>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000) 'Hi, Michael, you have $1000000.' ``` ## 有意思的数据类型 #### list ```python >>> fruits = ['apple', 'banana', 'orange'] >>> fruits ['apple', 'banana', 'orange'] >>> len(fruits) 3 >>> fruits[1] 'banana' >>> fruits[6] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range
倒数
1 2 3 4 5 6 7 8
>>> fruits[-1] 'orange' >>> fruits[-2] 'banana' >>> fruits[-6] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range
append() insert(1, ‘hi’) pop() list中的元素类型可以不同
tuple
不可更改的list,声明用() 当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来。 t = (1)定义的是自然数1,要定义成tuple需要加‘,’,规则。 t = (‘a’, ‘b’, [‘A’, ‘B’])其中的list是可变的。
>>> d = {'a': 1, 'b': 2, 'c': 3} >>> for key in d: ... print(key) ... a b c >>> for k, v in d.items(): ... print(k,v) ... a 1 b 2 c 3 >>> for value in d.values(): ... print(value) ... 1 2 3 >>> for i, value inenumerate(['A', 'B', 'C']): ... print(i, value) ... 0 A 1 B 2 C
列表生成式
1 2 3 4 5 6 7 8 9 10 11 12 13
>>> [x * x for x inrange(1, 11)] [1, 4, 9, 16, 25, 36, 49, 64, 81, 100] >>> [m + n for m in'ABC'for n in'XYZ'] ['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ'] >>> import os # 导入os模块,模块的概念后面讲到 >>> [d for d in os.listdir('.')] # os.listdir可以列出文件和目录 ['.emacs.d', '.ssh', '.Trash', 'Adlm', 'Applications', 'Desktop', 'Documents', 'Downloads', 'Library', 'Movies', 'Music', 'Pictures', 'Public', 'VirtualBox VMs', 'Workspace', 'XCode'] >>> d = {'x': 'A', 'y': 'B', 'z': 'C' } >>> [k + '=' + v for k, v in d.items()] ['y=B', 'x=A', 'z=C'] >>> L = ['Hello', 'World', 'IBM', 'Apple'] >>> [s.lower() for s in L] ['hello', 'world', 'ibm', 'apple']
生成器
1 2 3 4 5 6 7
deffib(max): n, a, b = 0, 0, 1 while n < max: yield b a, b = b, a + b n = n + 1 return'done'
/** * Field number for <code>get</code> and <code>set</code> indicating the * month. This is a calendar-specific value. The first month of * the year in the Gregorian and Julian calendars is * <code>JANUARY</code> which is 0; the last depends on the number * of months in a year. * * @see #JANUARY * @see #FEBRUARY * @see #MARCH * @see #APRIL * @see #MAY * @see #JUNE * @see #JULY * @see #AUGUST * @see #SEPTEMBER * @see #OCTOBER * @see #NOVEMBER * @see #DECEMBER * @see #UNDECIMBER */
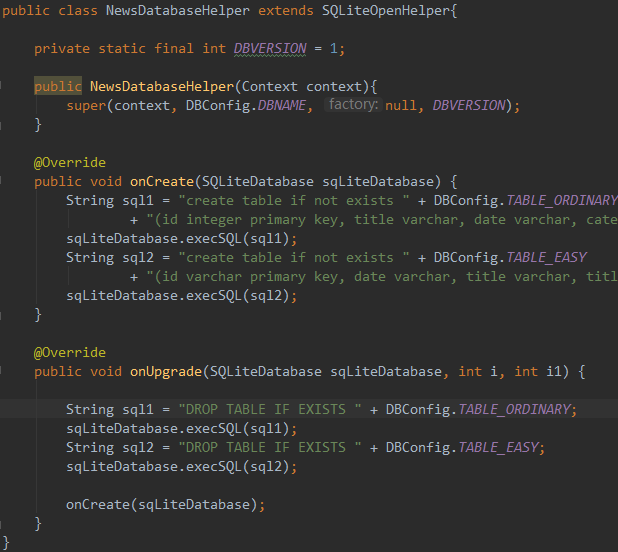
SQLiteOpenHelper versions the database files. The version number is the int argument passed to the constructor. In the database file, the version number is stored in PRAGMA user_version.
onCreate() is only run when the database file did not exist and was just created. If onCreate()returns successfully (doesn’t throw an exception), the database is assumed to be created with the requested version number. As an implication, you should not catch SQLExceptions in onCreate()yourself.
onUpgrade() is only called when the database file exists but the stored version number is lower than requested in constructor. The onUpgrade() should update the table schema to the requested version.
When changing the table schema in code (onCreate()), you should make sure the database is updated. Two main approaches:
Delete the old database file so that onCreate() is run again. This is often preferred at development time where you have control over the installed versions and data loss is not an issue. Some ways to to delete the database file:
Uninstall the application. Use the application manager or adb uninstall your.package.name from shell.
Clear application data. Use the application manager.
Increment the database version so that onUpgrade() is invoked. This is slightly more complicated as more code is needed.
For development time schema upgrades where data loss is not an issue, you can just use execSQL("DROP TABLE IF EXISTS <tablename>") in to remove your existing tables and call onCreate() to recreate the database.
For released versions, you should implement data migration in onUpgrade() so your users don’t lose their data.
I had the same error after renaming/refactoring. What I did was add the applicationId property attribute to my build.gradle file, and set its value to the application package. Like this:
The Jack toolchain is now considered deprecated according to this post and work is being done to natively support Java 8 features as part of the Android build system in the coming weeks according to the post.
The post also mentions that there should be little to no work migrating from Jack to the new method in case you still wanted to try enabling Java 8 features with Jack.
UPDATE 2 Preview Built-in Support
You can now try out the new built-in support for Java 8 using the latest Android Studio preview 2.4 preview 6.
For more information on how to enable it or migrate from Jack or Retrolambda see the documentation.
Error:(28, 0) Could not find method implementation() for arguments [com.android.support:appcompat-v7:25.3.1] on object of type org.gradle.api.internal.artifacts.dsl.dependencies.DefaultDependencyHandler. Please install the Android Support Repository from the Android SDK Manager. <a href="openAndroidSdkManager">Open Android SDK Manager</a>
* remote origin Fetch URL: [email protected]:xuchuanjun/NHKNews.git Push URL: [email protected]:xuchuanjun/NHKNews.git HEAD branch: master Remote branches: dev tracked master tracked Local branch configured for 'git pull': master merges with remote master Local refs configured for 'git push': dev pushes to dev (up to date) master pushes to master (up to date)