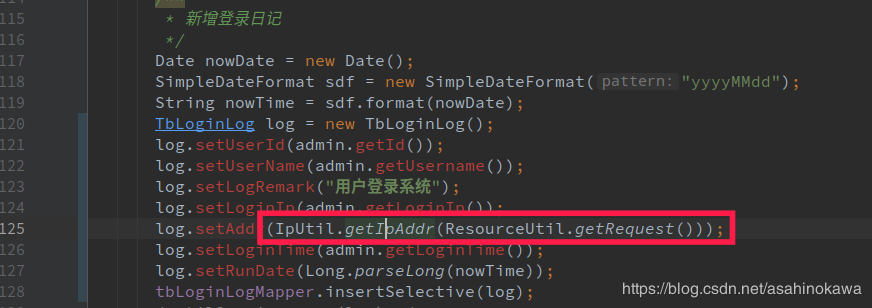
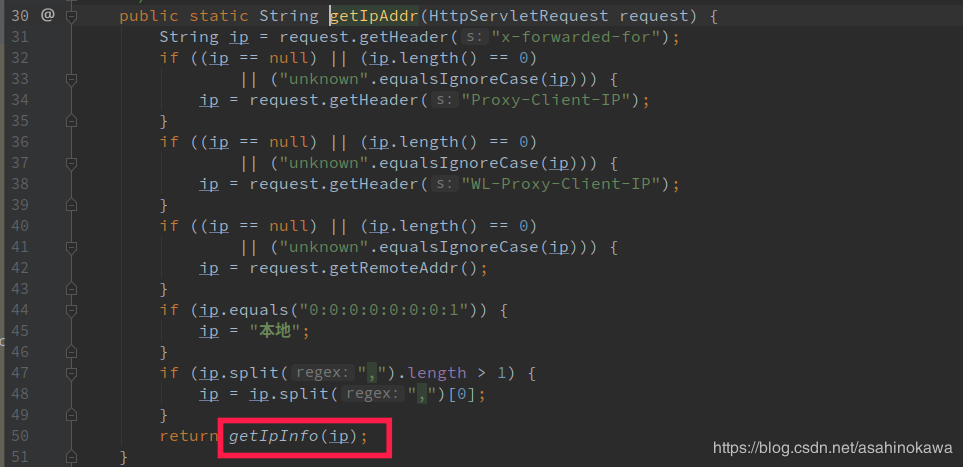
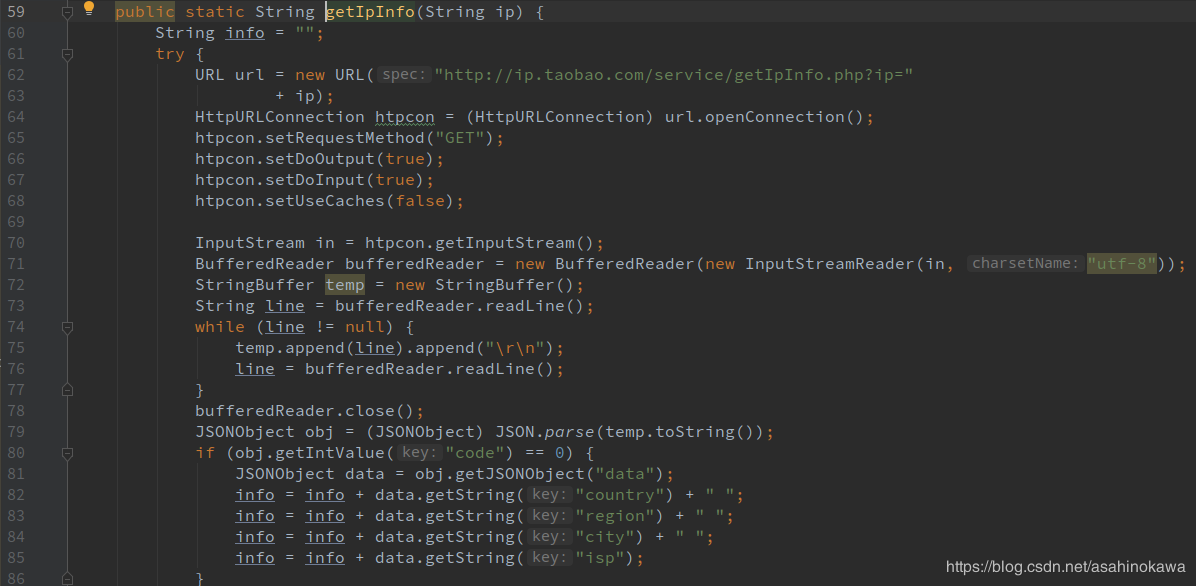
PageHelper链接:https://github.com/pagehelper/Mybatis-PageHelper PageAble,这是一个对PageHelper的封装注解。这个注解有一个非常显著的问题就是,不能在这个方法里面执行两次SQL查询 (原因将在后续中慢慢分析)。使用方法如下:
1 2 3 4 @PageAble public Object method (int page, int size) { 。。。 }
注解的内容比较简单,就是定义了两个参数,分别为这两个参数设置了默认的名字、以及默认值。
1 2 3 4 5 6 7 8 @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface PageAble { String pageSizeName () default "size" ; String pageNumName () default "page" ; int pageSize () default 20 ; int pageNum () default 1 ; }
然后得到的返回值是一个叫做ResultPageView的类,是对分页情况的一个封装,其中的内容如下:
1 2 3 4 5 6 7 public class ResultPageView <T> { private Long total = 0l ; private Integer current = 1 ; private Integer pageCount = 0 ; private List<T> list; }
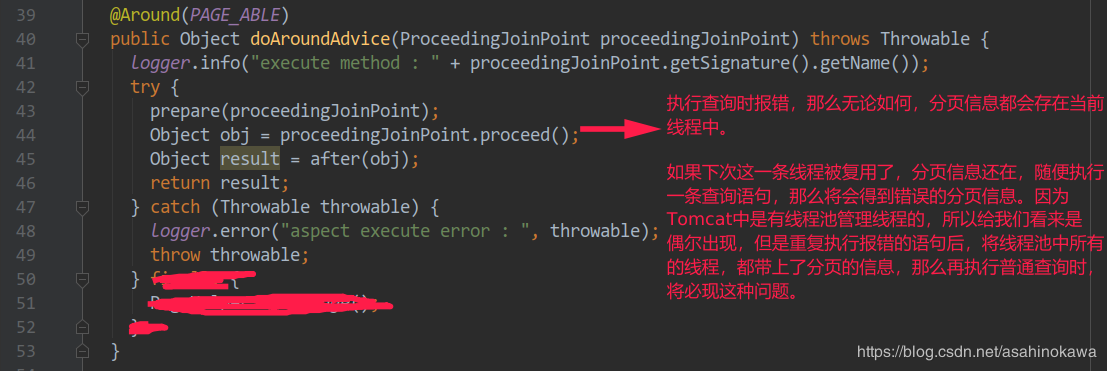
所以,最重要的问题当然是被@PageAble注解的方法是怎样执行的 。显然这里是利用了Spring AOP,在这个方法的前后,加上了自定义的处理方法,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private static final String PAGE_ABLE = "@annotation(com.xxxxxo0o0.baseservice.annotation.PageAble)" ;@Around(PAGE_ABLE) public Object doAroundAdvice (ProceedingJoinPoint proceedingJoinPoint) throws Throwable { logger.info("execute method : " + proceedingJoinPoint.getSignature().getName()); try { prepare(proceedingJoinPoint); Object obj = proceedingJoinPoint.proceed(); Object result = after(obj); return result; } catch (Throwable throwable) { logger.error("aspect execute error : " , throwable); throw throwable; } finally { } }
在被注解方法执行前的准备活动中,执行了什么操作?代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private void prepare (ProceedingJoinPoint point) throws Exception { Signature signature = point.getSignature(); MethodSignature methodSignature = (MethodSignature) signature; Method targetMethod = methodSignature.getMethod(); PageAble pageAble = targetMethod.getAnnotation(PageAble.class); String numName = pageAble.pageNumName(); String sizeName = pageAble.pageSizeName(); int pageNo = pageAble.pageNum(); int pageSize = pageAble.pageSize(); Object[] paramValues = point.getArgs(); String[] paramNames = methodSignature.getParameterNames(); int length = paramNames.length; for (int i = 0 ; i < length; i++) { if (paramNames[i].equals(numName)) { pageNo = (Integer) paramValues[i]; } else if (paramNames[i].equals(sizeName)) { pageSize = (Integer) paramValues[i]; } } PageHelper.startPage(pageNo, pageSize); }
先忽略其中的细节,看看被注解方法后面执行的方法做了什么事情,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private Object after (Object obj) { assert obj instanceof List; PageInfo<?> pageInfo = new PageInfo ((List<?>) obj); Page<Object> localPage = PageHelper.getLocalPage(); long total = localPage.getTotal(); int pageNum = localPage.getPageNum(); int pages = localPage.getPages(); List<?> list = (List<?>) obj; try { List<Map> mapList = new ArrayList <>(); for (Object o : list) { HashMap<String, Object> map = MapUtil.convertObj2Map(o); if (o instanceof BaseModel) { BaseModel baseModel = (BaseModel) o; map.put("id" , baseModel.getId()); } ReflectionUtils .doWithFields(o.getClass(), new InnerFieldCallback (map, o), new InnerFieldFilter ()); mapList.add(map); } list = mapList; } catch (Exception e) { logger.error("convert obj to map occurred error " , e); } pageInfo = new PageInfo ((list)); ResultPageView<?> resultPageView; resultPageView = new ResultPageView <>(total, pageNum, pages, pageInfo.getList()); PageHelper.clearPage(); return resultPageView; }
PageHelper.start()做了什么 一路往父类翻到start()的实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public static <E> Page<E> startPage (int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) { Page<E> page = new Page <E>(pageNum, pageSize, count); page.setReasonable(reasonable); page.setPageSizeZero(pageSizeZero); Page<E> oldPage = getLocalPage(); if (oldPage != null && oldPage.isOrderByOnly()) { page.setOrderBy(oldPage.getOrderBy()); } setLocalPage(page); return page; }
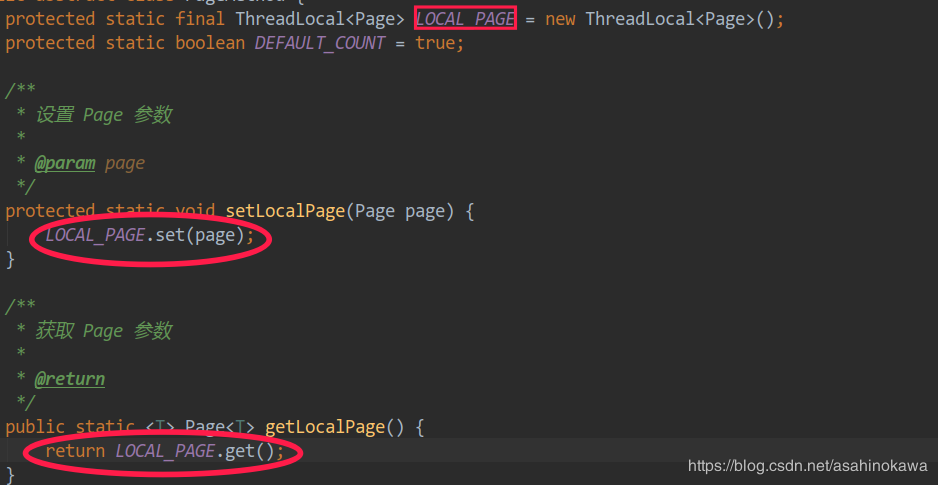
setLocalPage()与之前的after()中的getLocalPage()是一对get/set方法,他们的目的是从当前线程中获取/设置分页信息。其实现如下(关于ThreadLocal的具体实现,可以去参考其他博客):startPage()只是在线程中塞了一个关于分页的信息,那么真正读取这个分页信息的动作一定是在处理SQL语句的地方,也就是Interceptor。PageHelper的官方使用文档链接:https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/zh/HowToUse.md
PageHelper 方法使用了静态的 ThreadLocal 参数,分页参数和线程是绑定的。只要你可以保证在 PageHelper 方法调用后紧跟 MyBatis 查询方法,这就是安全的。因为 PageHelper 在 finally 代码段中自动清除了 ThreadLocal 存储的对象。如果代码在进入 Executor 前发生异常,就会导致线程不可用,这属于人为的 Bug(例如接口方法和 XML 中的不匹配,导致找不到 MappedStatement 时),这种情况由于线程不可用,也不会导致 ThreadLocal 参数被错误的使用。但是如果你写出下面这样的代码,就是不安全的用法:
1 2 3 4 5 6 7 PageHelper.startPage(1 , 10 ); List<Country> list; if (param1 != null ){ list = countryMapper.selectIf(param1); } else { list = new ArrayList <Country>(); }
这种情况下由于 param1 存在 null 的情况,就会导致 PageHelper 生产了一个分页参数,但是没有被消费,这个参数就会一直保留在这个线程上。当这个线程再次被使用时,就可能导致不该分页的方法去消费这个分页参数,这就产生了莫名其妙的分页。
因此打开项目中的MyPageInterceptor,它的功能就是充当Mybatis的拦截器,还有一部分自定义的功能,比如说输出sql执行时间、打印sql语句。这个类与PageHelper的拦截器关键的代码基本一致,可以说是copy吧,其中关键的一个地方是intercept()方法中,有一个进行判断,是否需要分页的语句。
1 2 3 4 5 6 7 8 9 10 11 12 13 public class MyPageHelper extends PageHelper { @Override public void afterAll () { Page<Object> localPage = getLocalPage(); super .afterAll(); setLocalPage(localPage); } }
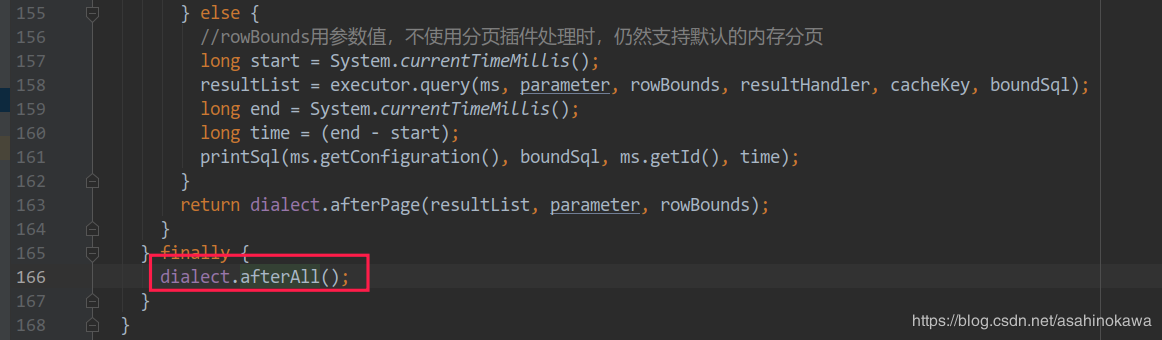
这里的代码执行完成后,不论查询的结果是成功还是失败,分页信息都会存在当前线程中(如果直接调用父类的方法,不自定义这个方法,就能保证执行完一次查询,分页信息不会保存在当前线程中)。问题就出在这里。因为interceptor处理过后,当前线程中还存在分页的信息,并且这个分页的信息需要以来切面的处理方法来完成。
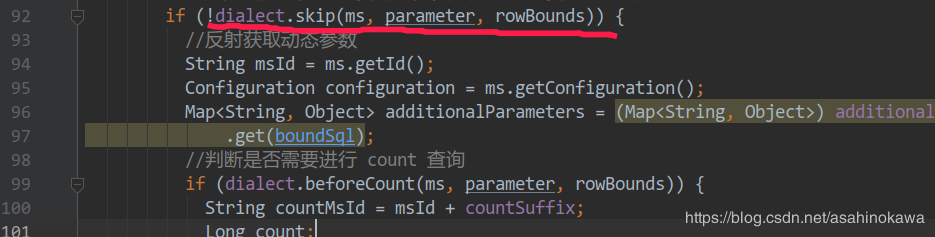
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Override public boolean skip (MappedStatement ms, Object parameterObject, RowBounds rowBounds) { if (ms.getId().endsWith(MSUtils.COUNT)){ throw new RuntimeException ("在系统中发现了多个分页插件,请检查系统配置!" ); } Page page = pageParams.getPage(parameterObject, rowBounds); if (page == null ) { return true ; } else { if (StringUtil.isEmpty(page.getCountColumn())){ page.setCountColumn(pageParams.getCountColumn()); } autoDialect.initDelegateDialect(ms); return false ; } }
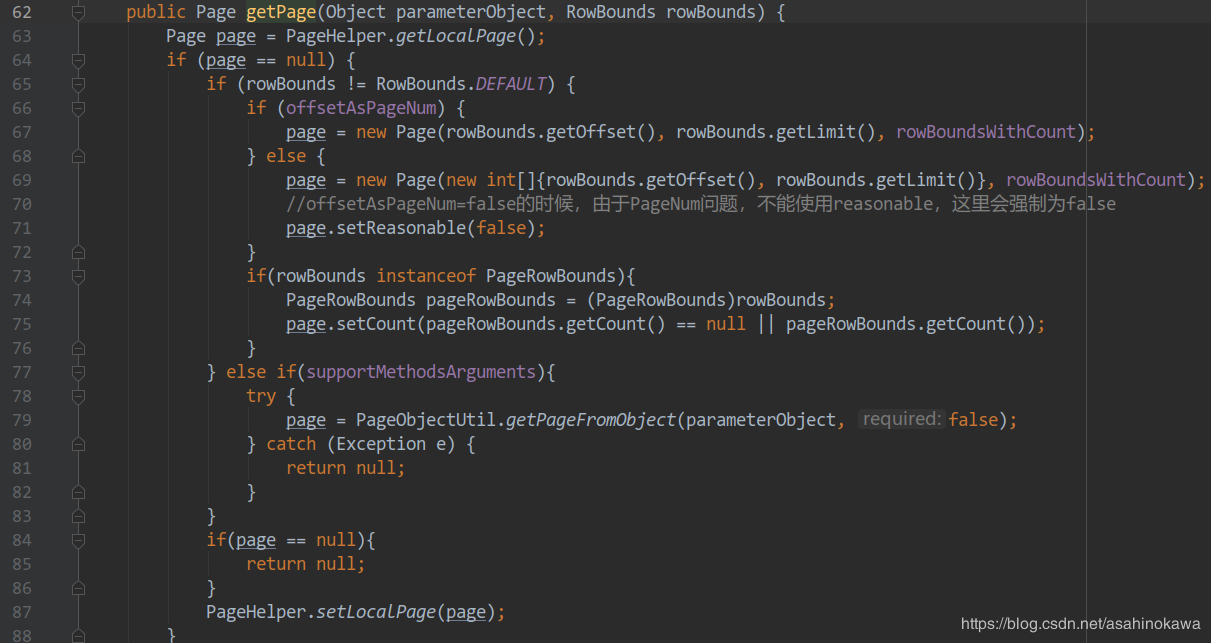
其中获取Page的代码是这样的,说到底还是从当前线程中去取:
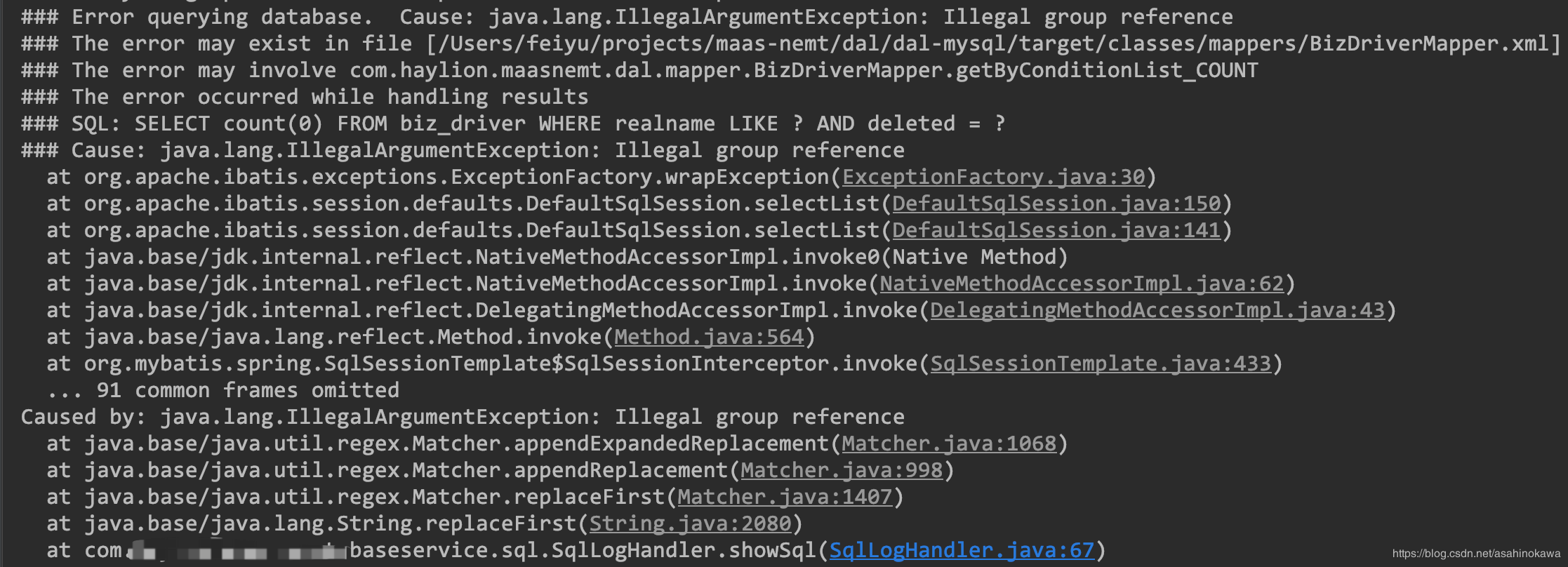
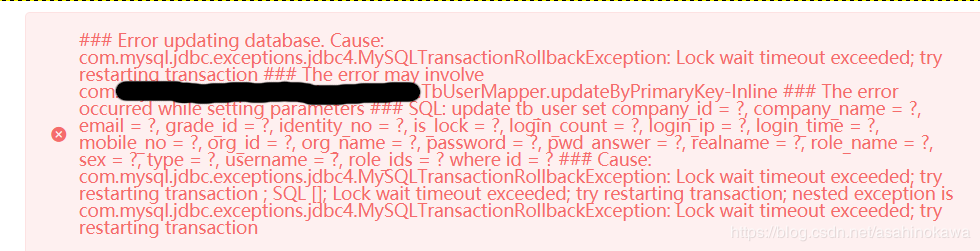
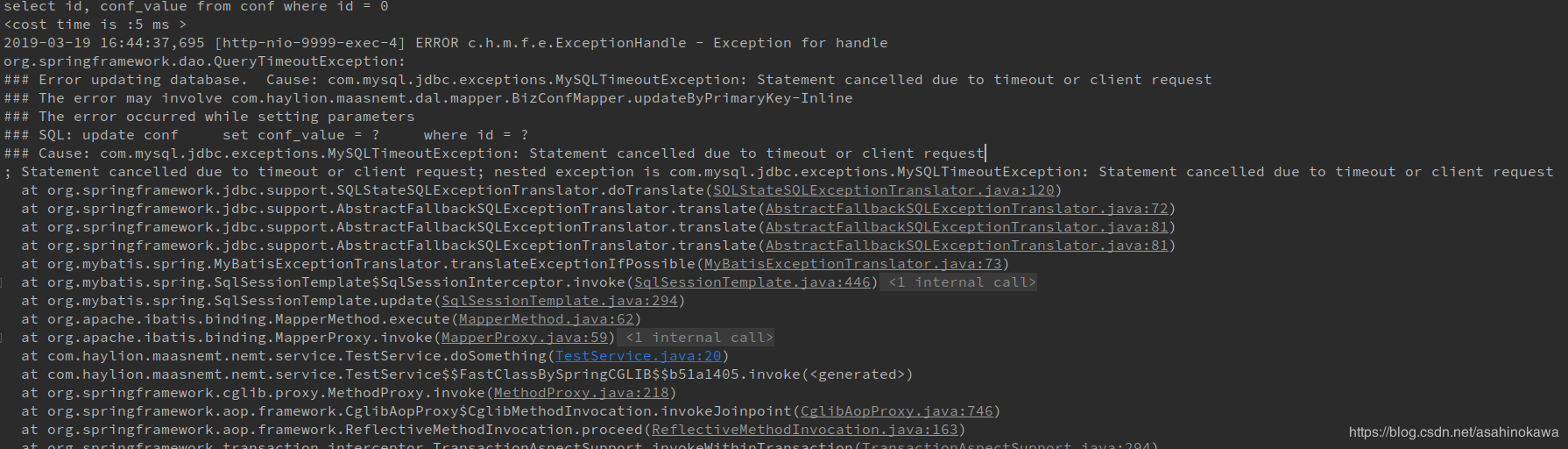
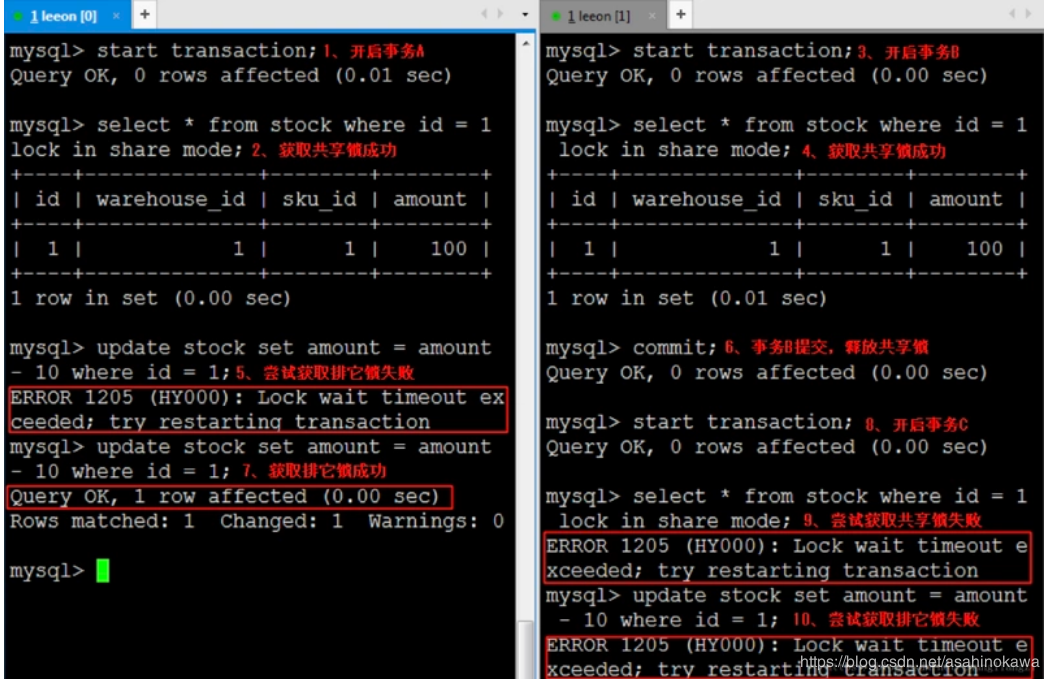
bug描述与分析 执行一个分页查询,让查询故意报错,多执行几次,然后再进行一次普通查询,得到ClassCastException异常。
解决 因此加上finally后,无论是否报错,那么分页信息都将会被在线程中清除。问题就解决了,所以把涂掉的finally加上清除分页信息的处理,即可解决此问题。
后记 批量发送请求的脚本,用来引发bug用:main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import requestsimport jsonhost1 = 'localhost:9999' host2 = 'xxxxxxxx' host = host1 MAX = 100 def vehicle (): parse_response(send_get_req('http://' +host+'/nemt/driver/get' )) parse_response(send_get_req('http://' +host+'/nemt/vehicles?page=1&size=20' )) parse_response(send_get_req('http://' +host+'/nemt/vehicleType/all' )) pass def app_version (): parse_response(send_get_req('http://' +host+'/nemt/driver-apps' )) def parse_response (resp ): s = json.loads(resp[0 ].content) if s['code' ] == 500 : print ("x " + s['message' ] + ' --> ' + resp[1 ]) else : print ("o" ) pass def send_get_req (url ): return requests.get(url), url def main (): i = 0 while i <= MAX: app_version() vehicle() i = i + 1 if __name__ == '__main__' : main()
crack.sh
1 2 3 4 5 6 7 8 9 10 11 # !/usr/bin/env bash # if [$1 -eq "" ]; then # max=1 # else # max=$1 # fi for i in $(seq 1 $1): do curl 'http://localhost:9999/nemt/orders?page=1&size=20' -H 'Accept-Encoding: gzip, deflate' -H 'Accept-Language: zh,en;q=0.9,ja;q=0.8,zh-TW;q=0.7,fr;q=0.6,zh-CN;q=0.5' -H 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' -H 'Accept: application/json, text/plain, */*' -H 'userId: 453' -H 'Connection: keep-alive' -H 'token: 48143d9154e7c42face53855826f5ffa' --compressed echo '' done