
Java中的线程池从精通到入门
说真的,我一直认为线程池很简单,也没去看过它的实现,大概了解过其中的原理,但是并未深入学习。一方面,了解过之后很长时间不去看,非常容易忘;另一方面,还是深入源码得到的信息才会比较深刻,还能避免背书式学习。继承结构说明在Executors中,有几个静态方法,预设了几个ThreadPoolExecuto
说真的,我一直认为线程池很简单,也没去看过它的实现,大概了解过其中的原理,但是并未深入学习。一方面,了解过之后很长时间不去看,非常容易忘;另一方面,还是深入源码得到的信息才会比较深刻,还能避免背书式学习。继承结构说明在Executors中,有几个静态方法,预设了几个ThreadPoolExecuto

这个问题遇到过很多次了,但是并不是说每次都很清楚。所以这次用golang的代码来实现一遍,加深理解与记忆。如果一个链表上不存在环,那么一定能够遍历完链表中所有的Node节点;如果存在环,那么可以想象成存在一个圆形操场。在一个圆里面,如果有两个人,行走的速度不一样,那么一定会有相遇的那一刻。最佳的解法

说句实话,我觉得Spring Cloud Gateway看起来很牛逼。首先是因为zuul的难产,颇有一种谁行谁上的感觉;再一个是WebFlux的加持,瞬间逼格就上去了。但是感觉苦逼的又回到了原点,因为WebFlux看简介是说基于Netty来实现的,绕来绕去又回到了Netty。言归正传,如果只是简单的
在前篇的基础上,对整个demo项目进行了重新的规划,包括模块名、包名的修改,以及对接口进行了调整,并将模块调用改成了OpenFeign,这个用起来更加方便,连RestTemplate都不需要使用即可完成调用。修改之后的demo项目整体架构如下:.├── module01│ ├── module0
nacos可提供动态服务发现、服务配置、服务元数据及流量管理。nacos集群搭建下载nacos:https://github.com/alibaba/nacos/releases/download/1.2.0/nacos-server-1.2.0.zip解压修改startup.cmd中的MODE为c

当服务端启动好了之后,也就是说,服务端已经在执行NioEventLoop的一个死循环方法run()中,一直轮询事件,并且此时的监听的事件为OP_ACCEPT。如果有新连接接入,那么首先会在上述的run()方法中触发... 收到新的连接 首先,服务端启动好了之后,会进入等待事件的状态,也就是调用JDK的NIO的API: // NioEventLoop.java -> run() if (!hasTasks()) { strategy = select(curDeadlineNanos); } // 核心是调用jdk的api selector.select(); 收到新的连接后,将会通过processSelectedKeys()进行处理,处理内容包括:创建、初始化NioSocketChannel。 // NioEventLoop.java private void processSelectedKeys() { if (selectedKeys != null) { processSelectedKeysOptimized(); } els
目前对于Netty的理解是:一套完善了Java NIO操作的框架,因为Netty的最底层还是调用jdk的nio相关的API,但是又在jdk的nio基础上做了很多的封装,并衍生出来了自己相关的概念。 服务启动的主线操作 以EchoServer为例,一条可参考的服务启动的主线操作如下: main thread 1. 创建selector 2. 创建serversocketchannel 3. 初始化serversocketchannel 4. 给serversocketchannel从bossgroup中选择一个NioEventLoop boss thread 1. 将serversocketchannel注册到选择的NioEventLoop的selector 2. 绑定地址启动 3. 注册接受连接事件(OP_ACCEPT)到selector上 对应到代码中的操作依次为: // 1. 创建selector Selector selector = sun.nio.ch.SelectorProviderImpl.openSelector(); // 2. 创建s
在正式开始Netty相关的学习之前,我决定还是要先回顾一下Java NIO,至少要对Java NIO相关的概念有一个了解,如Channel、ByteBuffer、Selector等。要自己动手写一写相关的demo实例、并且要尽可能地去了解其后面是如何实现的,也就是稍微看看相关jdk的源代码。 Java NIO 由以下几个核心部分组成:Buffer, Channel, Selector。传统的IO操作面向数据流,面向流 的 I/O 系统一次一个字节地处理数据,意味着每次从流中读一个或多个字节,直至完成,数据没有被缓存在任何地方;NIO操作面向缓冲区( 面向块),数据从Channel读取到Buffer缓冲区,随后在Buffer中处理数据。 Buffer 可以理解成煤矿里面挖煤的小车,把煤从井底运地面上面。它的属性与子类如下: Buffer是一个抽象类,继承自Object,拥有多个子类。此类在JDK源码中的注释如下: A container for data of a specific primitive type. A buffer is
Netty源代码导入IDEA时需要注意的地方 操作系统 64位 版本问题 官网上面说可以用64-bit OpenJDK 8 or above 。没有尝试OpenJDK,Oracle的JDK要1.8版本的。源码里面用到了Unsafe这个类,在jdk1.8之后的版本中被移除掉了。 IDEA的位数保持与操作系统位数相同 操作流程 1. 最好先设置好maven的镜像,导入时需要拉取很多jar包。 2. 打开IDEA,选择Import Project,选择好netty源码目录后再选择maven。 3. 等待Import完成,找到EchoServer,跑main方法,这时会报错,按照如下方式操作即可。 如果用的不是jdk1.8以上的jdk,会报Unsafe找不到,这种情况只需要在Project Structure中将Project SDK设置成jdk1.8即可。 如果是io.netty.util.collection.LongObjectMap找不到之类的错误,可以在netty-common模块中执行mvn clean compile,可以按下图方式进行操作该指令。
今天是2020年2月2号,感觉是一个比较特殊的日子,今天就来一篇记录型的博客吧,哈哈 起初很好奇,到底什么叫Reactor模式,这个名词感觉特别高大上,然后看描述,虽然能看懂描述,但是却不是特别明白到底是什么意思。这个时候主要是没有形成一种直观的印象,直观的印象就是比如说苹果,再给你看个实物,你就能把苹果与关联起来。在学习netty的时候,也遇到了Reactor模式,于是有了机会来形成一种比较直观的印象。 什么是Reactor模式? 定义看起来很抽象,但是其实很好理解。**它是一种开发模式,模式的核心流程:注册感兴趣的事件 -> 扫描是否有感兴趣的事件发生 -> 事件发生后做出相应的处理。**仅此而已。使用BIO开发的时候,每有一个新的请求过来了,都会新开一个线程,然后在新的线程里面进行业务处理,这种处理方式就是Thread-Per-Connection; 所以对应起来,使用NIO开发的时候,也有一个模式去处理相应的请求与业务逻辑,叫做Reactor模式。至于具体怎么做,也就是前面提到的Reactor模式的核心流程。 Reactor模式的3种版本 开始这个之前我有一
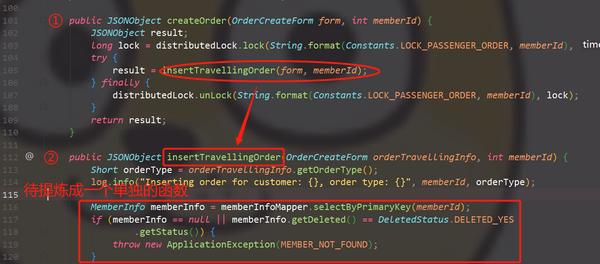
这份记录来自对项目中下单接口重构,详细记录了每一步操作、以及运用到的一些方法。力求能够最大程度将当时的过程展现出来。准备重构中的每次修改都需要进行测试,用来验证修改是否正确,因此单元测试是一个非常好的选择。单元测试单元测试中可以进行mock操作,从烦人的token中摆脱出来,做到在任何人的IDE里面
云主测试工具在做测试,通过日志发现,其搜寻的漏洞内容包括:SQL注入、XSS等。由于其请求的频率过高,以致于nginx做转发出现502错误,造成了宕机的假象。正对这种情况,想到了以下两种处理方式。wordpress拒绝请