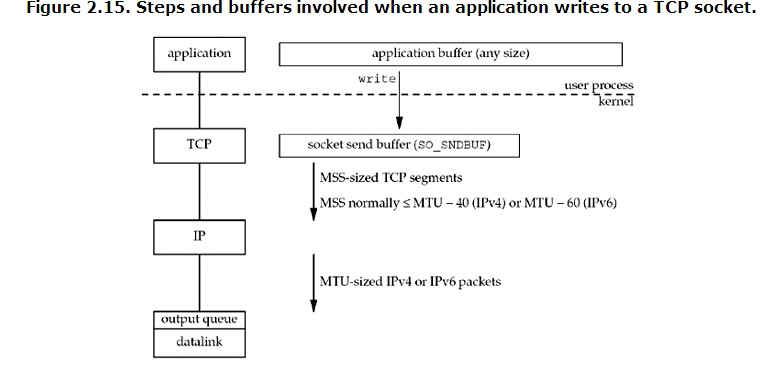
TCP是个流协议,流是一串没有界限的数据。TCP会根据TCP缓冲区的实际情况对包进行划分。因此造成一个完整的业务包,会被TCP分成多个包、把多个包封装成一个大的包进行发送。
粘包与拆包现象

服务端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包;
服务端一次接收到了两个数据包,D1和D2粘合在一起,被称为TCP粘包;
服务端分两次读取到了两个数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这被称为TCP拆包;
服务端分两次读取到了两个数据包,第一次读取到了D1包的部分内容D1_1,第二次读取到了D1包的剩余内容D1_2和D2包的整包。
产生原因
应用程序write写入的字节大小/大于套接口发送缓冲区大小;
进行MSS大小的TCP分段;
以太网帧的payload大于MTU进行IP分片。
对于Linux,发送缓冲区的默认值为:16384。可使用下面命令查看:
1 | 接收 |
数据来自百度云的云服务器:

对于MacOS,可参考:sysctl net.inet.tcp,但是好像没找到与linux类似的参数。
如何解决
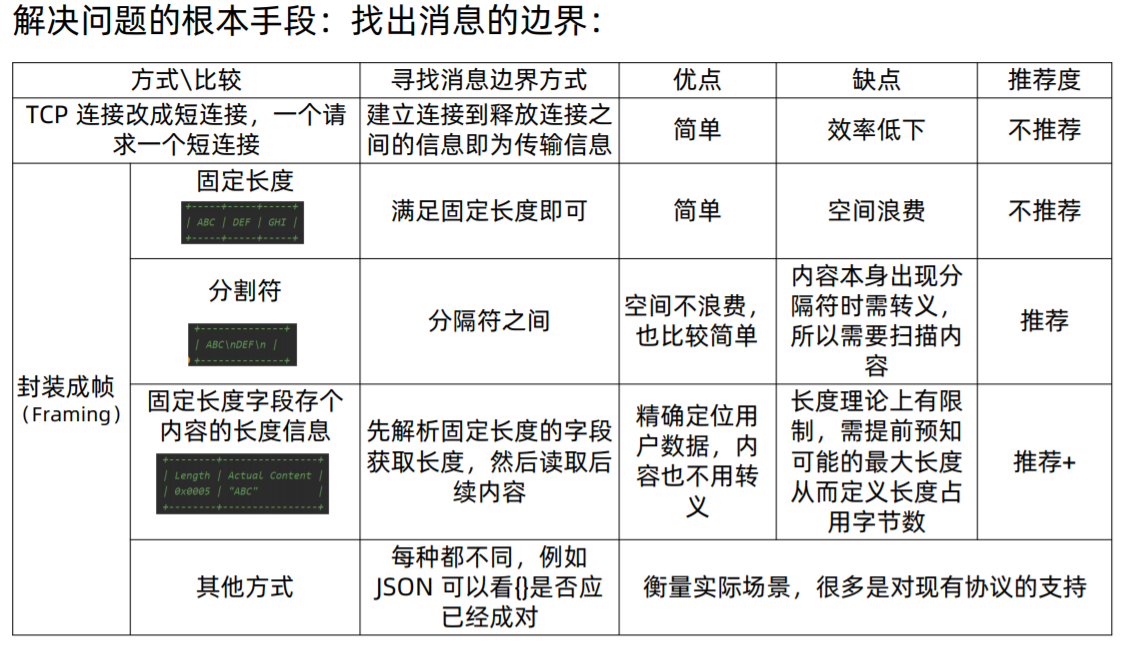
Netty如何解决
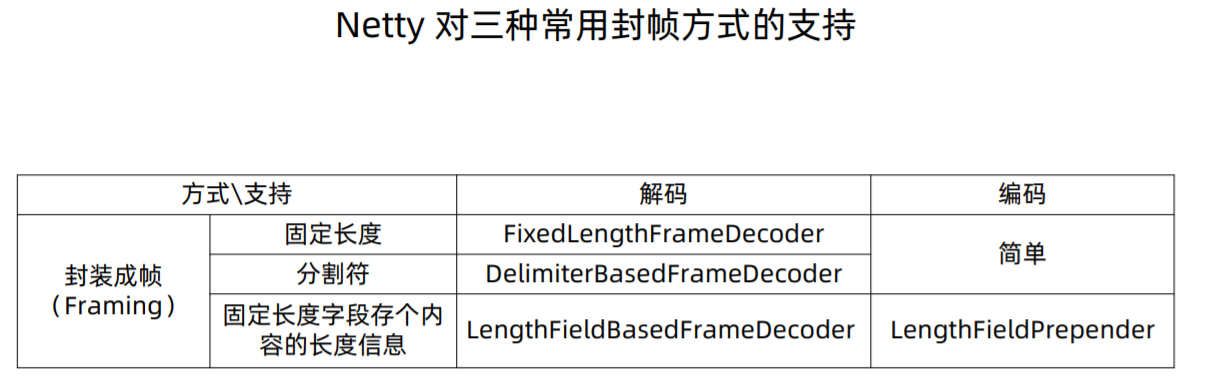
Netty中主要是在收到数据后,对数据进行处理解码处理时,根据不同的策略,进行了拆包操作,然后将得到的完整的业务数据包传递给下个处理逻辑。分割前后的逻辑主要在ByteToMessageDecoder这个类中。它的继承如下:
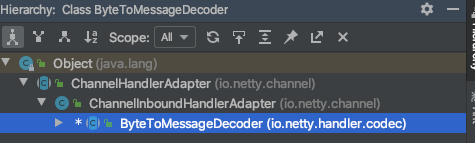
每次从TCP缓冲区读到数据都会调用其channelRead()方法。这个函数的处理逻辑是:
- 用累加器
cumulator将新读入的数据(ByteBuf)存储到cumulation中; - 调用解码器
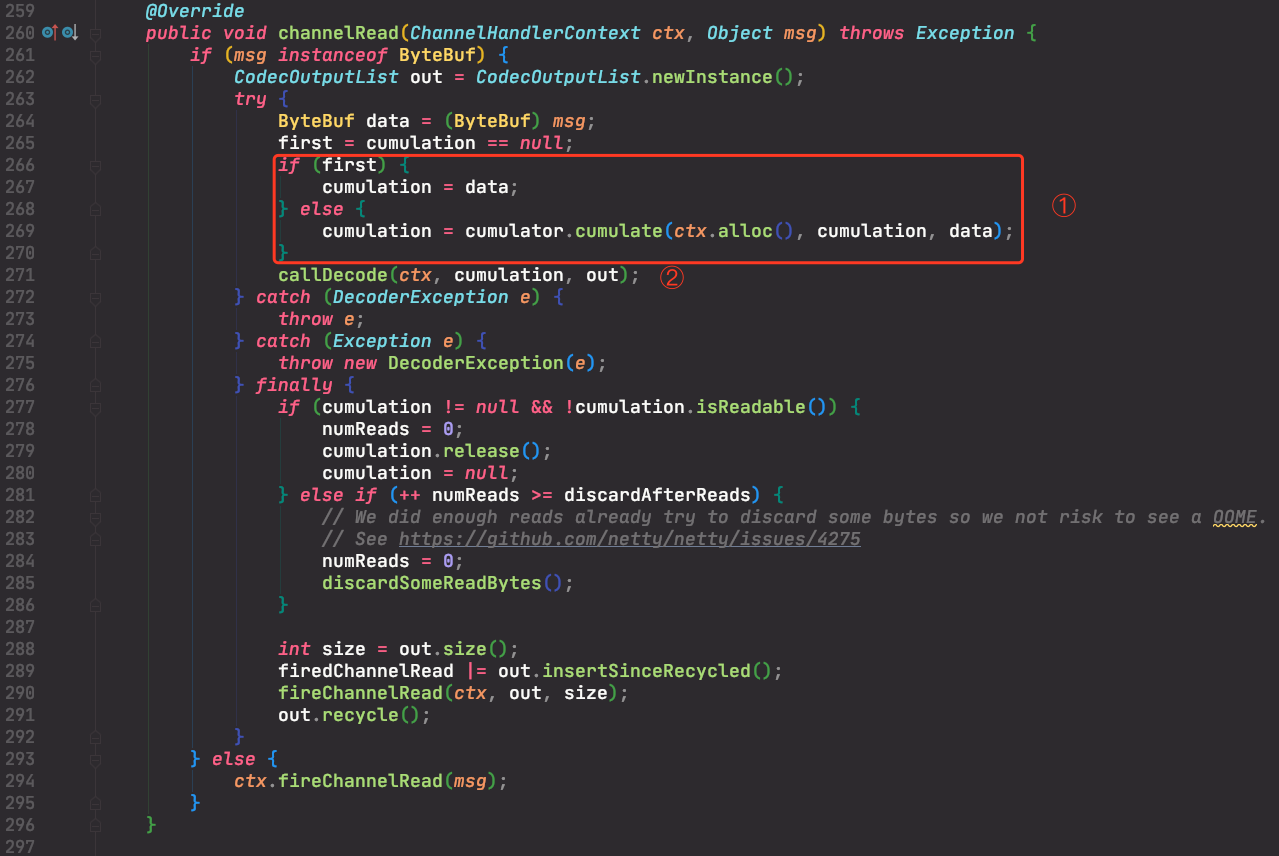
累加器
存在两个累加器,MERGE_CUMULATOR和COMPOSITE_CUMULATOR。默认的是前者,即:private Cumulator cumulator = MERGE_CUMULATOR;。
MERGE_CUMULATOR会先判断是否需要扩容,然后再将收到的msg拷贝到cumulation中。
1 | /** |
扩容的过程是先得到一个能够容纳下原数据+当前数据的收集器,然后将原数据和当前数据依次拷贝进入收集器,最后释放旧的收集器里面的数据。
1 | private static ByteBuf expandCumulation(ByteBufAllocator alloc, ByteBuf oldCumulation, ByteBuf in) { |
COMPOSITE_CUMULATOR是将每个新收到的消息,作为一个Component存储到收集器CompositeByteBuf中的components数组中。
1 | /** |
拆包解码流程
callDecode()方法中的decodeRemovalReentryProtection()将调用decode()方法,其中decode()是一个抽象方法,由子类去实现。主要的子类有:
FixedLengthFrameDecoder
里面有一个属性叫frameLength,用来表示消息的长度。
1 | A decoder that splits the received ByteBufs by the fixed number of bytes. For example, if you received the following four fragmented packets: |
流程也比较简单,收集器里面的数据长度够frameLength,就从收集器中截取frameLengthbyte,然后返回一个新的ByteBuf。
1 |
|
有一个问题,如果一次收到的数据长度为2 * frameLength,且这个数据是最后一个数据,那么是否存在解码出现异常的情况?
有一个循环
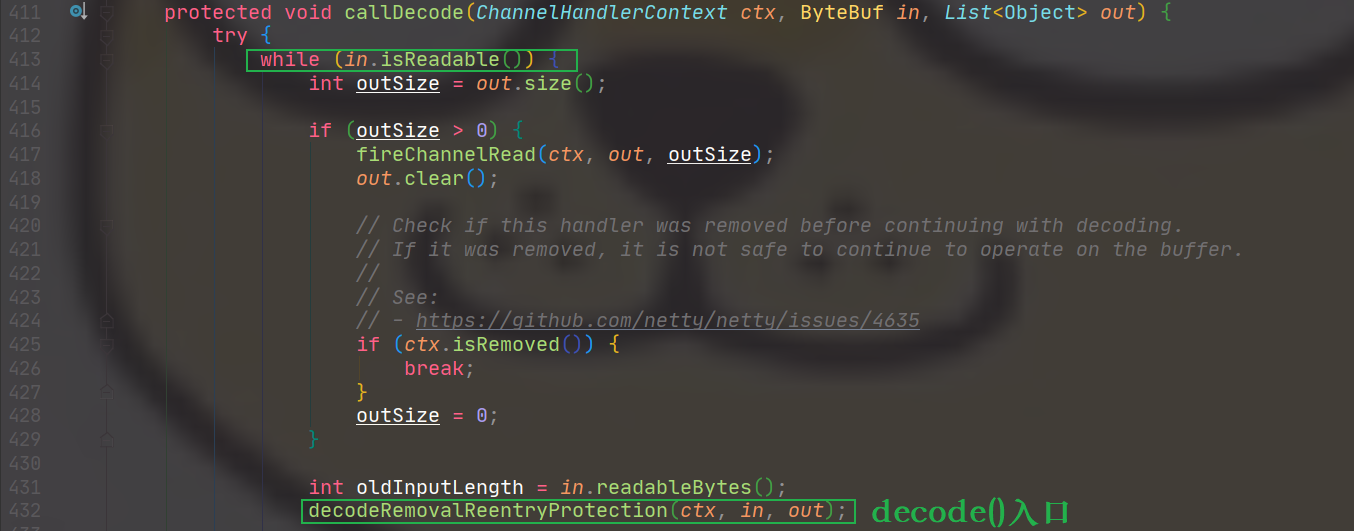
输入结束的时候再次调用解码

LineBasedFrameDecoder
流程是先找到当前消息中的换行符,存在且没有超过最大长度,返回解释到的数据。
DelimiterBasedFrameDecoder
根据特定的字符进行分割,其中如果分割符是行标志,会调用LineBasedFrameDecoder进行分割解码。
1 | // decode()方法中 |
判断分割符是否为行分割符的代码如下:
1 | private static boolean isLineBased(final ByteBuf[] delimiters) { |
因为分割字符可能是多个,当数据中存在多个分割字符的情况下,会用分割后得到的数据最短的那个分割字符。如下:
1 | // Try all delimiters and choose the delimiter which yields the shortest frame. |
For example, if you have the following data in the buffer:
+————–+
| ABC\nDEF\r\n |
+————–+
a DelimiterBasedFrameDecoder(Delimiters.lineDelimiter()) will choose ‘\n’ as the first delimiter and produce two frames:
+—–+—–+
| ABC | DEF |
+—–+—–+
rather than incorrectly choosing ‘\r\n’ as the first delimiter:
+———-+
| ABC\nDEF |
+———-+
LengthFieldBasedFrameDecoder
简而言之,就是在数据的头部,放一个专门的长度位,根据长度位来读取后面信息的内容。
这个类比较有意思,注释差不多占了2/5。主要的处理逻辑是decode(),但是这个方法100行都不到。注释主要解释了这个类里面几个参数的不同配置,产生不同的处理情况。
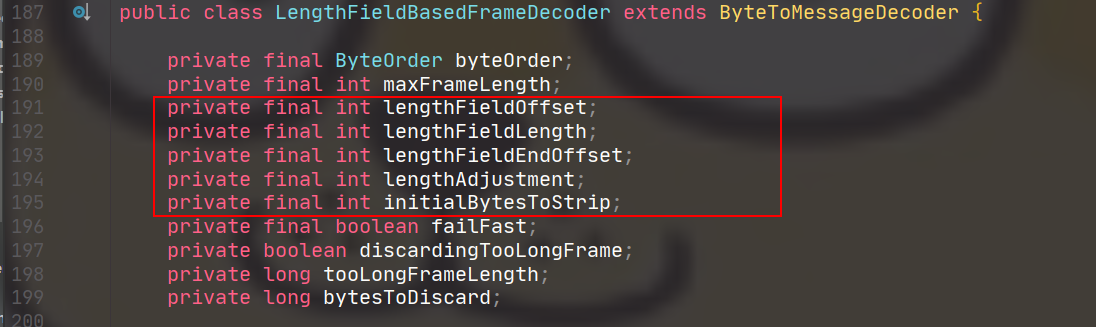
情况对应于下表:
| lengthFieldOffset | lengthFieldLength | lengthAdjustment | initialBytesToStrip | |
|---|---|---|---|---|
| 0x01 | 0 | 2 | 0 | 0 |
| 0x02 | 0 | 2 | 0 | 2 |
| 0x03 | 0 | 2 | -2 | 0 |
| 0x04 | 2 | 3 | 0 | 0 |
| 0x05 | 0 | 3 | 2 | 0 |
| 0x06 | 1 | 2 | 1 | 3 |
| 0x07 | 1 | 2 | -3 | 3 |
0x01
lengthFieldLength = 2表示长度位占头部的2 bytes,剩下的都是消息占位,也就是0x000C(12) + 2 = 14。
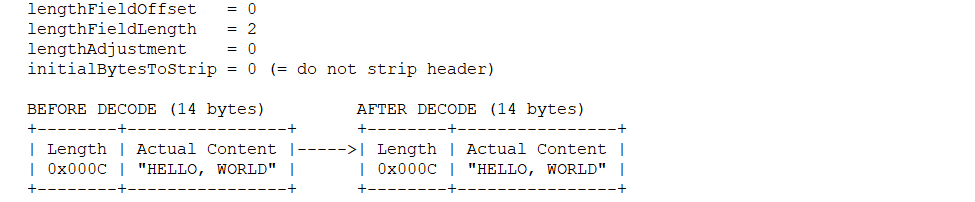
0x02
与0x01类似,只是多了initialBytesToStrip = 2,解码后的内容截取掉了头部的initialBytesToStrip位。也就是解码后的长度为14 - initialBytesToStrip = 12。
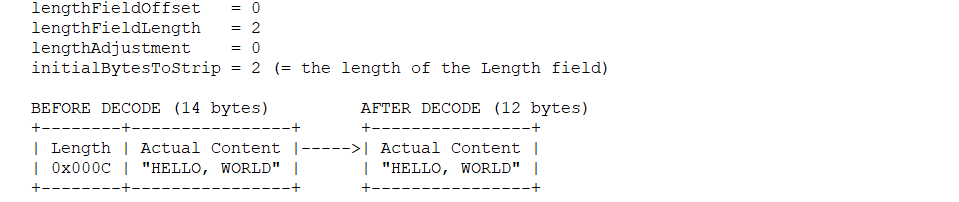
0x03
这种情况下,长度位的值,表示整个包的长度,包括长度位本身的长度。lengthAdjustment = -2表示要将长度位的值加上lengthAdjustment,作为消息的长度。

0x04
与0x01相比,多了个一个长度位的偏移量lengthFieldOffset。所以长度位的前面又可以放一些其他数据。也就是说,真正的消息是从lengthFieldOffset + lengthFieldLength后开始。

0x05
与0x03对比,只是lengthAdjustment的正负不同,也就意味着真实的消息是在长度位后面是有偏移的,而偏移出来的空间,可以用作存放另外一种数据类型。

0x06
在0x04、0x05的基础上,长度位多了偏移lengthFieldOffset,真实的消息的偏移又多加了一个lengthAdjustment,然后截掉了头部开始的initialBytesToStripbytes。

0x07
在0x06的基础上,lengthAdjustment变成负数了,与0x03的情况类似。

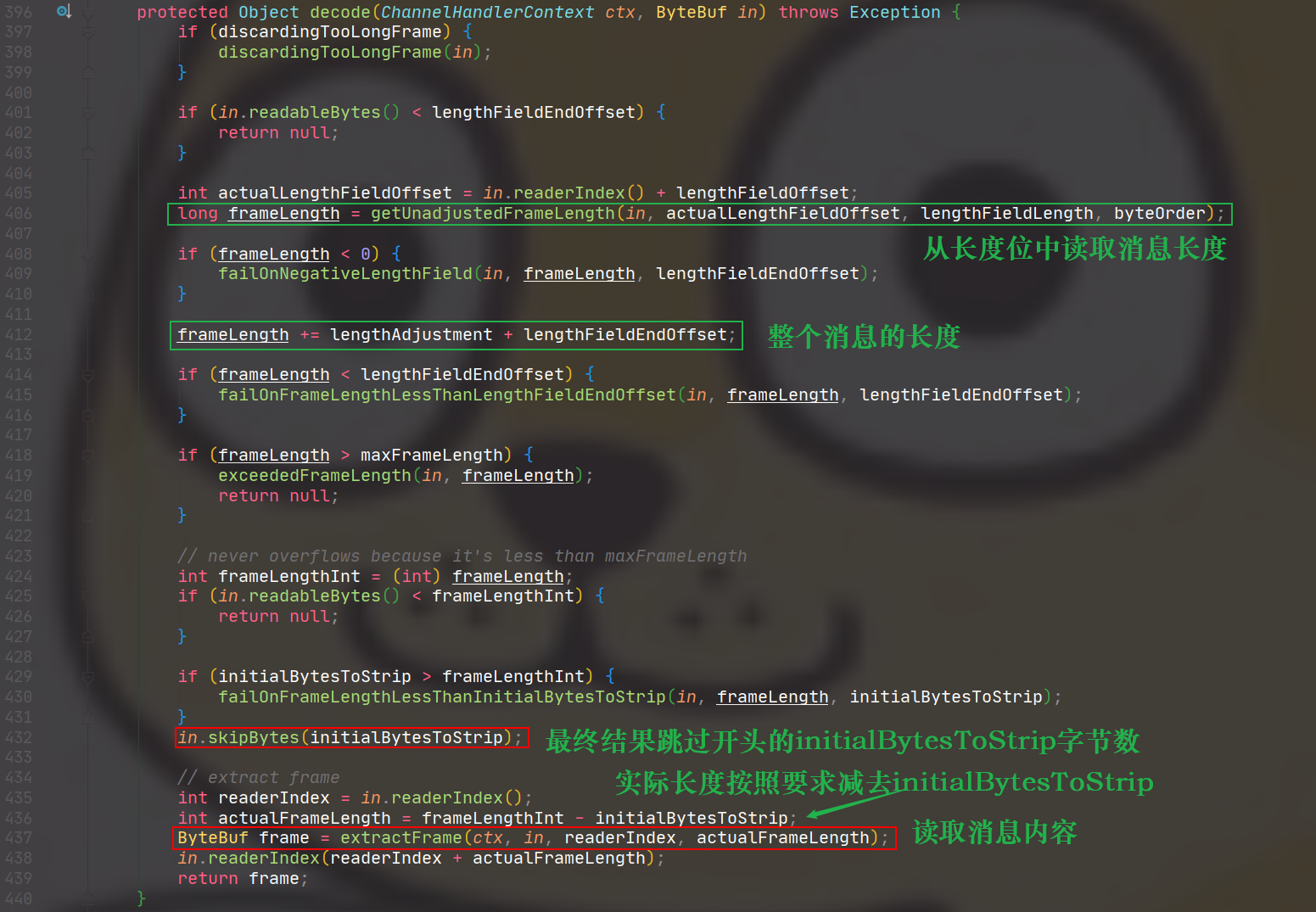
整体代码的流程
除去异常处理的情况,就是计算整个消息的长度,然后跳过要求跳过的字节数,再从ByteBuf中读取消息。如下:
参考:




