Helm3进行template时如何处理Capabilities.KubeVersion字段
Goalng
context作用,原理,超时控制
golang context的理解,context主要用于父子任务之间的同步取消信号,本质上是一种协程调度的方式。另外在使用context时有两点值得注意:上游任务仅仅使用context通知下游任务不再需要,但不会直接干涉和中断下游任务的执行,由下游任务自行决定后续的处理操作,也就是说context的取消操作是无侵入的;context是线程安全的,因为context本身是不可变的(immutable),因此可以放心地在多个协程中传递使用。切片和数组区别
基础问题。channel关闭阻塞问题,goroutine如何调度,gopark是怎么回事?PMG模型描述,谁创建的PMG,runtime是怎么个东西,怎么启动第一个goroutine
golang CPS并发模型和PMG模型的理解。go逃逸分析怎么回事,内存什么时候栈分配什么时候堆分配
内存方面问题,这个网上很多,自己理解完整正确。sync.Map实现原理,适用的场景
go 1.9 官方提供sync.Map 来优化线程安全的并发读写的map。该实现也是基于内置map关键字来实现的。
这个实现类似于一个线程安全的 map[interface{}]interface{} . 这个map的优化主要适用了以下场景:
(1)给定key的键值对只写了一次,但是读了很多次,比如在只增长的缓存中;
(2)当多个goroutine读取、写入和覆盖的key值不相交时。
更进一步,可看sync.Map源码。go语言有什么优点和缺点
优势:容易学习,生产力,并发,动态语法。劣势:包管理,错误处理,缺乏框架。Go框架用过哪些,有看源码吗
优势:beego,go-micro,gin等Go GC算法,三色标记法描述
自己找,网上有Go内存模型(tcmalloc)
tcmalloc是线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数
算法
行列都是有序的二维数组,查找k是否存在,时间复杂度
1
2
3
4
51 3 5 7 9
3 5 7 9 11
4 6 8 10 12二分查找:O(log2(max(m,n)))
有序数组,有2N+1个数,其中N个数成对出现,仅1个数单独出现,找出那个单独出现的数.,时间复杂度
1,1,2,2,3,4,4,5,5,6,6,7,7
答案为3O(log2(2N))二分查找,查找中间位置的数相等值是在左边还是右边?左边则再左子数组继续查找,右边则在右子数组继续查找。
100亿个数求top100,时间复杂度
分组查找或bitmap100亿个数和100亿个数求交集,时间复杂度
全排列问题,自己找去hash算法实现(类似crc32或者murmur),保证随机性和均匀性,减少哈希冲突
考的是hash算法的了解,需要知道一些经典哈希算法实现。100个球,一次只能拿2-5个,你先拿,我后拿,怎么保证你能拿到最后一个球
一次2-5,去掉先手,最后回合剩余7个即可保证拿到最后一个球。因此,先手拿2个,每一回合保证拿掉球的总数为7,即可。(100-2)/7=14回合。正整数数组,求和为sum的组合 换零钱,1,5,10元都很充足,给你N元去换零钱,多少种换法
算法题给定一个有n个正整数的数组A和一个整数sum,求选择数组A中部分数字和为sum的方案数,动态规划法。图的最短路径
操作系统
Select/epoll,IO多路复用,底层数据结构,epoll的几个函数,两种模式
Select/epoll 问题,网上很多抢占式调度是什么回事
进程优先级和时间分片等方面理解用户态和内核态
系统态(内核态),操作系统在系统态运行——运行操作系统程序
用户态(也称为目态),应用程序只能在用户态运行——运行用户程序
MySQL
innodb和myisam区别(事务,索引,锁。。。)
B+树和B树区别,优缺点
B树每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null。只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针,顺序访问指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针。B树和二叉查找树或者红黑色区别
聚簇索引什么特点,为什么这样,顺序查询的实现,回表查询,联合索引特性
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因大表分页查询,10亿行数据,查找第N页数据,怎么优化
根据查询的页数和查询的记录数可以算出查询的id的范围,可以使用 id between and 来查询。悲观锁和乐观锁,mysql相关锁说一下
说下概念,其他网上找:
乐观锁( Optimistic Locking):对加锁持有一种乐观的态度,即先进行业务操作,不到最后一步不进行加锁,”乐观”的认为加锁一定会成功的,在最后一步更新数据的时候再进行加锁。
悲观锁(Pessimistic Lock):悲观锁对数据加锁持有一种悲观的态度。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。如何分库分表
1)垂直分表
也就是“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
2)垂直分库
垂直分库针对的是一个系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。切分后,要放在多个服务器上,提高性能。
3)水平分库分表
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
Redis
几种数据结构(list,set,zset,geohash,bitmap)实现原理
pipline用来干嘛
pipeline的作用是将一批命令进行打包,然后发送给服务器,服务器执行完按顺序打包返回。事务
redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。备份(aof/rdb)原理,哪些参数可调
RDB是根据指定的规则定时将内存中的数据备份到硬盘上,AOF是在每次执行命令后命令本身记录下来,所以RDB的备份文件是一个二进制文件,而AOF的备份文件是一个文本文件。至于调参,网上可找。网络模型
redis网络模型,网上找,需要理解。为什么单线程就能hold住几万qps
I/O复用,Reactor 设计模式热点key怎么处理
- 热key加载到系统内存中,直接从系统内存中取,而不走到redis层。
- redis集群,热点备份分布到集群中,避免单台redis集中访问。
一致性hash解决什么问题
redis集群和负载均衡redis集群(主从,高可用,扩展节点)
Kafka
消息是否按照时间有序,kafka分区的数据是否有序,如何保证有序
不保证按时间有序,主题在单个分区是有序的。如何保证有序?
kafka topic 只设置一个分区,或者producer将消息发送到指定分区Kafka为什么吞吐量高
1)顺序读写
kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能,顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写。
2)零拷贝
利用Linux kernel”零拷贝(zero-copy)”系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”。
3)分区
kafka中的topic中的内容可以被分为多分区存在,每个分区又分为多个段,所以每次操作都是针对一小部分做操作,很轻便,并且增加并行操作的能力。
4)批量发送
kafka允许进行批量发送消息,producter发送消息的时候,可以将消息缓存在本地,等到了固定条件发送到kafka等消息条数到固定条数,一段时间发送一次。
5)数据压缩
Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩。压缩的好处就是减少传输的数据量,减轻对网络传输的压力kafka的存储模型
Kafka消费者多个group消费同一个topic,会重复消费吗?
项目问题
遇到过内存溢出吗?怎么解决
主要了解有没有处理过内存泄漏导致的问题,C/C++定位内存泄漏问题;Golang和JAVA主要与GC的工作机制有关,堆内存一直增长,导致应用内存溢出等。布隆过滤器怎么设置m,n,k的值,怎么合理安排key(用户和item越来越多,怎么保证内存不会爆)
m,n,k 网上有实践经验,可参考。item越来越多的话,进行item的拆分,拆分本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上。服务雪崩怎么处理,怎么解决保证不影响线上
限流,降级,熔断方面措施,结合后端系统架构阐述,如网关的限流和快速失败。redis和mysql数据一致性怎么保证
重点考虑业务逻辑上写和数据的流程(异常和错误处理等),结合MQ做异步重试处理。分布式锁应用场景,哪些坑
锁过期了,业务还没执行完;分布式锁,redis主从同步的坑;获取到锁后,线程异常。
Golang 里面有一堆看起来很高大上的名词,以及一些自带的工具链。
1 | brew install golang |
安装完之后,有一堆默认的配置信息,可以通过 go env 来进行查看:
1 | ╰─$ go env |
其中有几个比较重要的变量,需要注意。
GOROOT
Golang 的安装目录。本机上的 GOROOT 为:/usr/local/Cellar/go/1.14.6/libexec,它的目录结构如下:
1 | ╰─$ tree -L 1 /usr/local/Cellar/go/1.14.6/libexec |
GOPATH
同样是一个变量,且变量值的内容是一个目录,那 Golang 拿着这个变量来做什么呢?它的作用用文字说明可能比较苍白无力、甚至有点抽象,用亲手实践来看看它到底有什么用处。在本机中,GOPATH 的值(默认值:$HOME/go)为:/Users/akina/go。
1 | ╰─$ tree -L 1 /Users/akina/go |
其中会自动生成三个文件夹,它们的作用分别为:
| 文件夹 | 作用 |
|---|---|
| bin | golang 编译可执行文件存放路径,可自动生成。 |
| pkg | golang编译的.a中间文件存放路径,可自动生成。 |
| src | 源码路径。按照golang默认约定,go run,go install等命令的当前工作路径(即在此路径下执行上述命令) |
暂时将其视为一个普通的目录,拥有三个普通的文件夹。先看后面的 go build、go install、go run。
GOBIN
go install 编译存放路径。为空时则遵循“约定优于配置”原则,可执行文件放在各自 GOPATH 目录的 bin 文件夹中,即 $GOPATH/bin。
有两种情况下,bin 目录会变得没有意义。
- 当设置了有效的 GOBIN 环境变量以后,bin 目录就变得没有意义。
- 如果 GOPATH 里面包含多个工作区路径的时候,必须设置 GOBIN 环境变量,否则就无法安装 Go 程序的可执行文件。
GOPROXY
如果遇到下载不下来包的情况,可以考虑尝试设置 GOPROXY 。如下(>=1.13):
1 | go env -w GO111MODULE=on |
go build
usage: go build [-o output] [-i] [build flags] [packages]
Build compiles the packages named by the import paths, along with their dependencies, but it does not install the results.
If the arguments to build are a list of .go files from a single directory, build treats them as a list of source files specifying a single package.
When compiling packages, build ignores files that end in ‘_test.go’.
When compiling a single main package, build writes the resulting executable to an output file named after the first source file (‘go build ed.go rx.go’ writes ‘ed’ or ‘ed.exe’) or the source code directory (‘go build unix/sam’ writes ‘sam’ or ‘sam.exe’).
The ‘.exe’ suffix is added when writing a Windows executable.
When compiling multiple packages or a single non-main package, build compiles the packages but discards the resulting object, serving only as a check that the packages can be built.
go build命令默认编译当前目录下的所有 go 文件go build a.go只编译 a.go 文件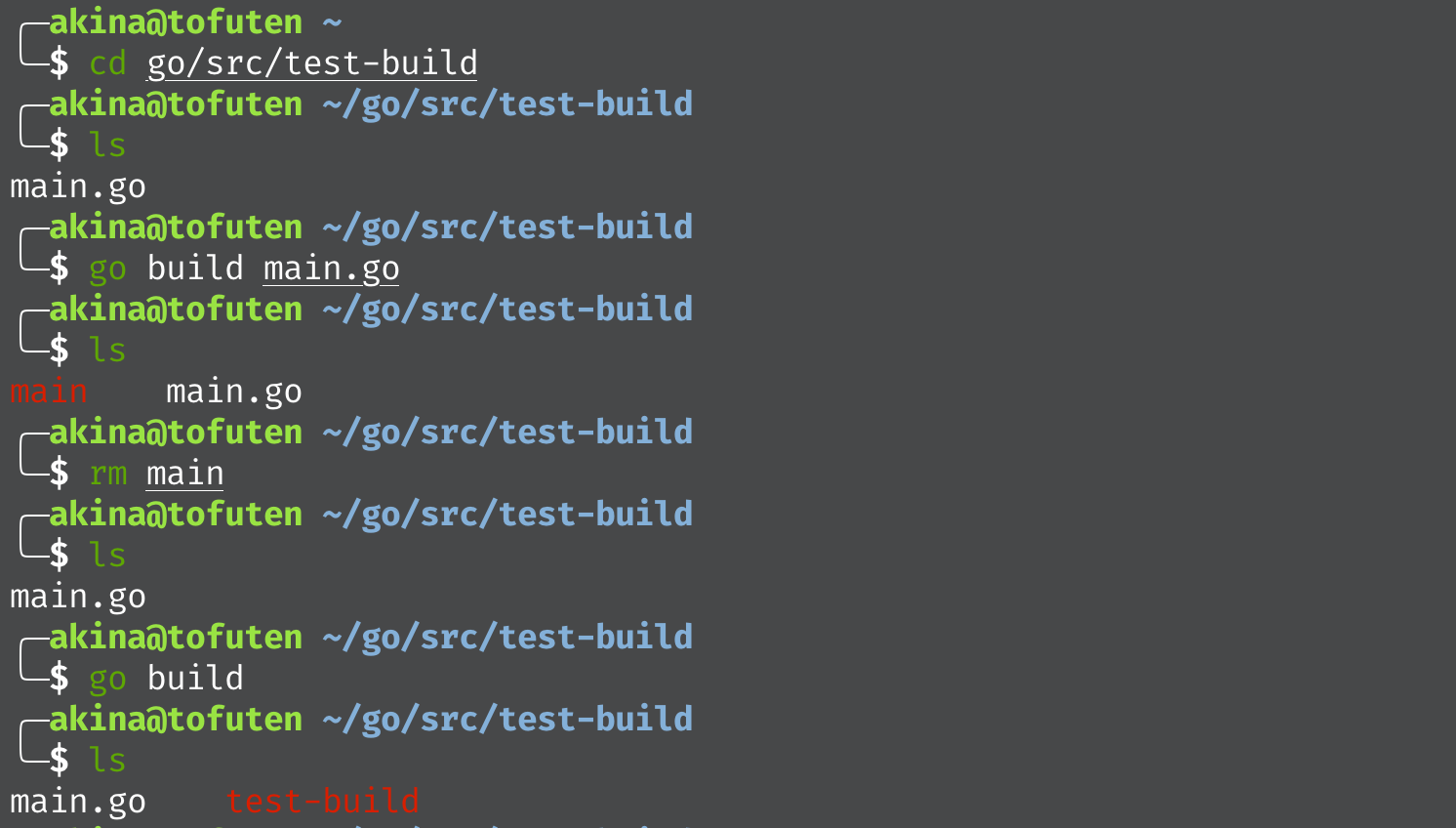
如果将编译对象换成不含有 main 函数的代码,没有任何输出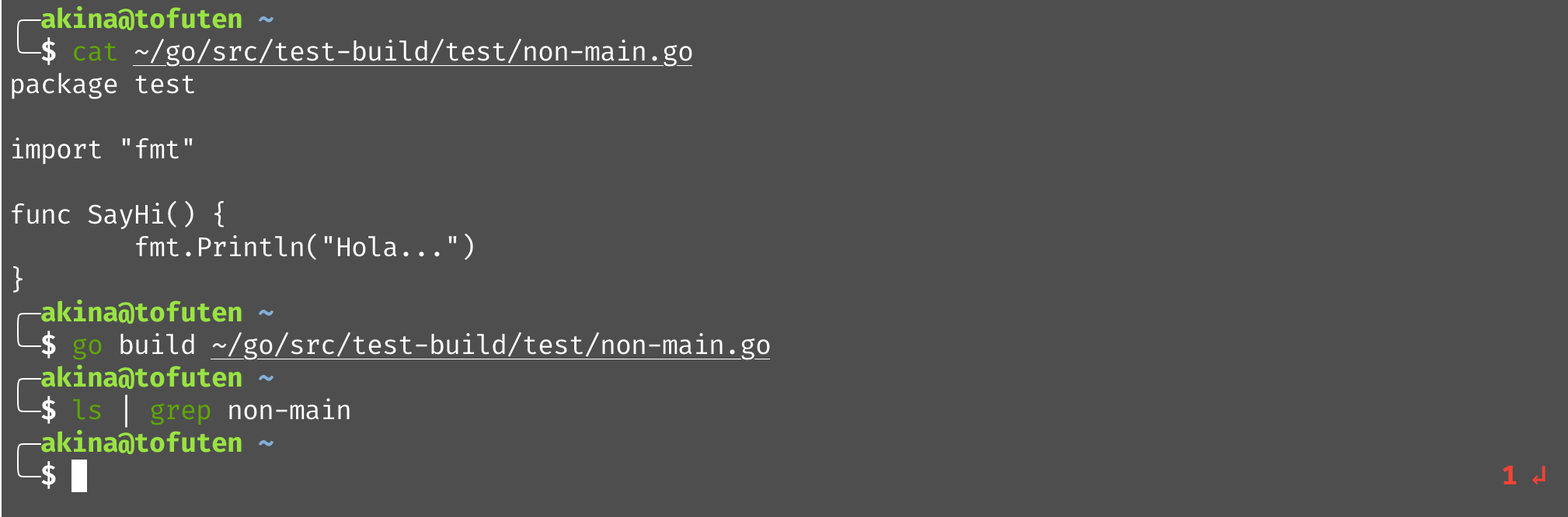
go build IMPORT-PATH编译在$GOPATH/src下面的IMPORT-PATH包,并在当前目录 (pwd)下,生成可执行文件(对含有 main 函数的代码来说)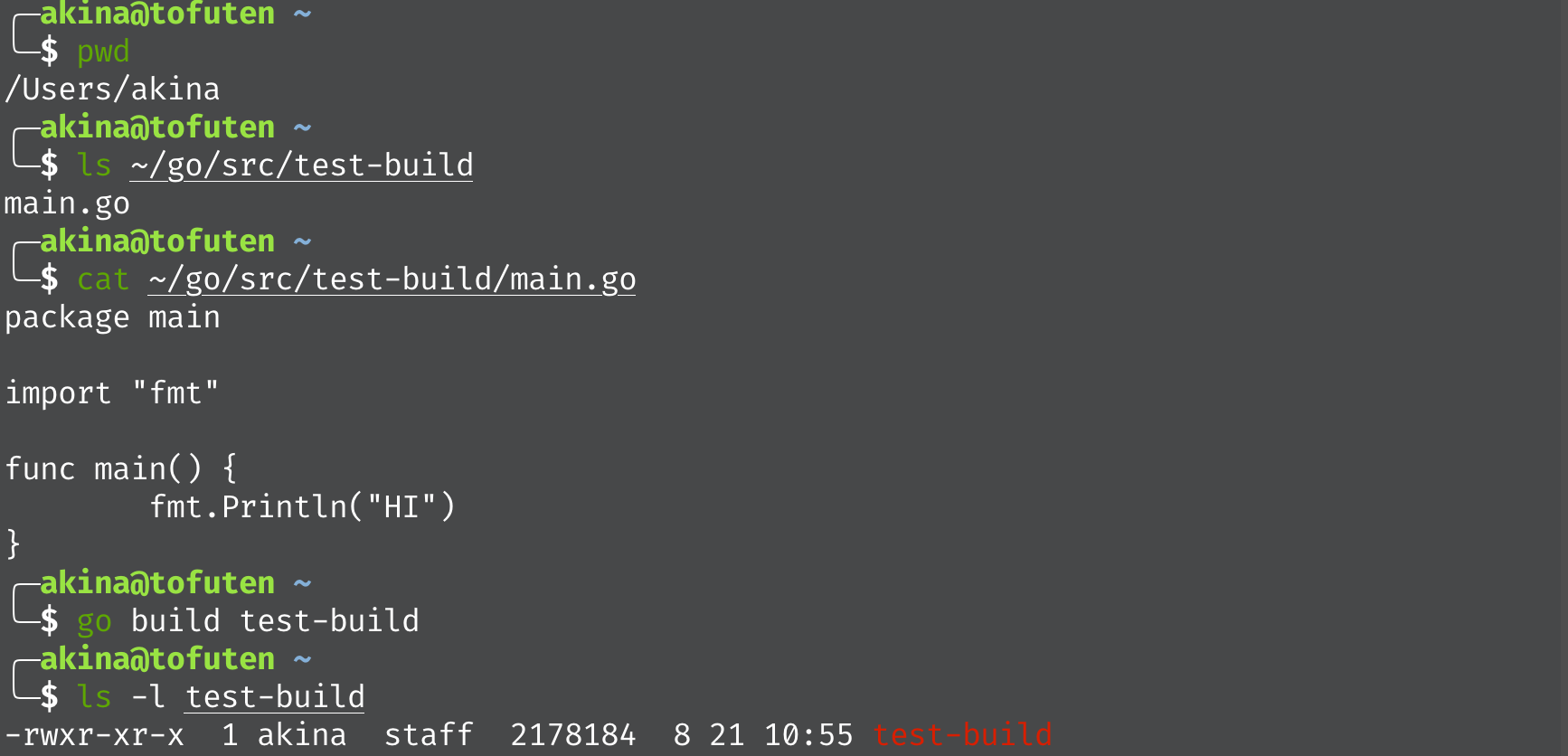
go install
它在 go build 的基础上,将编译后的可执行文件或中间文件,移动到 $GOPATH 的 bin 或 pkg 目录下。

go run
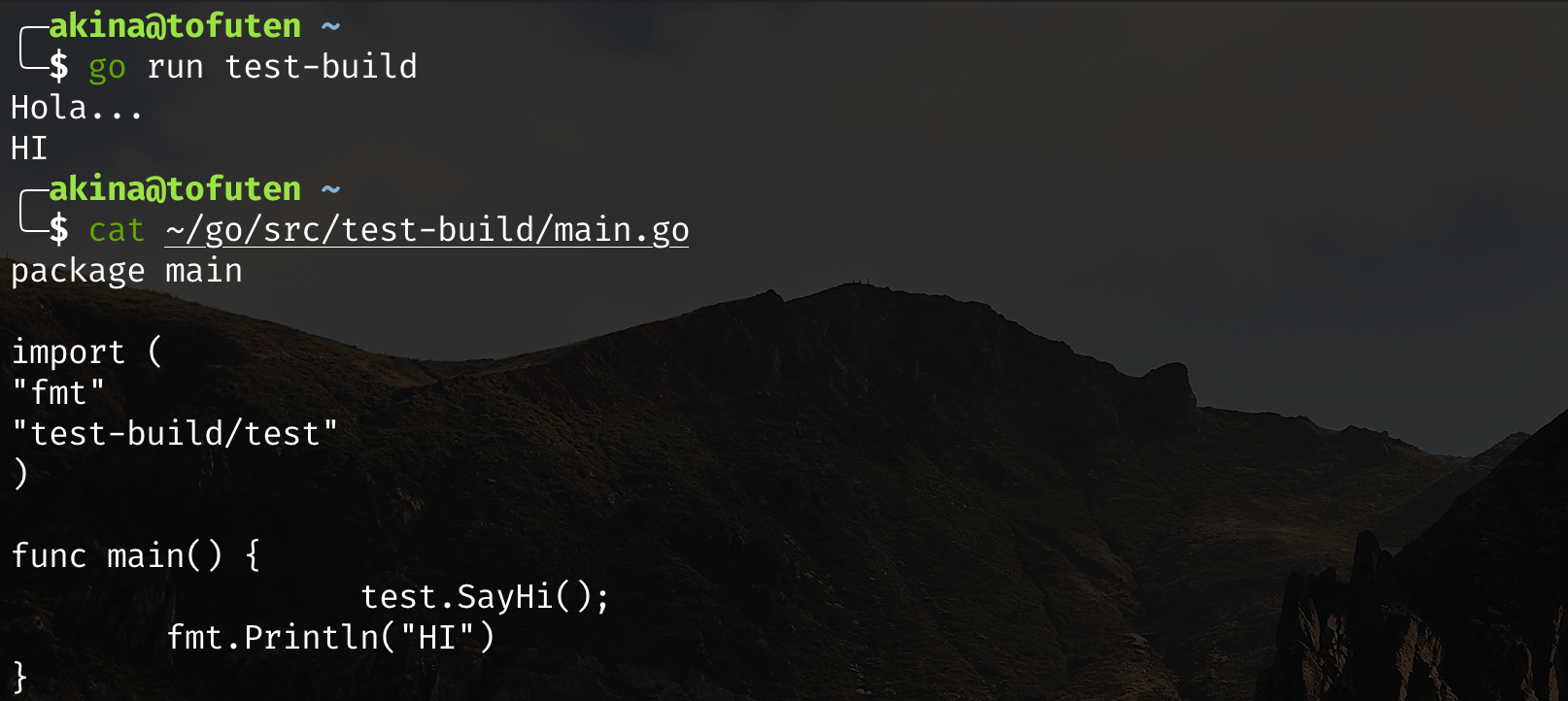
类似于 go build,可以在其它目录,仅指定在 $GOPATH 下的包名,即可运行该包内容;也可以指定一个含有 main 函数的文件。如下:

go get
用于从远程代码仓库(比如 Github 等 )上下载并安装代码包。下载源码包的go工具会自动根据不同的域名调用不同的源码工具,对应关系如下:
| 仓库 | 源码工具 |
|---|---|
| BitBucket | Mercurial Git |
| GitHub | Git |
| Google Code Project Hosting | Git, Mercurial, Subversion |
| Launchpad | Bazaar |
它会把当前的代码包下载到 $GOPATH 中的第一个工作区的 src 目录中,并安装。
-d:只下载不安装-u:更新已下载的代码包

GoLand 中打开的 terminal 会自动将 $GOPATH/bin 添加到 PATH 变量中,导致在 GoLand 的 terminal 上可以使用通过 go get 安装的命令,在 iTerm2 上面就不行。只要在 .bashrc/.zshrc 中,将 $GOPATH/bin 添加到 PATH 变量中就可以在 iTerm2 中使用。
go fmt
将代码整理成 Golang 风格。
usage: go fmt [-n] [-x] [packages]
Fmt runs the command ‘gofmt -l -w’ on the packages named by the import paths. It prints the names of the files that are modified.
For more about gofmt, see ‘go doc cmd/gofmt’.
For more about specifying packages, see ‘go help packages’.The -n flag prints commands that would be executed.
The -x flag prints commands as they are executed.The -mod flag’s value sets which module download mode to use: readonly or vendor. See ‘go help modules’ for more.
To run gofmt with specific options, run gofmt itself.
go fmt 实际调用的是 gofmt -l -w,而 gofmt 的使用如下:
1 | usage: gofmt [flags] [path ...] |
gofmt 与 go 在同一级目录,都在 $GOROOT/bin 下: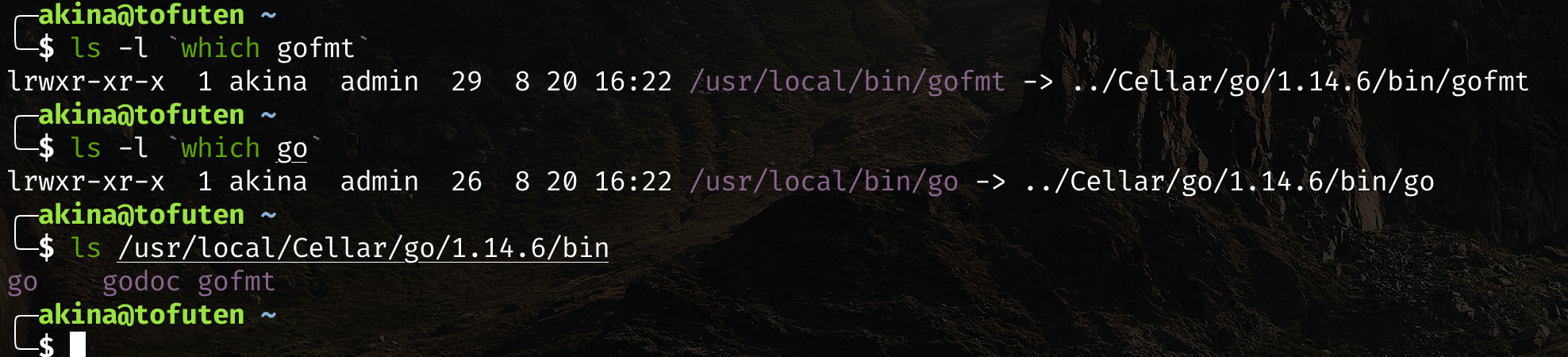
看看效果:
初始样式
执行 go fmt,可以明显看出,代码变整齐了。





