一个java -jar服务在被CI启动后,过一段时间,进程就被消失了,不见了。日志没有关于出错的相关信息。对日志中记录的最后一条请求,进行压力测试,但该进程却没有自己消失。个人觉得这个问题很有意思,但是我也明白,找到这其中的原因可能需要很长的时间。
Update(2019-3-15 )
最近公司的其他项目上,又遇到了一个进程老是无缘无故就挂的现象,按照之前的那种场景来排查,并没有发现有那种CI的出现。顿时又陷入了困境之中。不过我还是按部就班的做了三件事:
- 用root权限启动改服务
- 做好对jvm的监控
- 用strace对进程做好监控
顺便了解了一下strace的含义,发现其中的字段确实是有很大的意义。
监控命令如下:监控日志如下:1
nohup strace -T -tt -e trace=all -p \`pgrep -f algorithm-work-1.0.0.jar\ ` > trace.\`pgrep -f algorithm-work-1.0.0.jar\`.log &\
从上面看来,uid=0说明操作者是root,但是kill -9不一定有,不过至少是可以看出来是什么时候被干掉的。1
2
3
4
5
6
7
8webapp@ecs-f1c4-0003:/opt/webapp/logs$ cat trace.26077.log
strace: Process 26077 attached
11:22:43.117920 futex(0x7f631a5fb9d0, FUTEX_WAIT, 26078, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set) <1238.653416>
11:43:21.776222 --- SIGTERM {si_signo=SIGTERM, si_code=SI_USER, si_pid=26158, si_uid=0} ---
11:43:21.777278 futex(0x7f63199c0540, FUTEX_WAKE_PRIVATE, 1) = 1 <0.004217>
11:43:21.786583 rt_sigreturn({mask=[]}) = 202 <0.005049>
11:43:21.796220 futex(0x7f631a5fb9d0, FUTEX_WAIT, 26078, NULL <unfinished ...>
11:43:23.605244 +++ exited with 143 +++
转机
发现是被别人用来挖矿了==
详细的情况与下面链接的描述一模一样。本来还有一个进程叫做crond64,在top中看到占用的CPU非常高,各个核的都占到了90%+。执行的挖矿脚本的目录在~/.ttp下,打包好了,准备研究研究。
https://askubuntu.com/questions/1115770/crond64-tsm-virus-in-ubuntu
压力测试
首先想到的是:是不是某一个接口出现了问题,所以根据日志中所记录的最后一条请求,对其进行压力测试。脚本如下:
1 |
|
结果被认为遭到了ddos攻击,囧!
该服务进程扛过了这些请求,没有死亡。
排查CI
因为整个项目通过gitlab管理,而gitlab中有一项叫做CI,可以通过ci脚本来执行一些脚本达到发布、部署最新的服务到相应服务器上。这里面可能会存在问题,比如说,另外一个ci脚本在执行的时候,会把该服务的进程kill掉,只是会有这种可能,因为CI脚本大部分是通过copy的,但是可能性不高,因为所有的CI脚本都能够顺利执行,所以kill掉的肯定是自身服务的进程,不然CI脚本对应的服务可能起不来,但目前所有的CI脚本都能顺利执行完。但是还是去排查一下CI脚本,没毛病。
是谁kill掉了该进程?
这个进程消失的原因,可以想到的情况为:jvm崩溃、被操作系统的oom_killer杀掉、被某个脚本杀掉?
是否为操作系统所终结?
由于outofmemory被kill掉的进程,会在/var/log下的某个文件中留下最终的遗迹。但是在整个/var/log下、都没有搜索kill的痕迹,如下:

如果没有/var/log/messages这个文件,可以通过设置,将这个log文件开启。
root身份打开
/etc/rsyslog.d/50-default.conf把注释#去掉
1
2
3
4#*.=info;*.=notice;*.=warn;\
# auth,authpriv.none;\
# cron,daemon.none;\
# mail,news.none -/var/log/messages重启后ok
sudo restart rsyslog
并没有发现这个oom_killer的痕迹
JVM自己崩溃?
在该服务的启动参数中加入了对崩溃日志的指定:java -jar -Xms512m -Xmx512m -XX:MaxPermSize=126m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/webapp/xxx-server/ -XX:ErrorFile=/opt/webapp/xxx-server/hs_err_pid_%p.log xxx-server.jar
但是在该进程被终结后,并没有发现相应目录下的日志文件。所以这种情况下,同样也没有对其进行内存分析的先决条件、jdk自带的一系列工具并没有发挥出作用的余地。
到底是谁杀掉了这个进程?
使用nohup strace -T -tt -e trace=all -p 21715 > trace.log &监控该pid的情况,如果是被kill -9,会出现一个log,大致如下:
结果
通过strace命令的跟踪、最终发现trace.log的内容如下所示:
出现这个的原因基本上是两个、一个是人为的kill -9、或者就是被系统kill -9。系统杀掉该进程的原因、被逐一排除,结果只剩下人为的因素。关于人为的因素、首先查看命令,并没有相关的kill记录。然后发现开发环境与测试环境的该进程基本上同时挂掉、并且都点了这两个环境的某个CI,然后这两个环境上的该进程都挂掉了,因此基本断定是CI操作杀掉了该进程。
被杀掉的进程名字为:java -jar workorder-server.jar,通过CI发布&启动的进程名字为:java -jar order-server.jar。然后在点击order相关的CI时会执行如下操作:
1 | script: |
问题就在kill -9上面,pgrep查出来的进程号有两个,所以执行order相关的CI时,顺带也把workorder干掉了。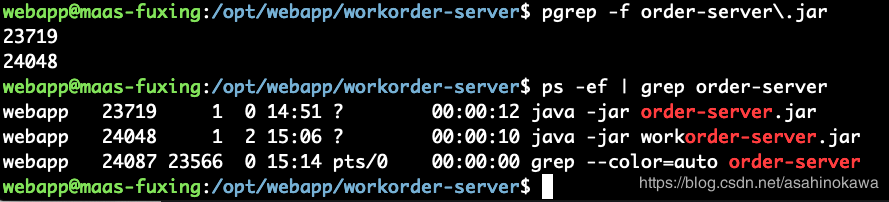
解决办法
修改shell语句,让pgrep order-server时,只显示出order-server的进程号即可。




