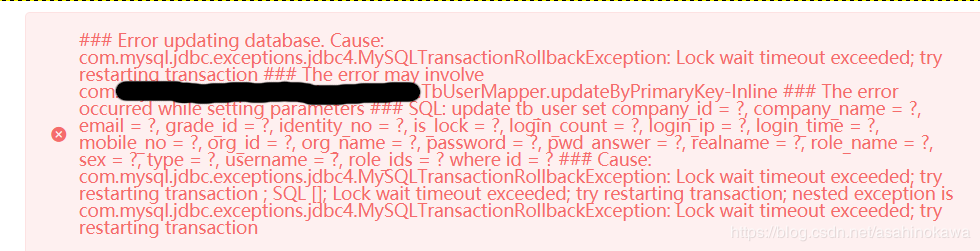
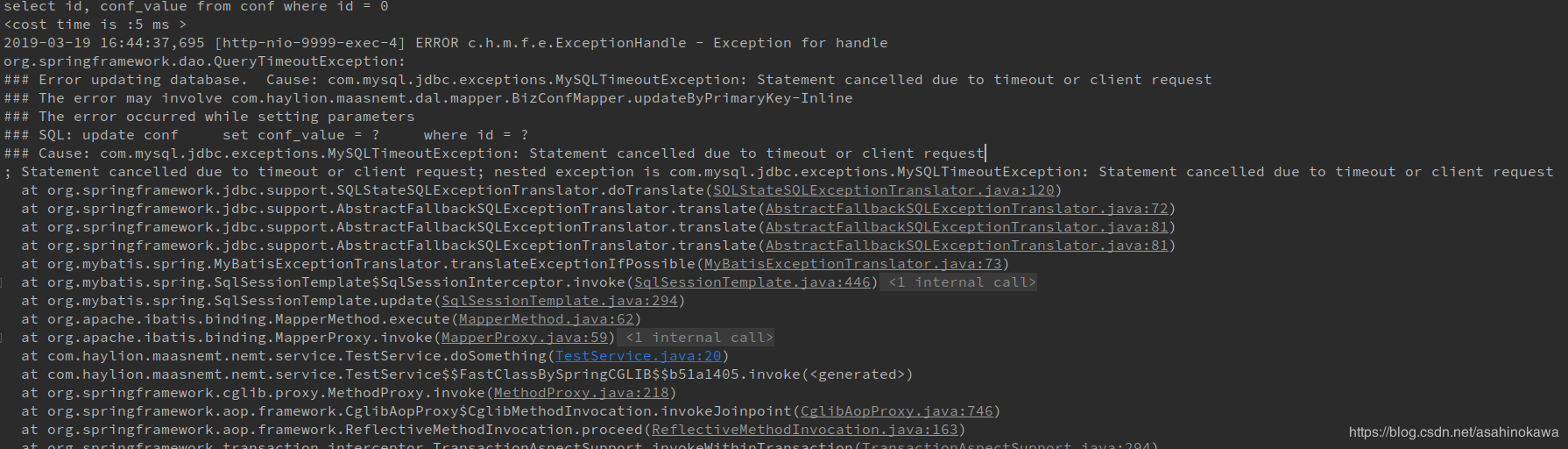
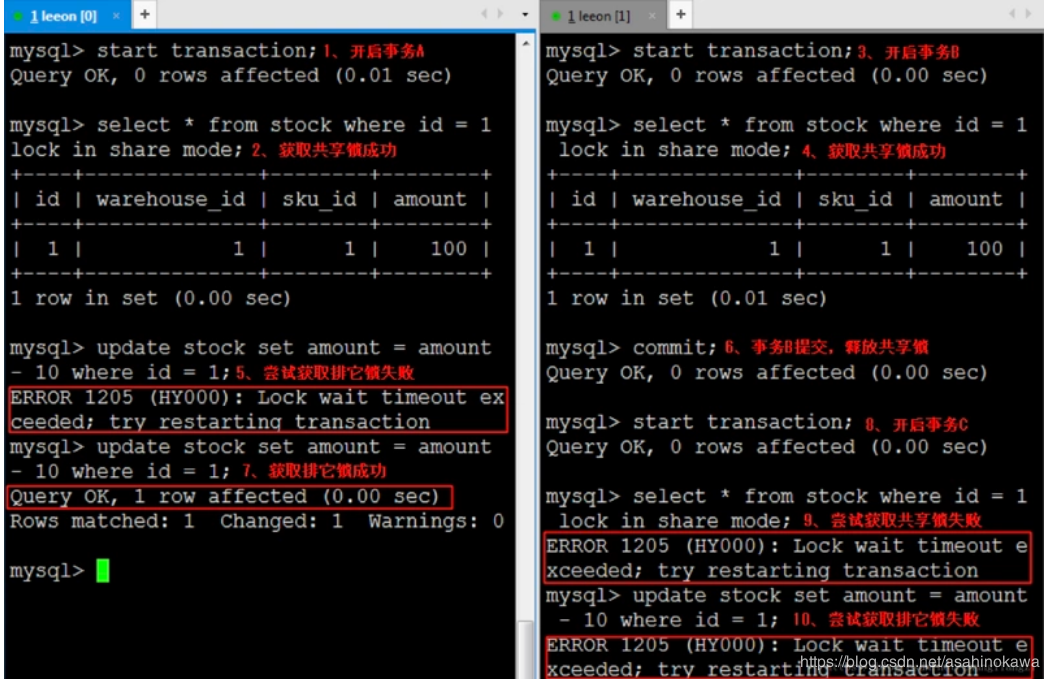
This exception indicates that the transaction associated with processing of the request has been rolled back, or marked to roll back. Thus the requested operation either could not be performed or was not performed because further computation on behalf of the transaction would be fruitless
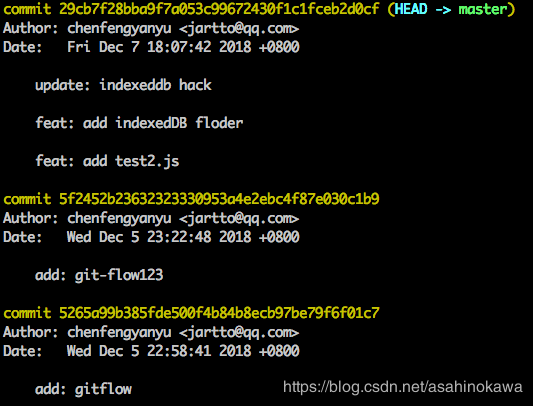
s cacc52da add: qrcode s f072ef48 update: indexeddb hack s 4e84901a feat: add indexedDB floder s 8f33126c feat: add test2.js # Rebase 5f2452b2..8f33126c onto 5f2452b2 (4 commands) # # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # x, exec = run command (the rest of the line) using shell # d, drop = remove commit # # These lines can be re-ordered; they are executed from top to bottom. # # If you remove a line here THAT COMMIT WILL BE LOST. # # However, if you remove everything, the rebase will be aborted. #
有几个命令需要注意一下:
1 2 3 4 5 6 7
p, pick = use commit r, reword = use commit, but edit the commit message e, edit = use commit, but stop for amending s, squash = use commit, but meld into previous commit f, fixup = like “squash”, but discard this commit’s log message x, exec = run command (the rest of the line) using shell d, drop = remove commit
按照如上命令来修改你的提交纪录:
1 2 3 4
s cacc52da add: qrcode s f072ef48 update: indexeddb hack s 4e84901a feat: add indexedDB floder p 8f33126c feat: add test2.js
3.如果保存的时候,你碰到了这个错误: error: cannot 'squash' without a previous commit 注意不要合并先前提交的东西,也就是已经提交远程分支的纪录。
4.如果你异常退出了 vi 窗口,不要紧张:
git rebase --edit-todo 这时候会一直处在这个编辑的模式里,我们可以回去继续编辑,修改完保存一下:
#!/bin/bash # 获取工单详情 for i in {1..100000} do curl --header "token:71e8e4dd40dd65f645ceb214397f578e" --url "192.168.31.117:9997/workorder/mine/orders?id=79" & echo"" done