@link ByteBuf} which represent the frame or {@code null} if no frame could * be created. */ protected Object decode( @SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in)throws Exception { if (in.readableBytes() < frameLength) { returnnull;// 长度不够,此次decode不产生消息 } else { return in.readRetainedSlice(frameLength); } }