这份记录来自对项目中下单接口重构,详细记录了每一步操作、以及运用到的一些方法。力求能够最大程度将当时的过程展现出来。准备重构中的每次修改都需要进行测试,用来验证修改是否正确,因此单元测试是一个非常好的选择。单元测试单元测试中可以进行mock操作,从烦人的token中摆脱出来,做到在任何人的IDE里面
阅读更多云主测试工具在做测试,通过日志发现,其搜寻的漏洞内容包括:SQL注入、XSS等。由于其请求的频率过高,以致于nginx做转发出现502错误,造成了宕机的假象。正对这种情况,想到了以下两种处理方式。wordpress拒绝请
阅读更多什么是Servlet对一个HTTP请求的正常的处理流程是:发送HTTP请求服务端的HTTP服务器收到请求调用业务逻辑返回HTTP响应产生了下面3个问题:HTTP 服务器怎么知道要调用哪个业务逻辑,也就是 Java 类的哪个方法呢?HTTP服务器可以被设计成收到请求后,接续寻找该请求的处理逻辑,但是这
阅读更多处理后端与Android之间WebSocket连接经常断开的情况
nginx配置ws转发
1 | location ~ /(mq|ws)/ { |
添加头部信息,这两个字段表示请求服务器升级协议为WebSocket:
1 | proxy_set_header Upgrade $http_upgrade; |
默认情况下,连接将会在无数据传输60秒后关闭,proxy_read_timeout参数可以延长这个时间。源站通过定期发送ping帧以保持连接并确认连接是否还在使用。
proxy_read_timeout该指令设置与代理服务器的读超时时间。它决定了nginx会等待多长时间来获得请求的响应。 这个时间不是获得整个response的时间,而是两次reading操作的时间。
proxy_send_timeout这个指定设置了发送请求给upstream服务器的超时时间。超时设置不是为了整个发送期间,而是在两次write操作期间。 如果超时后,upstream没有收到新的数据,nginx会关闭连接
Android/微信小程序心跳机制
- 定时发送心跳包。如果发送失败,就进行重连。
- 一些关键的操作,可以在重连后,根据实际情况,立刻进行调用
参考:
https://www.xncoding.com/2018/03/12/fullstack/nginx-websocket.html
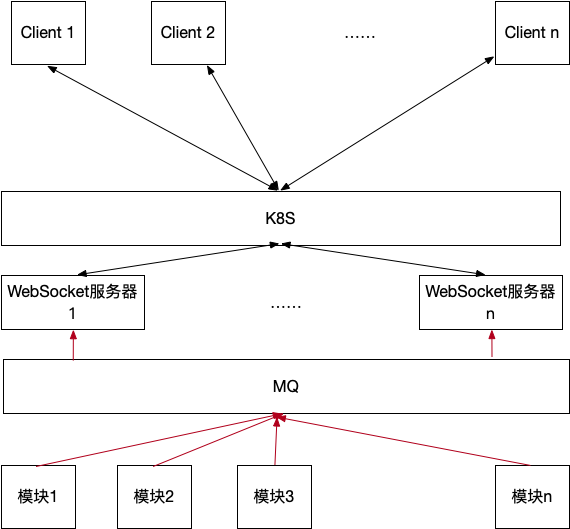
需要用到k8s进行扩展,在变更容器数量的时候,希望达到不改动代码。
遇到的问题
- Client与哪一个WS服务建立连接是不知道的
- 当需要发送WS消息时,使用URL发送给所有的WS模块不可取(一旦容器数量改变,还需要修改代码,即增加新的URL)
架构图
代码
建立连接部分
1 |
|
接收各个模块发送WS的MQ消息
1 |
|
收到各个模块的MQ消息后,提取出发送对象、发送内容,然后进行发送。如果没有找到对应客户端的连接,那么将抛弃掉该WS消息。
1 | public Map<String, Session> sessionMap = new ConcurrentHashMap<>(); |
后记
按照上述架构完成的多实例WS服务部署,可以解决前面提到的两个问题。MQ作为一个中间这的角色,发挥出了它的作用。
数据库结构及数据说明
结构
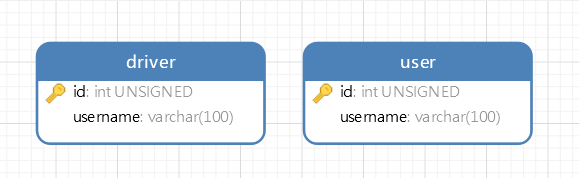
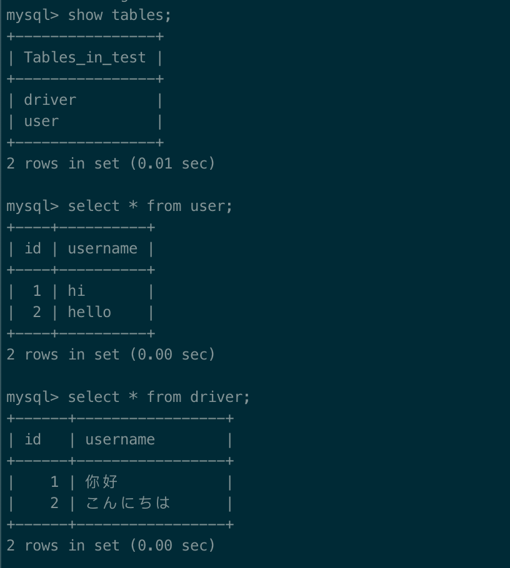
数据
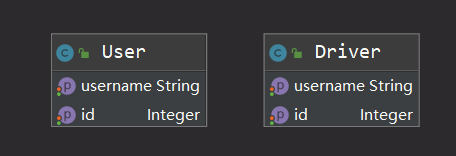
对应类
接口详细说明
获取分页数据接口
1 |
|
根据id获取用户详情
1 |
|
获取所有司机列表
1 |
|
获取所有用户的名字
1 |
|
分页相关文件说明
1 | base-service |
前言
这个注解主要是对PageHelper插件的封装,这个插件的工作流程可参考:此链接。
需要做的是在mybatis的配置文件中加入一个拦截器(拦截器的源代码链接)。MyBatis在执行query语句时,会触发该拦截器,然后得到的数据是处理过的分页后的数据。
在上述链接中有一个注意事项,如下:
什么时候会导致不安全的分页?
PageHelper 方法使用了静态的 ThreadLocal 参数,分页参数和线程是绑定的。
只要你可以保证在 PageHelper 方法调用后紧跟 MyBatis 查询方法,这就是安全的。因为 PageHelper 在 finally 代码段中自动清除了 ThreadLocal 存储的对象。
如果代码在进入 Executor 前发生异常,就会导致线程不可用,这属于人为的 Bug(例如接口方法和 XML 中的不匹配,导致找不到 MappedStatement 时),
这种情况由于线程不可用,也不会导致 ThreadLocal 参数被错误的使用。
但是如果你写出下面这样的代码,就是不安全的用法:
1 | PageHelper.startPage(1, 10); |
这种情况下由于 param1 存在 null 的情况,就会导致 PageHelper 生产了一个分页参数,但是没有被消费,这个参数就会一直保留在这个线程上。当这个线程再次被使用时,就可能导致不该分页的方法去消费这个分页参数,这就产生了莫名其妙的分页。
上面这个代码,应该写成下面这个样子:
1 | List<Country> list; |
这种写法就能保证安全。
如果你对此不放心,你可以手动清理 ThreadLocal 存储的分页参数,可以像下面这样使用:
1 | List<Country> list; |
这么写很不好看,而且没有必要。
用法
直接在方法上加上@PageAble注解,并在该方法中传入两个参数,分别为page和size,在该方法返回后,会得到一个ResultPageView封装对象,其中包含分页相关信息。
工作流程
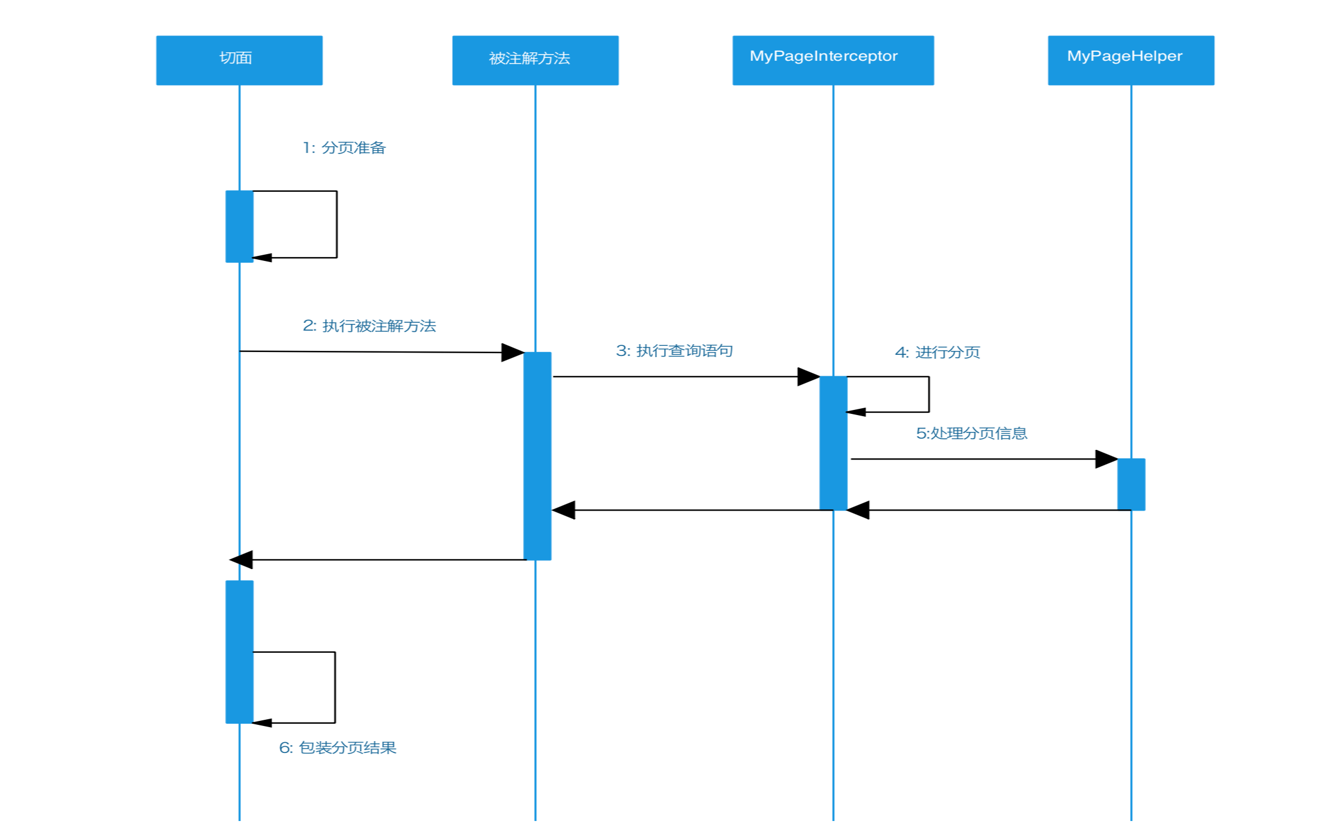
SystemAdvice定义一个切面,切点是@annotation(com.haylion.realTimeBus.annotation.PageAble)。也就是说,每个被@PageAble注解过的方法,都将执行下面的代码:
1 | private static final String PAGE_ABLE = "@annotation(com.haylion.realTimeBus.annotation.PageAble)"; |
准备工作:主要是获取page和size的值,然后调用PageHelper的startPage方法,初始化分页信息。
1 | // PageAble中page和size的默认值分别是1和20 |
进入SQL拦截器(即MyPageInterceptor):这个拦截器中主要是PageHelper执行分页的步骤,相关步骤可分为:
判断是否需要进行分页。判断的条件为
!dialect.skip(ms, parameter, rowBounds),其实现为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public boolean skip(MappedStatement ms, Object parameterObject, RowBounds rowBounds) {
if(ms.getId().endsWith(MSUtils.COUNT)){
throw new RuntimeException("在系统中发现了多个分页插件,请检查系统配置!");
}
Page page = pageParams.getPage(parameterObject, rowBounds);
if (page == null) {
return true;
} else {
//设置默认的 count 列
if(StringUtil.isEmpty(page.getCountColumn())){
page.setCountColumn(pageParams.getCountColumn());
}
autoDialect.initDelegateDialect(ms);
return false;
}
}也就是说,通过判断
Page是否为空来决定是否进行分页,Page则从本线程中获取,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14// PageHelper.java
Page page = pageParams.getPage(parameterObject, rowBounds);
//PageParams.java
public Page getPage(Object parameterObject, RowBounds rowBounds) {
Page page = PageHelper.getLocalPage();
...
}
// PageMethod.java
public static <T> Page<T> getLocalPage() {
return LOCAL_PAGE.get();
}
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();获取数据的总条数。在进入此项前,会进行判断是否需要进行总数查询。这里假设进行总数查询。从源SQL解析出获取数据总条数的代码调试如下:
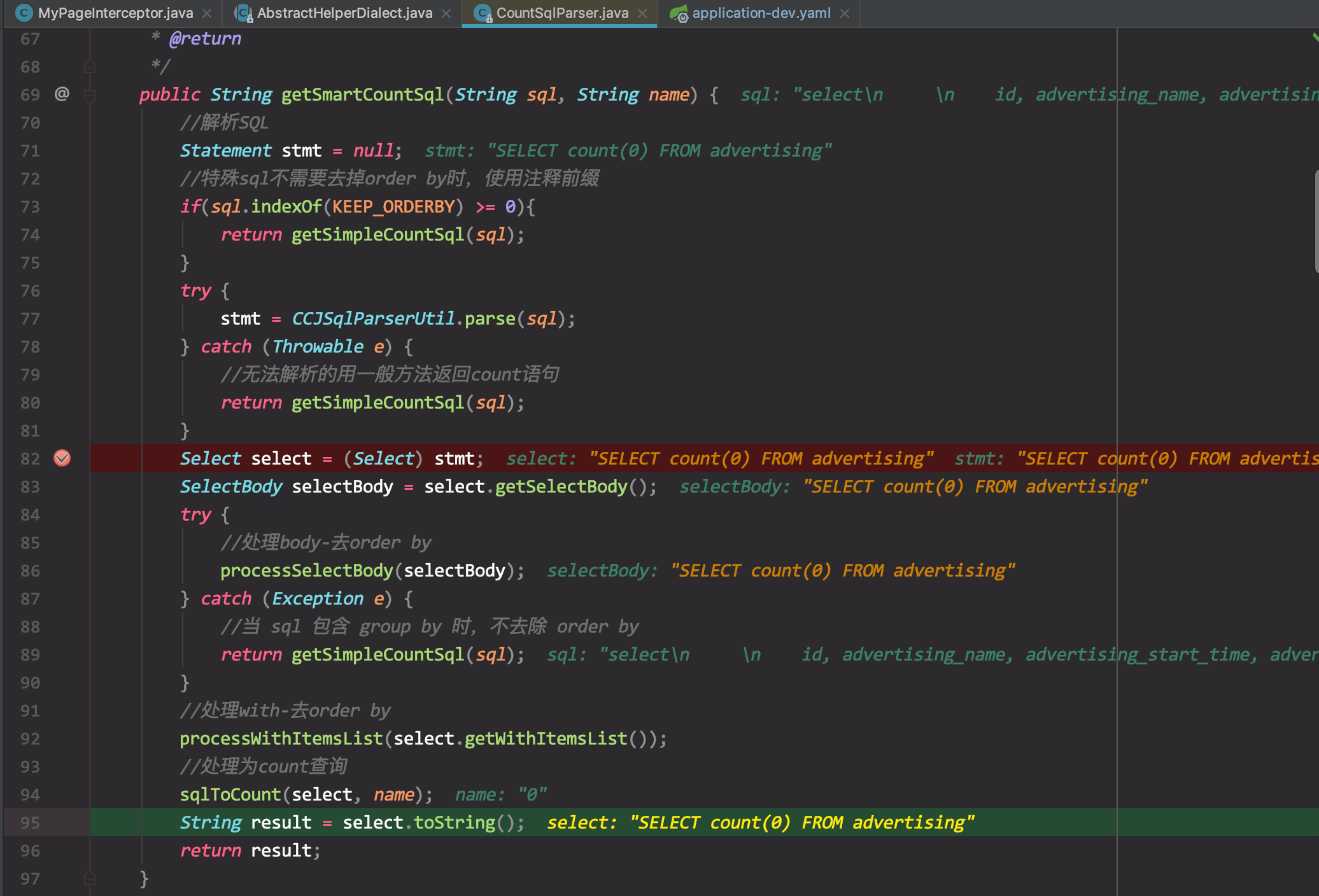
log如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
132019-06-14 09:37:31.475 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - ==> Preparing: SELECT count(0) FROM advertising
2019-06-14 09:37:31.490 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - ==> Parameters:
2019-06-14 09:37:31.507 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - <== Total: 1
2019-06-14 09:37:31.508 INFO [http-nio-8880-exec-1] c.h.r.i.s.SqlLogHandler - com.haylion.realTimeBus.dao.AdvertisingMapper.getByConditionList_COUNT:
select id, advertising_name, advertising_start_time, advertising_end_time, advertising_position, images_url, advertiser_url, advertiser_name, advertiser_id, settlement_type, settlement_price, create_time, create_user, audit_status, audit_opinion, audit_time, advertising_type from advertising
<cost time is :45 ms >
2019-06-14 09:37:31.512 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - ==> Preparing: select id, advertising_name, advertising_start_time, advertising_end_time, advertising_position, images_url, advertiser_url, advertiser_name, advertiser_id, settlement_type, settlement_price, create_time, create_user, audit_status, audit_opinion, audit_time, advertising_type from advertising LIMIT ?
2019-06-14 09:37:31.512 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - ==> Parameters: 1(Integer)
2019-06-14 09:37:31.519 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - <== Total: 1
2019-06-14 09:37:31.520 INFO [http-nio-8880-exec-1] c.h.r.i.s.SqlLogHandler - com.haylion.realTimeBus.dao.AdvertisingMapper.getByConditionList:
select id, advertising_name, advertising_start_time, advertising_end_time, advertising_position, images_url, advertiser_url, advertiser_name, advertiser_id, settlement_type, settlement_price, create_time, create_user, audit_status, audit_opinion, audit_time, advertising_type from advertising LIMIT 1
<cost time is :8 ms >
2019-06-14 09:37:31.591 INFO [http-nio-8880-exec-1] c.h.r.f.a.ResponseAdvice - Trace log is ====> {"url":"/advertising/getAdvertisingList","httpMethod":"GET","reqHeader":{"host":"192.168.12.39:8880","content-type":"application/json","user-agent":"curl/7.54.0","accept":"*/*","token":"fe20027352f8250571436f471a988b4d"},"reqParams":"page=1&size=1","requestBody":"","respParams":"{\"code\":200,\"message\":\"success\",\"data\":{\"total\":9,\"current\":1,\"pageCount\":9,\"list\":[{\"settlementType\":0,\"imagesUrl\":\"xxxxxxx\",\"advertisingName\":\"hello kitty 111\",\"advertiserName\":\"暁\",\"advertiserId\":0,\"createTimeymdhm_Str\":\"2019-06-10 17:27\",\"advertisingType\":0,\"createTime\":1560158854000,\"advertisingPosition\":0,\"auditStatus\":4,\"createUser\":1,\"id\":0,\"advertiserUrl\":\"xxxxx\",\"createTimeStr\":\"2019-06-10 17:27:34\"}]}}","startTime":1560476250978,"spendTime":592}获取完总数后,会进行判断是否有分页的必要。
分页查询。这里假设有分页的必要。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//调用方言获取分页 sql
String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);
public String getPageSql(MappedStatement ms, BoundSql boundSql, Object parameterObject, RowBounds rowBounds, CacheKey pageKey) {
String sql = boundSql.getSql();
Page page = getLocalPage();
//支持 order by
String orderBy = page.getOrderBy();
if (StringUtil.isNotEmpty(orderBy)) {
pageKey.update(orderBy);
sql = OrderByParser.converToOrderBySql(sql, orderBy);
}
if (page.isOrderByOnly()) {
return sql;
}
// 这是一个抽象方法,会根据具体的数据库,调用不同的实现方法,来在原SQL语句上,加上对应的分页语句
return getPageSql(sql, page, pageKey);
}具体支持的数据库如下:
Oracle的分页实现如下:
1
2
3
4
5
6
7
8
9
10
11//
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 120);
sqlBuilder.append("SELECT * FROM ( ");
sqlBuilder.append(" SELECT TMP_PAGE.*, ROWNUM ROW_ID FROM ( ");
sqlBuilder.append(sql);
sqlBuilder.append(" ) TMP_PAGE WHERE ROWNUM <= ? ");
sqlBuilder.append(" ) WHERE ROW_ID > ? ");
return sqlBuilder.toString();
}MySQL的分页实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
if (page.getStartRow() == 0) {
sqlBuilder.append(" LIMIT ? ");
} else {
sqlBuilder.append(" LIMIT ?, ? ");
}
pageKey.update(page.getPageSize());
return sqlBuilder.toString();
}保存分页查询后的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// resultList是分页查询后的数据列表
// afterPage的返回值是有两种情况,但是都可以被转成List
return dialect.afterPage(resultList, parameter, rowBounds);
// dialect.afterPage()方法
public Object afterPage(List pageList, Object parameterObject, RowBounds rowBounds) {
//这个方法即使不分页也会被执行,所以要判断 null
AbstractHelperDialect delegate = autoDialect.getDelegate();
if(delegate != null){
return delegate.afterPage(pageList, parameterObject, rowBounds);
}
return pageList;
}
// delegate.afterPage()方法
public Object afterPage(List pageList, Object parameterObject, RowBounds rowBounds) {
Page page = getLocalPage();
if (page == null) {
return pageList;
}
page.addAll(pageList);
if (!page.isCount()) {
page.setTotal(-1);
} else if ((page.getPageSizeZero() != null && page.getPageSizeZero()) && page.getPageSize() == 0) {
page.setTotal(pageList.size());
} else if(page.isOrderByOnly()){
page.setTotal(pageList.size());
}
return page;
}其实这里有一个问题是,如果delegate不为空,那么返回的是
Page,但是我们在调用xxxxxMapper的查询方法之后,返回值基本上是List,与我们的常识并不符合。那Page是什么呢?它不只是包含分页信息的基本类,它继承自ArrayList。1
2
3public class Page<E> extends ArrayList<E> implements Closeable {
// ...
}在return后,还会执行finally中的处理代码,即
com.haylion.realTimeBus.interceptor.sql.MyPageHelper的afterAll()方法。其中实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// com.haylion.realTimeBus.interceptor.sql.MyPageHelper.afterAll()
// 这个方法是我们自定义的方法,用来处理执行完前面所述的切点后,保留分页信息,进行再次封装
public void afterAll() {
Page<Object> localPage = getLocalPage();
// 删除分页信息
super.afterAll();
// 设置回本线程中
setLocalPage(localPage);
}
// super.afterAll()。这个方法可以简单理解成,清楚掉本线程中的分页信息
public void afterAll() {
//这个方法即使不分页也会被执行,所以要判断 null
AbstractHelperDialect delegate = autoDialect.getDelegate();
if (delegate != null) {
delegate.afterAll();
autoDialect.clearDelegate();
}
clearPage();
}
// 移除本地变量
public static void clearPage() {
LOCAL_PAGE.remove();
}经过上述的过程,
MyPageInterceptor执行完毕,分页信息存储在本线程中,然后回到切面处理。
切面收尾工作(回到SystemAdvice):
1 | private Object after(Object obj) { |
至此,备注解方法将返回ResultPageView对象,经过包装后,也就是我们常看到的分页格式:
1 | { |
局限
这就限定了在一个被PageAble注解了的方法上,只能执行一条查询。如果对于一个到来的请求,需要进行两次或以上的查询,并且某一条查询需要分页的情况,如果所有的查询都放在被PageAble注解的方法下,执行会出现问题(出现不必要的分页操作)。但是可以通过组装的形式,完成该项需求。
bug说明
当一条线程,执行被PageAble注解过的方法时,线程中会保存Page信息。
如果切面没有执行完,会导致Page在处理完改请求后,继续留存在该线程中。

当一条含有Page对象的线程,处理某个不分页、但需进行查询的请求时,会导致该查询进行分页,并且会将Page对象中的之前查询得到的数据一并返回。
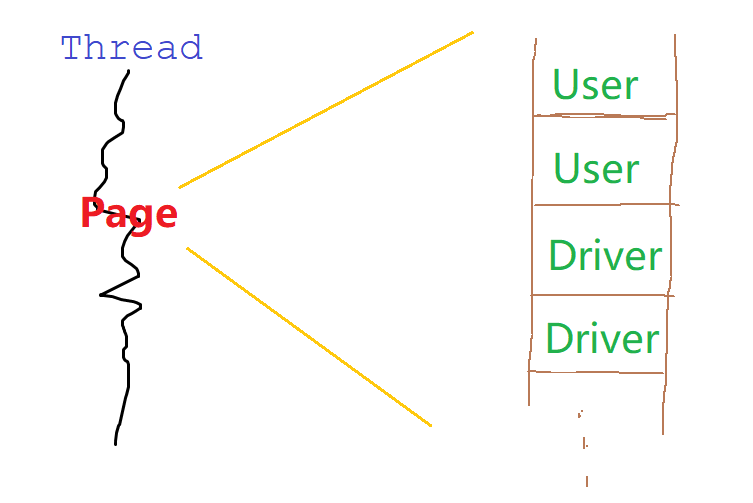
四个请求的各自功能
在线程中留下分页标志。
curl -s localhost:8880/test/get-system-busy\?page=1\&size=2 | jq --indent 4在分页后的数据列表中,加入数据。
curl -s localhost:8880/test/get-all-drivers | jq --indent 4出错情况1:TooManyResultsException。
curl -s localhost:8880/test/get-one-user\?id=1 | jq --indent 4出错情况2 & 3:ClassCastException & 数据累积。
curl -s localhost:8880/test/get-username-list | jq --indent 4
PPT内容
略
参考:http://www.site-digger.com/tools/mct2latlng.html
这里的转换是直接调用百度地图SDK中的API,通过对其中JavaScript源代码的执行跟踪,提取出其中的墨卡托坐标转百度经纬度坐标的代码如下:
Java版本:
1 |
|
Python版本:
1 | xPi = 3.14159265358979324 * 3000.0 / 180.0 |
效果展示:
1 | // 测试代码 |
打开高德地图多边形绘制DEMO示例,然后将上述代码的对应执行结果,以正确的形式粘贴到DEMO代码的相应地方: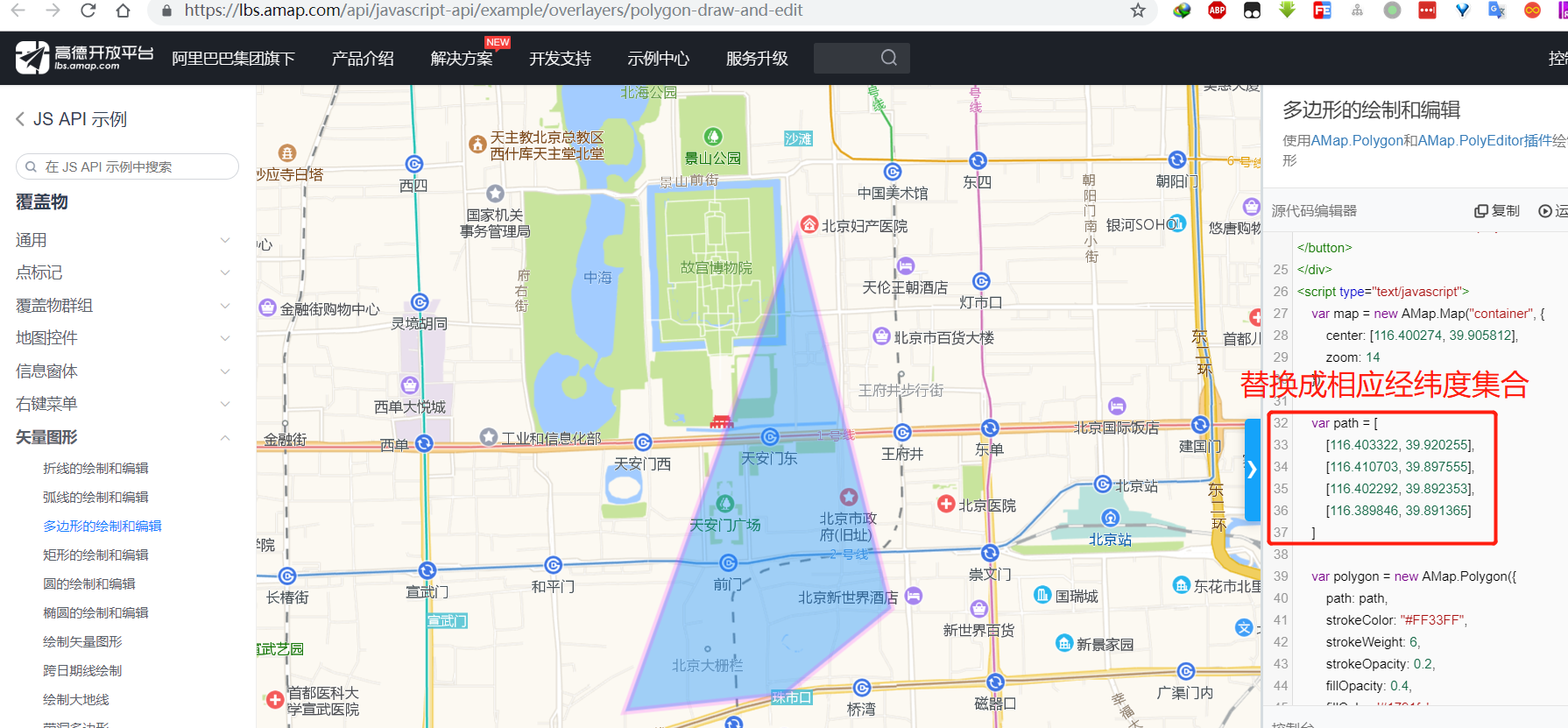
然后点击运行,查看结果:
百度墨卡托坐标转成百度经纬度坐标后,在高德地图上展示情况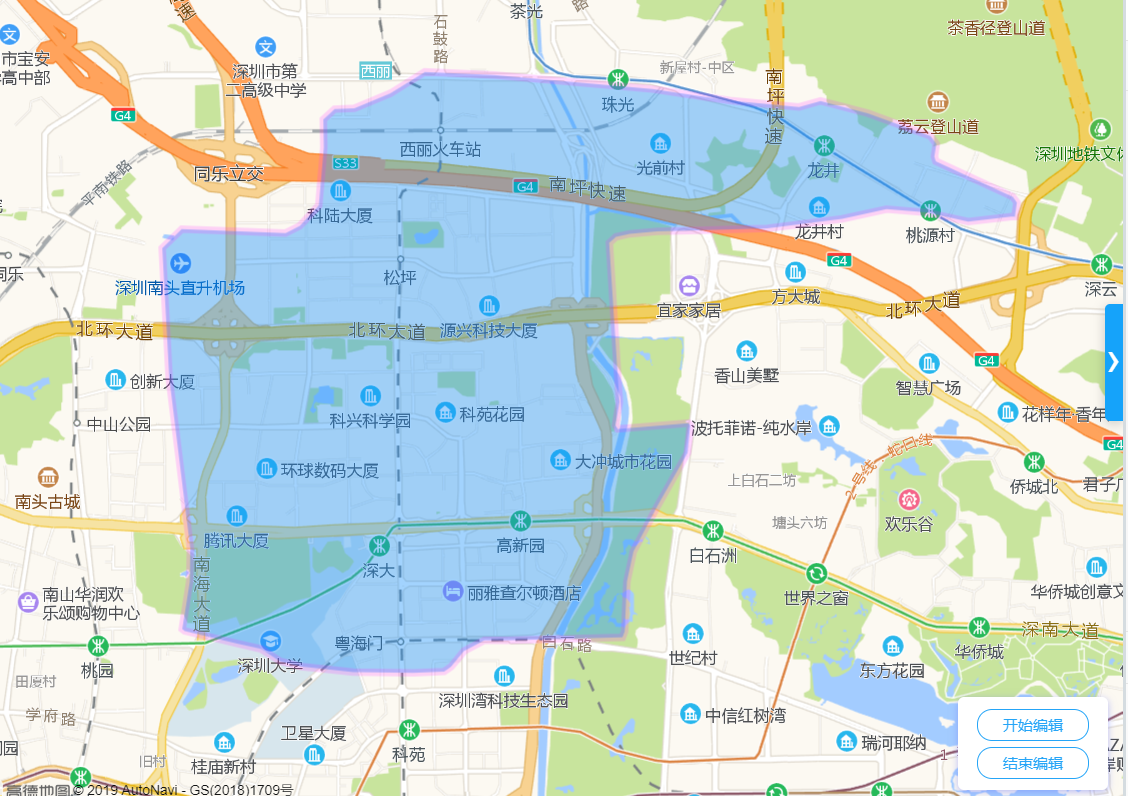
将百度坐标转换成高德地图坐标后在高德地图中的展示情况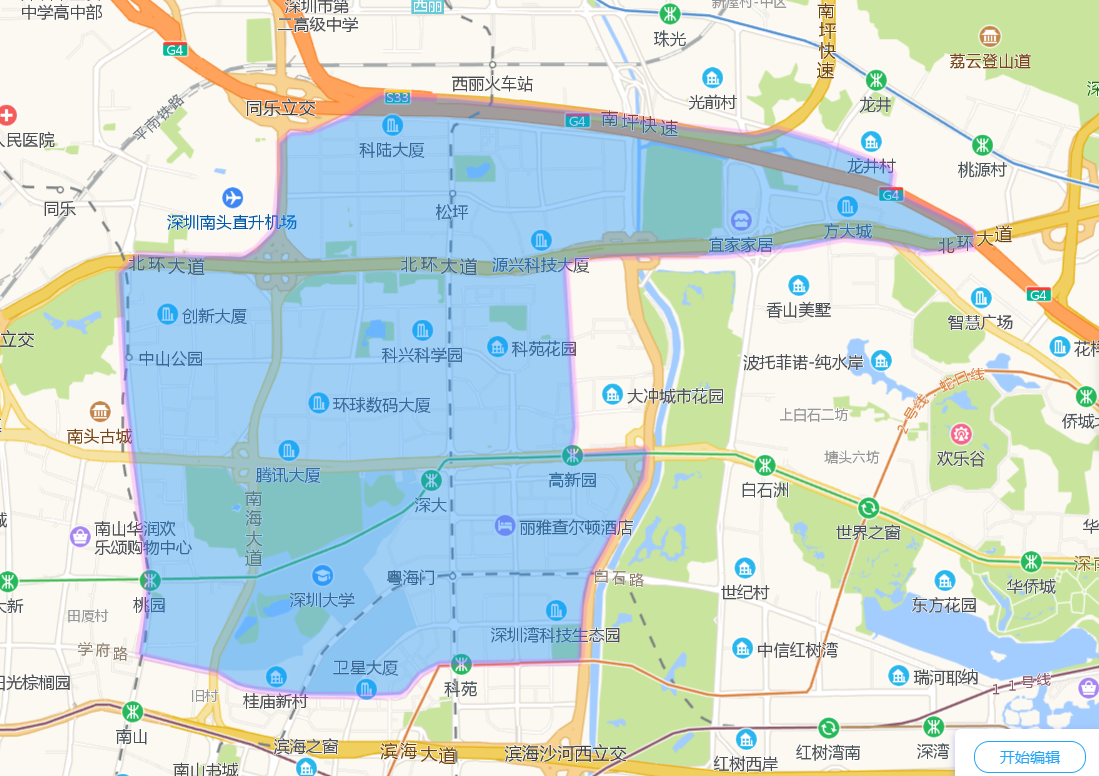
百度地图原始数据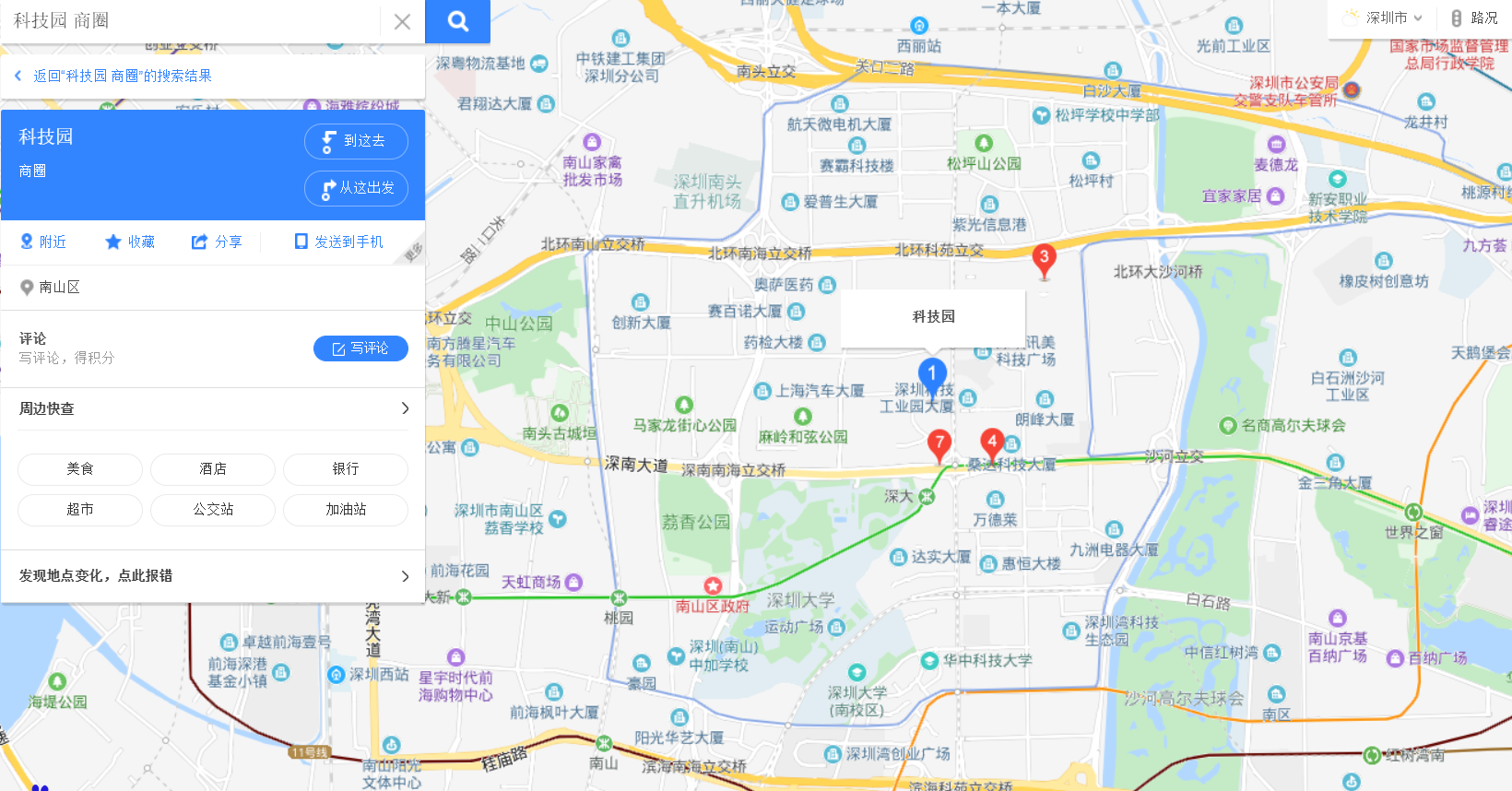
后面经过尝试、发现差距并不是特别大,已使用这种方法进行坐标转换
模块概览
base-service
1 | base-service |
common-service
1 | base-support/common-service |
facade-service
1 | base-support/facade-service |
主要功能
拦截鉴权— ActionInterceptor
本项目中鉴定登录状态的方式为:在请求头部加入token,然后在拦截器ActionInterceptor.java中,从请求头部中取出token,并依据token来获取userId,然后将userId插入到头部中;如果上述过程,出现token是null、userId是null,那么该请求将被视为非登录状态,将不会传递到Controller层。
如何跳过校验?
在Controller的方法上,加上@AnonymousSupport注解,在ActionInterceptor.java中,会通过Method方法,获取@AnonymousSupport,如果存在就不进行后面的登录状态校验。
1 | HandlerMethod handlerMethod = (HandlerMethod) o; |
如何将userId添加到请求的headers中?
通过token在Redis中获取到userId后,如何在headers中添加userId键值对,略微繁杂,但是目的很单纯。设置值的代码如下所示:
1 | MimeHeaders mimeHeaders = (MimeHeaders) headers.get(coyoteRequest); |
在前面,有一个对request类型进行判断的语句,主要目的是为了避免NullPointerException,因为后面通过反射获取属性的时候,可能会由于request类型不同,而获取不到对应的Field,从而导致出现异常。
1 | if (request instanceof StandardMultipartHttpServletRequest) { |
请求日志
主要的任务是将请求所有的参数(如:url中的参数、方法、headers、requestBody等)都以直观的方式打印出来。它的主要流程有两处:
拦截器
TraceCopyFilter初始化RequestWrapper时,将请求所有的信息都保存到HttpTraceLog中,并通过LogTrace保存在当前线程中(利用ThreadLocal)。1
2
3
4
5
6
7LogTrace.get().setStartTime(System.currentTimeMillis());
LogTrace.get().setHttpMethod(request.getMethod());
LogTrace.get().setUrl(requestURI);
LogTrace.get().setReqParams(request.getQueryString());
LogTrace.get().setReqHeader(getHeaderMap(request));
// ...
LogTrace.get().setRequestBody(sb.toString());在
ResponseAdvice包装完返回信息之后,会在finally中将所有的请求信息,通过log的形式打印出来。打印完成后,会通过LogTrace将请求的信息从本线程中移除掉(利用ThreadLocal)。1
2
3
4
5
6
7
8
9try {
LogTrace.get().setSpendTime(System.currentTimeMillis() - LogTrace.get().getStartTime());
LogTrace.get().setRespParams(objectMapper.writeValueAsString(result));
log.info("Trace log is ====> " + objectMapper.writeValueAsString(LogTrace.get()));
} catch (Exception e) {
log.error("Trace log error : ", e);
} finally {
LogTrace.clearAll();
}
其中获取body时,直接使用IO流,把数据保存到变量requestBody中,代码如下:
1 | // request == null 是一个标志位 |
但是收到POST请求时(参考链接),会产生两个TCP数据包(并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次),即浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。所以在拿POST请求中body时,如果直接读出来,可能导致后面框架再去读的时候,出现读不了的情况,所以在RequestWrapper中,重写了getInputStream方法,在request不为空,即没有读取过body(这种情况就是在上传文件的情况),直接以requestBody作为输入流,提供给框架读取,上述问题便解决了。代码如下:
1 |
|
SQL日志
SqlLogHandler在SQL拦截中进行调用,它主要做的工作是把SQL中的?替换成实际的值,并打印出执行时间。
API统一的返回数据
在ResponseAdvice中,会将数据都转化成JsonView的形式。
其中有一个问题,就是当返回的类型是String的时候,不能包装String类型,只能以String的形式返回。这是由于整个SpringMVC框架的设计问题。假设有如下业务代码:
1 |
|
这时候的返回值如下:
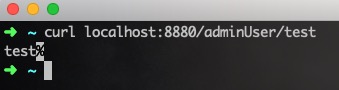
因为是以String的类型直接返回了,上述的返回格式也是理所当然。但是如果将String包装成JsonView,然后返回会怎么样?修改ResponseAdvice如下:
1 | if (o instanceof JsonView ) { |
这时候如果再次访问,程序会报错如下:

报错的堆栈信息如下:
1 | java.lang.ClassCastException: com.haylion.realTimeBus.facade.view.JsonView cannot be cast to java.base/java.lang.String |
上面的错误简单理解,类型转换错误,也就是需要一个String,但是却收到了一个JsonView。需要的String是我们在Controller中返回的类型,然而实际收到的JsonView是在ResponseAdvice中包装后返回的。为什么这样的原因是:与ResponseAdvice执行的时机有关。在AbstractMessageConverterMethodProcessor.java文件的writeWithMessageConverters()方法中,调试数据如下:
确定返回类型:
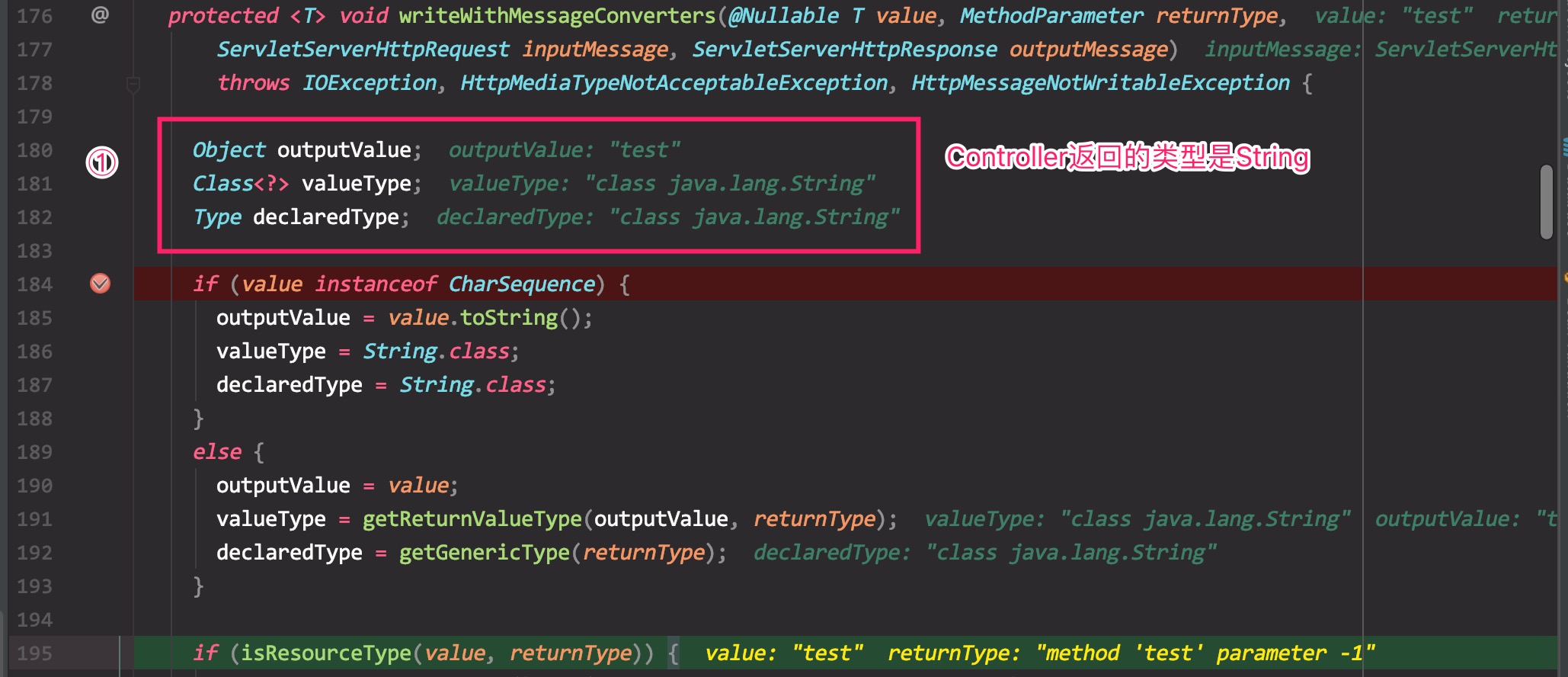
确定可用的转换器,然后执行ResponseAdvice:
在ResponseAdvice执行前,SpringMVC会根据Controller的返回类型,确定一个AbstractHttpMessageConverter,由于在Controller中返回类型为String,所以这里为StringHttpMessageConverter,也就是说,它是用来转换一个String类型的转换器。等转换器确定好了之后,会执行ResponseAdvice中的处理方法,将String转换成JsonView。
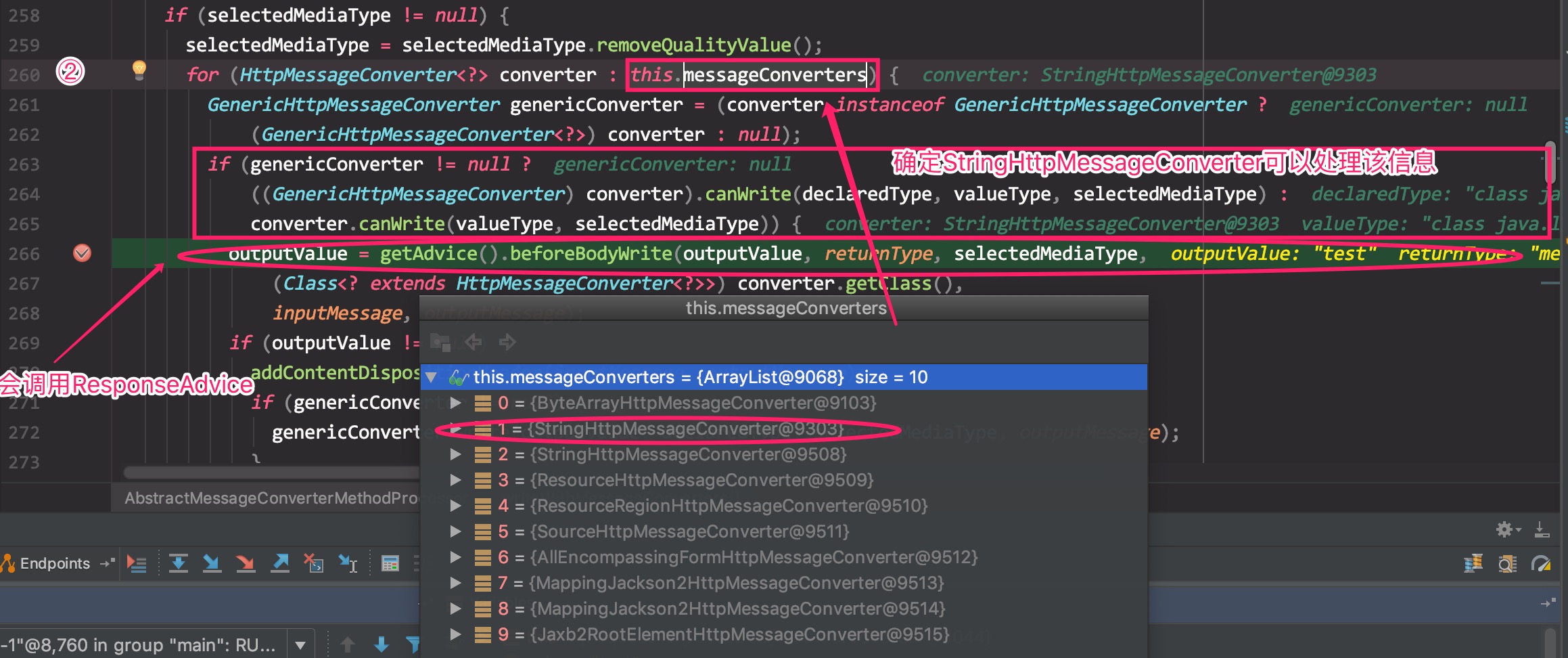
写入返回数据:
忽略掉其他代码,直接进入出现错误的代码,在AbstractHttpMessageConverter中的addDefaultHeaders()方法中,需要在头部获取整个请求的大小,即调用getContentLength()方法。
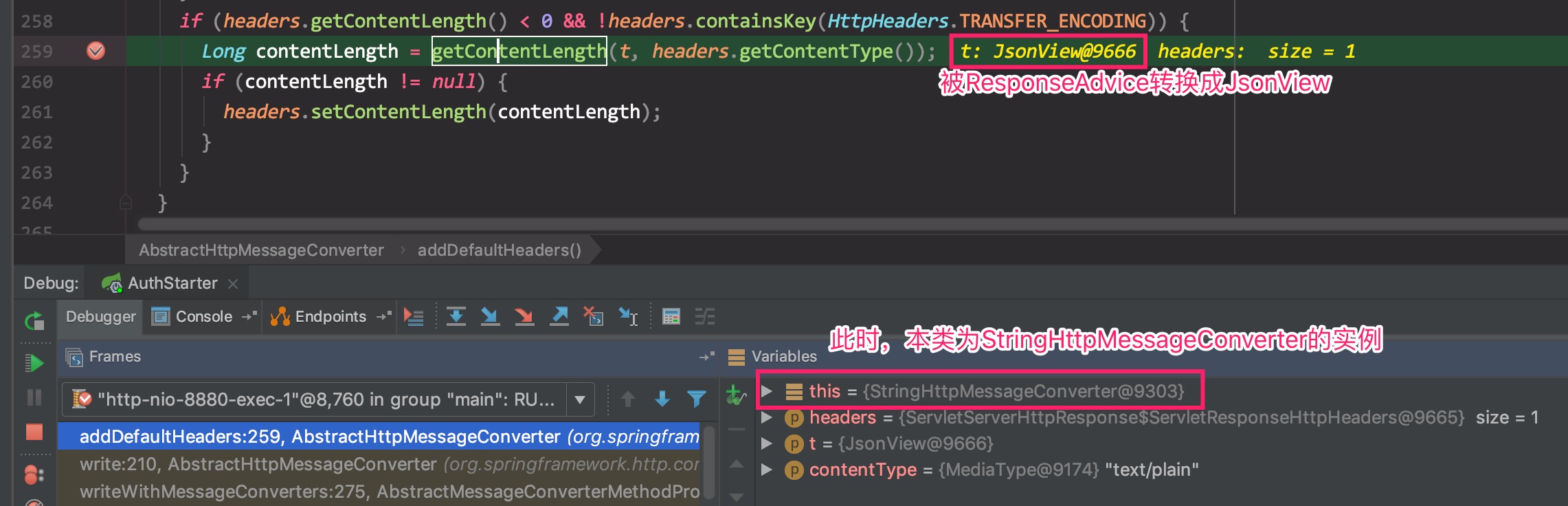
它是一个期望被子类覆盖的方法,默认的实现如下:
1 | protected Long getContentLength(T t, MediaType contentType) throws IOException { |
这时候应该直接看StringHttpMessageConverter中的getContentLength()方法如下:
1 |
|
然后再将转换后的JsonView作为抽象函数getContentLength()(这时就是StringHttpMessageConverter的该函数)的第一个参数,如下:
1 | protected Long getContentLength(String str, MediaType contentType) { |
第一个参数为String,但是实际上是JsonView。因此,ClassCastException在所难免。在ResponseAdvice中,将String直接返回,可以避免出现这种不太好修复的错误。
替代办法:
但是如果非要返回String类型,并且需要包装成JsonView形式,可以考虑直接在Controller中将String包装成JsonView,然后返回,如下:
1 |
|
结果:

异常处理
参看ExceptionHandle具体实现及写法、以及相关源码注释。
分页–PageHelper
用法
直接在方法上加上@PageAble注解,并在该方法中传入两个参数,分别为page和size,在该方法返回后,会得到一个ResultPageView封装对象,其中包含分页相关信息。
工作流程
SystemAdvice定义一个切面,切点是@annotation(com.haylion.realTimeBus.annotation.PageAble)。也就是说,每个被@PageAble注解过的方法,都将执行下面的代码:
1 | private static final String PAGE_ABLE = "@annotation(com.haylion.realTimeBus.annotation.PageAble)"; |
准备工作:主要是获取page和size的值,然后调用PageHelper的startPage方法,初始化分页信息。
1 | // PageAble中page和size的默认值分别是1和20 |
进入SQL拦截器(即MyPageInterceptor):这个拦截器中主要是PageHelper执行分页的步骤,相关步骤可分为:
判断是否需要进行分页。判断的条件为
!dialect.skip(ms, parameter, rowBounds),其实现为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public boolean skip(MappedStatement ms, Object parameterObject, RowBounds rowBounds) {
if(ms.getId().endsWith(MSUtils.COUNT)){
throw new RuntimeException("在系统中发现了多个分页插件,请检查系统配置!");
}
Page page = pageParams.getPage(parameterObject, rowBounds);
if (page == null) {
return true;
} else {
//设置默认的 count 列
if(StringUtil.isEmpty(page.getCountColumn())){
page.setCountColumn(pageParams.getCountColumn());
}
autoDialect.initDelegateDialect(ms);
return false;
}
}也就是说,通过判断
Page是否为空来决定是否进行分页,Page则从本线程中获取,如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14// PageHelper.java
Page page = pageParams.getPage(parameterObject, rowBounds);
//PageParams.java
public Page getPage(Object parameterObject, RowBounds rowBounds) {
Page page = PageHelper.getLocalPage();
...
}
// PageMethod.java
public static <T> Page<T> getLocalPage() {
return LOCAL_PAGE.get();
}
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();获取数据的总条数。在进入此项前,会进行判断是否需要进行总数查询。这里假设进行总数查询。从源SQL解析出获取数据总条数的代码调试如下:
log如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
132019-06-14 09:37:31.475 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - ==> Preparing: SELECT count(0) FROM advertising
2019-06-14 09:37:31.490 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - ==> Parameters:
2019-06-14 09:37:31.507 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - <== Total: 1
2019-06-14 09:37:31.508 INFO [http-nio-8880-exec-1] c.h.r.i.s.SqlLogHandler - com.haylion.realTimeBus.dao.AdvertisingMapper.getByConditionList_COUNT:
select id, advertising_name, advertising_start_time, advertising_end_time, advertising_position, images_url, advertiser_url, advertiser_name, advertiser_id, settlement_type, settlement_price, create_time, create_user, audit_status, audit_opinion, audit_time, advertising_type from advertising
<cost time is :45 ms >
2019-06-14 09:37:31.512 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - ==> Preparing: select id, advertising_name, advertising_start_time, advertising_end_time, advertising_position, images_url, advertiser_url, advertiser_name, advertiser_id, settlement_type, settlement_price, create_time, create_user, audit_status, audit_opinion, audit_time, advertising_type from advertising LIMIT ?
2019-06-14 09:37:31.512 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - ==> Parameters: 1(Integer)
2019-06-14 09:37:31.519 DEBUG [http-nio-8880-exec-1] o.a.i.l.j.BaseJdbcLogger - <== Total: 1
2019-06-14 09:37:31.520 INFO [http-nio-8880-exec-1] c.h.r.i.s.SqlLogHandler - com.haylion.realTimeBus.dao.AdvertisingMapper.getByConditionList:
select id, advertising_name, advertising_start_time, advertising_end_time, advertising_position, images_url, advertiser_url, advertiser_name, advertiser_id, settlement_type, settlement_price, create_time, create_user, audit_status, audit_opinion, audit_time, advertising_type from advertising LIMIT 1
<cost time is :8 ms >
2019-06-14 09:37:31.591 INFO [http-nio-8880-exec-1] c.h.r.f.a.ResponseAdvice - Trace log is ====> {"url":"/advertising/getAdvertisingList","httpMethod":"GET","reqHeader":{"host":"192.168.12.39:8880","content-type":"application/json","user-agent":"curl/7.54.0","accept":"*/*","token":"fe20027352f8250571436f471a988b4d"},"reqParams":"page=1&size=1","requestBody":"","respParams":"{\"code\":200,\"message\":\"success\",\"data\":{\"total\":9,\"current\":1,\"pageCount\":9,\"list\":[{\"settlementType\":0,\"imagesUrl\":\"xxxxxxx\",\"advertisingName\":\"hello kitty 111\",\"advertiserName\":\"暁\",\"advertiserId\":0,\"createTimeymdhm_Str\":\"2019-06-10 17:27\",\"advertisingType\":0,\"createTime\":1560158854000,\"advertisingPosition\":0,\"auditStatus\":4,\"createUser\":1,\"id\":0,\"advertiserUrl\":\"xxxxx\",\"createTimeStr\":\"2019-06-10 17:27:34\"}]}}","startTime":1560476250978,"spendTime":592}获取完总数后,会进行判断是否有分页的必要。
分页查询。这里假设有分页的必要。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//调用方言获取分页 sql
String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);
public String getPageSql(MappedStatement ms, BoundSql boundSql, Object parameterObject, RowBounds rowBounds, CacheKey pageKey) {
String sql = boundSql.getSql();
Page page = getLocalPage();
//支持 order by
String orderBy = page.getOrderBy();
if (StringUtil.isNotEmpty(orderBy)) {
pageKey.update(orderBy);
sql = OrderByParser.converToOrderBySql(sql, orderBy);
}
if (page.isOrderByOnly()) {
return sql;
}
// 这是一个抽象方法,会根据具体的数据库,调用不同的实现方法,来在原SQL语句上,加上对应的分页语句
return getPageSql(sql, page, pageKey);
}具体支持的数据库如下:
Oracle的分页实现如下:
1
2
3
4
5
6
7
8
9
10
11//
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 120);
sqlBuilder.append("SELECT * FROM ( ");
sqlBuilder.append(" SELECT TMP_PAGE.*, ROWNUM ROW_ID FROM ( ");
sqlBuilder.append(sql);
sqlBuilder.append(" ) TMP_PAGE WHERE ROWNUM <= ? ");
sqlBuilder.append(" ) WHERE ROW_ID > ? ");
return sqlBuilder.toString();
}MySQL的分页实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
if (page.getStartRow() == 0) {
sqlBuilder.append(" LIMIT ? ");
} else {
sqlBuilder.append(" LIMIT ?, ? ");
}
pageKey.update(page.getPageSize());
return sqlBuilder.toString();
}保存分页查询后的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// resultList是分页查询后的数据列表
// afterPage的返回值是有两种情况,但是都可以被转成List
return dialect.afterPage(resultList, parameter, rowBounds);
// dialect.afterPage()方法
public Object afterPage(List pageList, Object parameterObject, RowBounds rowBounds) {
//这个方法即使不分页也会被执行,所以要判断 null
AbstractHelperDialect delegate = autoDialect.getDelegate();
if(delegate != null){
return delegate.afterPage(pageList, parameterObject, rowBounds);
}
return pageList;
}
// delegate.afterPage()方法
public Object afterPage(List pageList, Object parameterObject, RowBounds rowBounds) {
Page page = getLocalPage();
if (page == null) {
return pageList;
}
page.addAll(pageList);
if (!page.isCount()) {
page.setTotal(-1);
} else if ((page.getPageSizeZero() != null && page.getPageSizeZero()) && page.getPageSize() == 0) {
page.setTotal(pageList.size());
} else if(page.isOrderByOnly()){
page.setTotal(pageList.size());
}
return page;
}其实这里有一个问题是,如果delegate不为空,那么返回的是
Page,但是我们在调用xxxxxMapper的查询方法之后,返回值基本上是List,与我们的常识并不符合。那Page是什么呢?它不只是包含分页信息的基本类,它继承自ArrayList。1
2
3public class Page<E> extends ArrayList<E> implements Closeable {
// ...
}在return后,还会执行finally中的处理代码,即
com.haylion.realTimeBus.interceptor.sql.MyPageHelper的afterAll()方法。其中实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// com.haylion.realTimeBus.interceptor.sql.MyPageHelper.afterAll()
// 这个方法是我们自定义的方法,用来处理执行完前面所述的切点后,保留分页信息,进行再次封装
public void afterAll() {
Page<Object> localPage = getLocalPage();
// 删除分页信息
super.afterAll();
// 设置回本线程中
setLocalPage(localPage);
}
// super.afterAll()。这个方法可以简单理解成,清楚掉本线程中的分页信息
public void afterAll() {
//这个方法即使不分页也会被执行,所以要判断 null
AbstractHelperDialect delegate = autoDialect.getDelegate();
if (delegate != null) {
delegate.afterAll();
autoDialect.clearDelegate();
}
clearPage();
}
// 移除本地变量
public static void clearPage() {
LOCAL_PAGE.remove();
}经过上述的过程,
MyPageInterceptor执行完毕,分页信息存储在本线程中,然后回到切面处理。
切面收尾工作(回到SystemAdvice):
1 | private Object after(Object obj) { |
至此,还有最重要的一个步骤,是在切面处理完成后,将分页信息从本线程中删除,没有此操作,后续操作会出现莫名其妙的错误。也就是finally语句中的PageHelper.clearPage();。
1 | try { |
局限
这就限定了在一个被PageAble注解了的方法上,只能执行一条查询。如果对于一个到来的请求,需要进行两次或以上的查询,并且某一条查询需要分页的情况,如果所有的查询都放在被PageAble注解的方法下,执行会出现问题(出现不必要的分页操作)。但是可以通过组装的形式,完成该项需求。
Mybatis中有很多可以学习的地方,#和$是两种常见的值替换方式,今天站在源码的角度去分析其解析过程。
关键源码
因为这段代码功能单一,对后续的流程影响不大,搞清楚这段代码的作用,基本上#{}和${}的区别,在源代码上已经是清楚了。了解了这段代码之后,再进行后续的解析流程,就不会陷入这段代码的逻辑中,将整个视野投入到流程当中。
位置:GenericTokenParser.java –> parse()
1 | private final String openToken; |
首先它有3个成员变量,可以理解成:当匹配到已openToken开头,closeToken结尾的字符串后,对其中的字符串执行handler.handleToken()方法。
这个handler就是一个典型的策略模式。它是一个只含有``函数的接口:
1 | public interface TokenHandler { |
也就是说#{}和${}的处理逻辑都是封装到handleToken中。
寻找是否含有#{}和${}的逻辑如下:
1 | public class GenericTokenParser { |
用到GenericTokenParser的地方如下图所示:
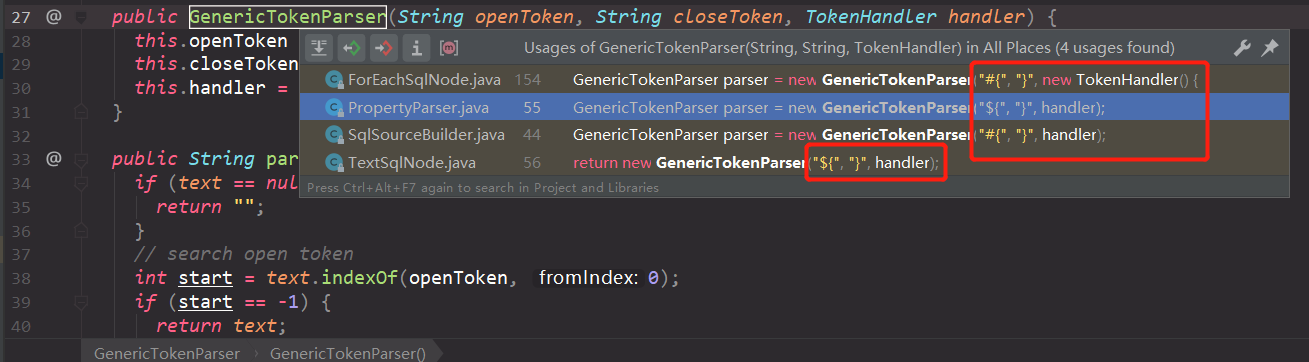
仔细看一看上面的图片,会有一个疑问,那就是为什么#{}和${}分别有2种不同的解析方法?这个可以在后面的分析中得出答案。这里直接给出我们平常所认为的那种处理方式的源代码,即#变成?,然后$直接变成相应的值,如下:
#{}的处理方式位置:
SqlSourceBuidler.java–>ParameterMappingTokenHandler1
2
3
4
5
public String handleToken(String content) {
parameterMappings.add(buildParameterMapping(content));
return "?";
}${}的处理方式位置:
PropertyParser.java–>VariableTokenHandler1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public String handleToken(String content) {
if (variables != null) {
String key = content;
if (enableDefaultValue) {
final int separatorIndex = content.indexOf(defaultValueSeparator);
String defaultValue = null;
if (separatorIndex >= 0) {
key = content.substring(0, separatorIndex);
defaultValue = content.substring(separatorIndex + defaultValueSeparator.length());
}
if (defaultValue != null) {
return variables.getProperty(key, defaultValue);
}
}
if (variables.containsKey(key)) {
return variables.getProperty(key);
}
}
return "${" + content + "}";
}
从上面的代码来看,基本上的问题已经解决了。下面是MyBatis对XML中SQL语句的解析流程的分析。
示例代码
1 | public static void main(String[] args) throws IOException { |
构建SqlSessionFactory阶段
SqlSessionFactoryBuilder.java –> build(InputStream, String, Properties)
1 | public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) { |
XMLConfigBuilder.java –> parse()
1 | public Configuration parse() { |
XMLConfigBuilder.java –> parseConfiguration()
1 | private void parseConfiguration(XNode root) { |
XMLConfigBuilder.java –> mapperElement()
1 | private void mapperElement(XNode parent) throws Exception { |
XMLMapperBuilder.java –> parse()
1 | public void parse() { |
XMLMapperBuilder.java –> configurationElement()
1 | private void configurationElement(XNode context) { |
处理sql的入口
1 | private void buildStatementFromContext(List<XNode> list) { |
XMLStatementBuilder.java –> parseStatementNode()
1 | public void parseStatementNode() { |
其中createSqlSource()的对象langDriver来自XMLLanguageDriver
XMLLanguageDriver.java –> createSqlSource()
1 |
|
关键步骤:XMLScriptBuilder.java –> parseScriptNode()
这里面的每一行代码都可以仔细去看、并理解它的意思
1 | public SqlSource parseScriptNode() { |
通过上面的分析可知,会有两种情况,即是否为动态。一条语句开始的时候都被包装成MixedSqlNode,然后再通过判断是否为动态,将其封装成DynamicSqlSource和RawSqlSource。这两种的含义是:DynamicSqlSource有${}不做任何处理,RawSqlSource没有${},把#{}都替换成?。是如何分配的呢?是通过GenericTokenParser来寻找$符号,然后在handler中,将isDynamic标记为true,代码如下:
1 | protected MixedSqlNode parseDynamicTags(XNode node) { |
isDynamic()中封装了对GenericTokenParser的调用
1 | public boolean isDynamic() { |
在处理RawSqlSource时的初始化过程如下:
1 | public RawSqlSource(Configuration configuration, SqlNode rootSqlNode, Class<?> parameterType) { |
其中ParameterMappingTokenHandler的handleToken()方法,也就是匹配成功后的回调,实现如下:
1 |
|
在处理RawSqlSource时,没有这方面的处理,因此在这里就不贴其代码流程。反思:因为这是初始化阶段,可以理解成开机启动脚本,所以#{}的值是确定的,也就是说要变成?,而${}的值在这个阶段就是未知的,因为还没有具体的SQL语句要生成,直接替换的数据还不确定,所以含有${}的语句,在初始化阶段是先不处理。
参考:
- https://blog.csdn.net/xu1916659422/article/details/77918175 在此基础上进行了校正,并加入了自己的理解
- http://www.mybatis.org/mybatis-3/zh/getting-started.html 进行基本的配置
Flask如何使用logging.FileHandler将日志保存到文件
需求
将日志尽可能往文件中输,自带的默认只输出到屏幕上。
代码
获取文件名
1 | def get_custom_file_name(): |
配置logging
1 | dictConfig({ |
代码分析
在官方文档中,有一个默认的handler,当我添加一个自定义的handler,名叫custom的时候,读取配置失败,程序中断,也就无法继续执行下去,提示说,少一个叫做filename的参数。
loggin.FileHandler的构造函数中,有一个必填的参数,叫做filename。如下:
1 | class FileHandler(StreamHandler): |
如何才能传入参数filename?
①进入dictConfig()
1 | def dictConfig(config): |
②进入configure(),找到对handler的处理逻辑,如下:
1 | # 前面的代码省略 |
③进入具体处理handler的逻辑,self.configure_handler():
1 | def configure_handler(self, config): |
其中的调试数据截图如下: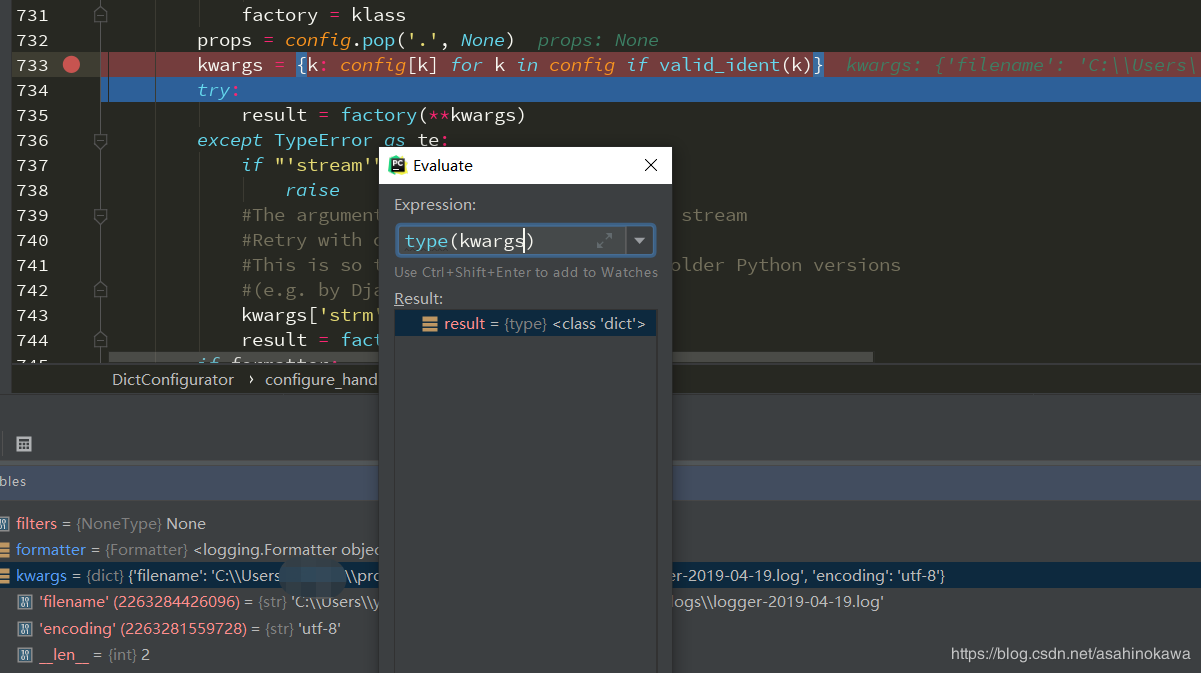
如果没有配置filename的信息,那么实例化类的时候就报错也是理所应当,因此还可以尝试性地配置encoding参数到其中,工作正常。
总结
虽然对这一块的整体了解还不够,但是对于能够参照官方文档,参考源代码实现,完成自己的想法,做到的那一刻还是有点成就感。




