Mybatis中有很多可以学习的地方,#和$是两种常见的值替换方式,今天站在源码的角度去分析其解析过程。
关键源码 因为这段代码功能单一,对后续的流程影响不大,搞清楚这段代码的作用,基本上#{}和${}的区别,在源代码上已经是清楚了。了解了这段代码之后,再进行后续的解析流程,就不会陷入这段代码的逻辑中,将整个视野投入到流程当中。
位置:GenericTokenParser.java –> parse()
1 2 3 4 5 6 7 8 9 10 private final String openToken;private final String closeToken;private final TokenHandler handler;public GenericTokenParser (String openToken, String closeToken, TokenHandler handler) { this .openToken = openToken; this .closeToken = closeToken; this .handler = handler; }
首先它有3个成员变量,可以理解成:当匹配到已openToken开头,closeToken结尾的字符串后,对其中的字符串执行handler.handleToken()方法。
这个handler就是一个典型的策略模式。它是一个只含有``函数的接口:
1 2 3 public interface TokenHandler { String handleToken (String content) ; }
也就是说#{}和${}的处理逻辑都是封装到handleToken中。
寻找是否含有#{}和${}的逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 public class GenericTokenParser { public String parse (String text) { if (text == null || text.isEmpty()) { return "" ; } int start = text.indexOf(openToken, 0 ); if (start == -1 ) { return text; } char [] src = text.toCharArray(); int offset = 0 ; final StringBuilder builder = new StringBuilder (); StringBuilder expression = null ; while (start > -1 ) { if (start > 0 && src[start - 1 ] == '\\' ) { builder.append(src, offset, start - offset - 1 ).append(openToken); offset = start + openToken.length(); } else { if (expression == null ) { expression = new StringBuilder (); } else { expression.setLength(0 ); } builder.append(src, offset, start - offset); offset = start + openToken.length(); int end = text.indexOf(closeToken, offset); while (end > -1 ) { if (end > offset && src[end - 1 ] == '\\' ) { expression.append(src, offset, end - offset - 1 ).append(closeToken); offset = end + closeToken.length(); end = text.indexOf(closeToken, offset); } else { expression.append(src, offset, end - offset); offset = end + closeToken.length(); break ; } } if (end == -1 ) { builder.append(src, start, src.length - start); offset = src.length; } else { builder.append(handler.handleToken(expression.toString())); offset = end + closeToken.length(); } } start = text.indexOf(openToken, offset); } if (offset < src.length) { builder.append(src, offset, src.length - offset); } return builder.toString(); } }
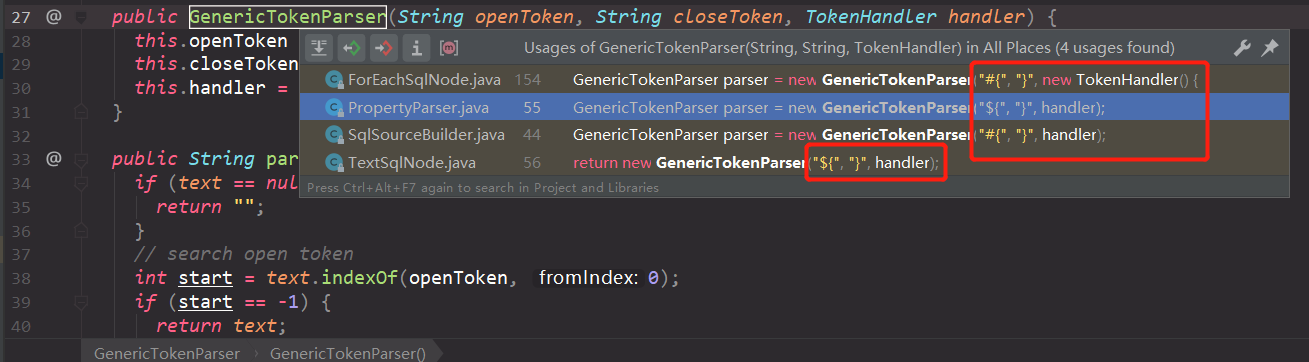
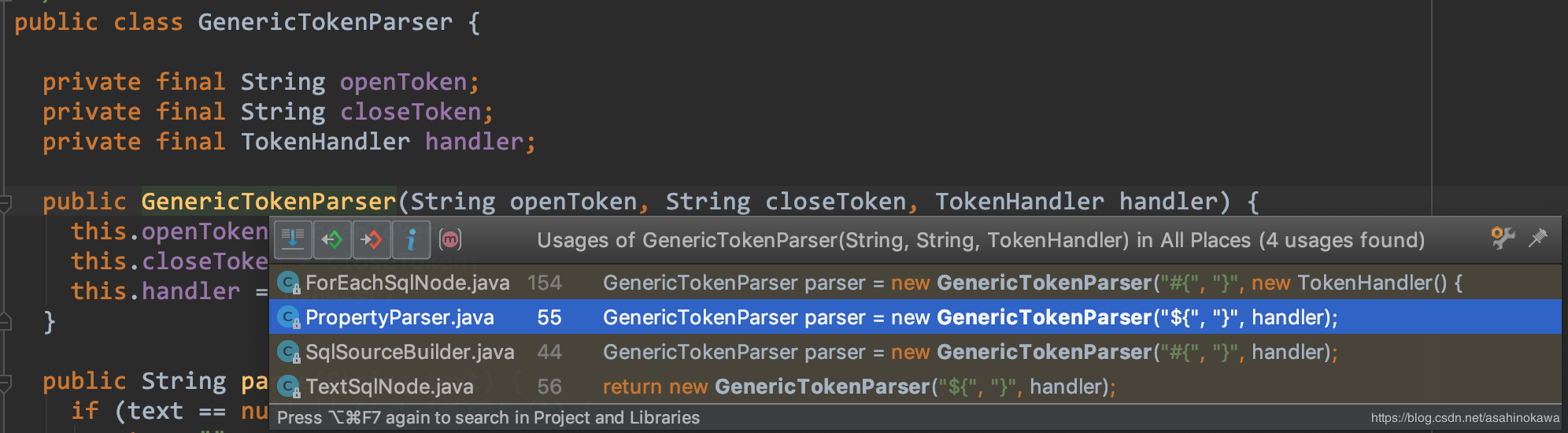
用到GenericTokenParser的地方如下图所示:
仔细看一看上面的图片,会有一个疑问,那就是为什么#{}和${}分别有2种不同的解析方法 ?这个可以在后面的分析中得出答案。这里直接给出我们平常所认为的那种处理方式的源代码,即#变成?,然后$直接变成相应的值,如下:
从上面的代码来看,基本上的问题已经解决了。下面是MyBatis对XML中SQL语句的解析流程的分析。
示例代码 1 2 3 4 5 6 7 8 public static void main (String[] args) throws IOException { SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder ().build(Resources.getResourceAsStream("mybatis-config.xml" )); SqlSession session = sqlSessionFactory.openSession(); BizDriverMapper mapper = session.getMapper(BizDriverMapper.class); List<BizDriver> list = mapper.getByNameOrNumber("hello" ); System.out.println(list.size()); }
构建SqlSessionFactory阶段 SqlSessionFactoryBuilder.java –> build(InputStream, String, Properties)
1 2 3 4 5 6 7 public SqlSessionFactory build (InputStream inputStream, String environment, Properties properties) { try { XMLConfigBuilder parser = new XMLConfigBuilder (inputStream, environment, properties); return build(parser.parse()); } ... }
XMLConfigBuilder.java –> parse()
1 2 3 4 5 6 7 8 public Configuration parse () { if (parsed) { throw new BuilderException ("Each XMLConfigBuilder can only be used once." ); } parsed = true ; parseConfiguration(parser.evalNode("/configuration" )); return configuration; }
XMLConfigBuilder.java –> parseConfiguration()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 private void parseConfiguration (XNode root) { try { propertiesElement(root.evalNode("properties" )); Properties settings = settingsAsProperties(root.evalNode("settings" )); loadCustomVfs(settings); typeAliasesElement(root.evalNode("typeAliases" )); pluginElement(root.evalNode("plugins" )); objectFactoryElement(root.evalNode("objectFactory" )); objectWrapperFactoryElement(root.evalNode("objectWrapperFactory" )); reflectorFactoryElement(root.evalNode("reflectorFactory" )); settingsElement(settings); environmentsElement(root.evalNode("environments" )); databaseIdProviderElement(root.evalNode("databaseIdProvider" )); typeHandlerElement(root.evalNode("typeHandlers" )); mapperElement(root.evalNode("mappers" )); } catch (Exception e) { throw new BuilderException ("Error parsing SQL Mapper Configuration. Cause: " + e, e); } }
XMLConfigBuilder.java –> mapperElement()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private void mapperElement (XNode parent) throws Exception { if (parent != null ) { for (XNode child : parent.getChildren()) { if ("package" .equals(child.getName())) { String mapperPackage = child.getStringAttribute("name" ); configuration.addMappers(mapperPackage); } else { String resource = child.getStringAttribute("resource" ); String url = child.getStringAttribute("url" ); String mapperClass = child.getStringAttribute("class" ); if (resource != null && url == null && mapperClass == null ) { ErrorContext.instance().resource(resource); InputStream inputStream = Resources.getResourceAsStream(resource); XMLMapperBuilder mapperParser = new XMLMapperBuilder (inputStream, configuration, resource, configuration.getSqlFragments()); mapperParser.parse(); } else if (resource == null && url != null && mapperClass == null ) { ErrorContext.instance().resource(url); InputStream inputStream = Resources.getUrlAsStream(url); XMLMapperBuilder mapperParser = new XMLMapperBuilder (inputStream, configuration, url, configuration.getSqlFragments()); mapperParser.parse(); } else if (resource == null && url == null && mapperClass != null ) { Class<?> mapperInterface = Resources.classForName(mapperClass); configuration.addMapper(mapperInterface); } else { throw new BuilderException ("A mapper element may only specify a url, resource or class, but not more than one." ); } } } } }
XMLMapperBuilder.java –> parse()
1 2 3 4 5 6 7 8 9 10 11 public void parse () { if (!configuration.isResourceLoaded(resource)) { configurationElement(parser.evalNode("/mapper" )); configuration.addLoadedResource(resource); bindMapperForNamespace(); } parsePendingResultMaps(); parsePendingCacheRefs(); parsePendingStatements(); }
XMLMapperBuilder.java –> configurationElement()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private void configurationElement (XNode context) { try { String namespace = context.getStringAttribute("namespace" ); if (namespace == null || namespace.equals("" )) { throw new BuilderException ("Mapper's namespace cannot be empty" ); } builderAssistant.setCurrentNamespace(namespace); cacheRefElement(context.evalNode("cache-ref" )); cacheElement(context.evalNode("cache" )); parameterMapElement(context.evalNodes("/mapper/parameterMap" )); resultMapElements(context.evalNodes("/mapper/resultMap" )); sqlElement(context.evalNodes("/mapper/sql" )); buildStatementFromContext(context.evalNodes("select|insert|update|delete" )); } catch (Exception e) { throw new BuilderException ("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e); } }
处理sql的入口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private void buildStatementFromContext (List<XNode> list) { if (configuration.getDatabaseId() != null ) { buildStatementFromContext(list, configuration.getDatabaseId()); } buildStatementFromContext(list, null ); } private void buildStatementFromContext (List<XNode> list, String requiredDatabaseId) { for (XNode context : list) { final XMLStatementBuilder statementParser = new XMLStatementBuilder (configuration, builderAssistant, context, requiredDatabaseId); try { statementParser.parseStatementNode(); } catch (IncompleteElementException e) { configuration.addIncompleteStatement(statementParser); } } }
XMLStatementBuilder.java –> parseStatementNode()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 public void parseStatementNode () { String id = context.getStringAttribute("id" ); String databaseId = context.getStringAttribute("databaseId" ); if (!databaseIdMatchesCurrent(id, databaseId, this .requiredDatabaseId)) { return ; } Integer fetchSize = context.getIntAttribute("fetchSize" ); Integer timeout = context.getIntAttribute("timeout" ); String parameterMap = context.getStringAttribute("parameterMap" ); String parameterType = context.getStringAttribute("parameterType" ); Class<?> parameterTypeClass = resolveClass(parameterType); String resultMap = context.getStringAttribute("resultMap" ); String resultType = context.getStringAttribute("resultType" ); String lang = context.getStringAttribute("lang" ); LanguageDriver langDriver = getLanguageDriver(lang); Class<?> resultTypeClass = resolveClass(resultType); String resultSetType = context.getStringAttribute("resultSetType" ); StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType" , StatementType.PREPARED.toString())); ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType); String nodeName = context.getNode().getNodeName(); SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH)); boolean isSelect = sqlCommandType == SqlCommandType.SELECT; boolean flushCache = context.getBooleanAttribute("flushCache" , !isSelect); boolean useCache = context.getBooleanAttribute("useCache" , isSelect); boolean resultOrdered = context.getBooleanAttribute("resultOrdered" , false ); XMLIncludeTransformer includeParser = new XMLIncludeTransformer (configuration, builderAssistant); includeParser.applyIncludes(context.getNode()); processSelectKeyNodes(id, parameterTypeClass, langDriver); SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass); String resultSets = context.getStringAttribute("resultSets" ); String keyProperty = context.getStringAttribute("keyProperty" ); String keyColumn = context.getStringAttribute("keyColumn" ); KeyGenerator keyGenerator; String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX; keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true ); if (configuration.hasKeyGenerator(keyStatementId)) { keyGenerator = configuration.getKeyGenerator(keyStatementId); } else { keyGenerator = context.getBooleanAttribute("useGeneratedKeys" , configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType)) ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE; } builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered, keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets); }
其中createSqlSource()的对象langDriver来自XMLLanguageDriver
XMLLanguageDriver.java –> createSqlSource()
1 2 3 4 5 @Override public SqlSource createSqlSource (Configuration configuration, XNode script, Class<?> parameterType) { XMLScriptBuilder builder = new XMLScriptBuilder (configuration, script, parameterType); return builder.parseScriptNode(); }
关键步骤: XMLScriptBuilder.java –> parseScriptNode()
这里面的每一行代码都可以仔细去看、并理解它的意思
1 2 3 4 5 6 7 8 9 10 11 12 13 public SqlSource parseScriptNode () { MixedSqlNode rootSqlNode = parseDynamicTags(context); SqlSource sqlSource = null ; if (isDynamic) { sqlSource = new DynamicSqlSource (configuration, rootSqlNode); } else { sqlSource = new RawSqlSource (configuration, rootSqlNode, parameterType); } return sqlSource; }
通过上面的分析可知,会有两种情况,即是否为动态。一条语句开始的时候都被包装成MixedSqlNode,然后再通过判断是否为动态,将其封装成DynamicSqlSource和RawSqlSource。这两种的含义是:DynamicSqlSource有${}不做任何处理,RawSqlSource没有${},把#{}都替换成?。是如何分配的呢?是通过GenericTokenParser来寻找$符号,然后在handler中,将isDynamic标记为true,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 protected MixedSqlNode parseDynamicTags (XNode node) { List<SqlNode> contents = new ArrayList <SqlNode>(); NodeList children = node.getNode().getChildNodes(); for (int i = 0 ; i < children.getLength(); i++) { XNode child = node.newXNode(children.item(i)); if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) { String data = child.getStringBody("" ); TextSqlNode textSqlNode = new TextSqlNode (data); if (textSqlNode.isDynamic()) { contents.add(textSqlNode); isDynamic = true ; } else { contents.add(new StaticTextSqlNode (data)); } } else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { String nodeName = child.getNode().getNodeName(); XMLScriptBuilder.NodeHandler handler = nodeHandlerMap.get(nodeName); if (handler == null ) { throw new BuilderException ("Unknown element <" + nodeName + "> in SQL statement." ); } handler.handleNode(child, contents); isDynamic = true ; } } return new MixedSqlNode (contents); }
isDynamic()中封装了对GenericTokenParser的调用
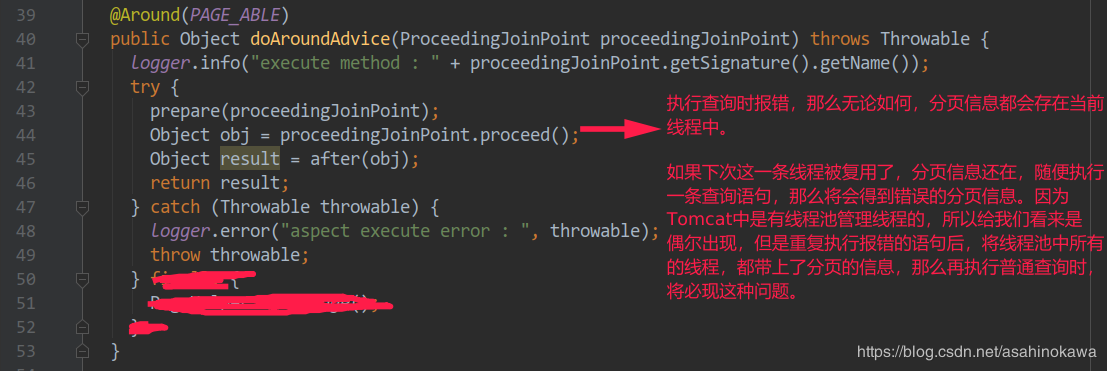
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public boolean isDynamic () { DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser (); GenericTokenParser parser = createParser(checker); parser.parse(text); return checker.isDynamic(); } private static class DynamicCheckerTokenParser implements TokenHandler { private boolean isDynamic; public DynamicCheckerTokenParser () { } public boolean isDynamic () { return isDynamic; } @Override public String handleToken (String content) { this .isDynamic = true ; return null ; } }
在处理RawSqlSource时的初始化过程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public RawSqlSource (Configuration configuration, SqlNode rootSqlNode, Class<?> parameterType) { this (configuration, getSql(configuration, rootSqlNode), parameterType); } public RawSqlSource (Configuration configuration, String sql, Class<?> parameterType) { SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder (configuration); Class<?> clazz = parameterType == null ? Object.class : parameterType; sqlSource = sqlSourceParser.parse(sql, clazz, new HashMap <String, Object>()); } public SqlSource parse (String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) { ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler (configuration, parameterType, additionalParameters); GenericTokenParser parser = new GenericTokenParser ("#{" , "}" , handler); String sql = parser.parse(originalSql); return new StaticSqlSource (configuration, sql, handler.getParameterMappings()); }
其中ParameterMappingTokenHandler的handleToken()方法,也就是匹配成功后的回调,实现如下:
1 2 3 4 5 @Override public String handleToken (String content) { parameterMappings.add(buildParameterMapping(content)); return "?" ; }
在处理RawSqlSource时,没有这方面的处理,因此在这里就不贴其代码流程。反思:因为这是初始化阶段,可以理解成开机启动脚本,所以#{}的值是确定的,也就是说要变成?,而${}的值在这个阶段就是未知的,因为还没有具体的SQL语句要生成,直接替换的数据还不确定,所以含有${}的语句,在初始化阶段是先不处理。
参考: